소개
지금까지 웹에서의 오디오는 상당히 원시적이었으며, 최근까지도 Flash나 QuickTime과 같은 플러그인을 통해 제공되어야 했습니다. HTML5의
audio
요소가 도입되면서
기본적인 스트리밍 오디오 재생이 가능해졌습니다. 하지만 이로는 더 복잡한 오디오 애플리케이션을 처리하기에는 충분하지 않습니다. 정교한 웹 기반 게임이나 상호작용 애플리케이션을 위해서는
또 다른 솔루션이 필요합니다. 이 명세의 목표는 최신 게임 오디오 엔진에서 제공하는 기능뿐만 아니라, 현대 데스크톱 오디오 제작 애플리케이션에서 볼 수 있는 믹싱, 처리, 필터링 작업들을
포함하는 것입니다.
API는 다양한 사용 사례 [webaudio-usecases]를 염두에 두고 설계되었습니다. 이상적으로는 최적화된 C++ 엔진을 스크립트로 제어하여 브라우저에서 실행할 수 있는 어떤 사용 사례도 지원할 수 있어야 합니다. 물론, 최신 데스크톱 오디오 소프트웨어는 매우 고도화된 기능을 제공하며, 일부는 이 시스템으로 구축하기 어렵거나 불가능할 수도 있습니다. 애플의 Logic Audio와 같은 애플리케이션은 외부 MIDI 컨트롤러 지원, 임의의 플러그인 오디오 이펙트 및 신디사이저, 고도로 최적화된 디스크 직접 읽기/쓰기, 긴밀하게 통합된 타임 스트레칭 등 다양한 고급 기능을 탑재하고 있습니다. 그럼에도 불구하고, 제안된 시스템은 상당히 복잡한 게임과 상호작용 애플리케이션(음악 애플리케이션 포함)을 충분히 지원할 수 있으며, WebGL에서 제공하는 고급 그래픽 기능과도 훌륭하게 결합될 수 있습니다. API는 추후 더 고급 기능을 확장할 수 있도록 설계되었습니다.
기능
API가 지원하는 주요 기능은 다음과 같습니다:
-
모듈형 라우팅을 통한 간단하거나 복잡한 믹싱/이펙트 아키텍처.
-
내부 처리를 위한 32비트 부동 소수점 사용으로 높은 다이내믹 레인지 제공.
-
샘플 단위 정확도의 일정 사운드 재생 및 저지연으로 드럼 머신이나 시퀀서 등 매우 높은 리듬 정밀도를 요구하는 음악 애플리케이션을 지원. 이펙트의 동적 생성도 포함됩니다.
-
오디오 파라미터 자동화 (엔벨로프, 페이드인/페이드아웃, 그래뉼러 이펙트, 필터 스윕, LFO 등).
-
오디오 스트림의 채널을 유연하게 처리하여 분리 및 병합 가능.
-
audio또는videomedia element의 오디오 소스 처리. -
MediaStream을 통한 라이브 오디오 입력 처리,getUserMedia()와 함께 사용. -
WebRTC와의 통합
-
MediaStreamTrackAudioSourceNode와 [webrtc]를 통해 원격 피어로부터 받은 오디오 처리. -
MediaStreamAudioDestinationNode와 [webrtc]를 통해 생성/처리된 오디오 스트림을 원격 피어로 전송.
-
-
오디오 스트림 합성 및 스크립트를 통한 직접 처리.
-
공간화 오디오로 다양한 3D 게임 및 몰입형 환경 지원:
-
패닝 모델: equalpower, HRTF, 패스스루
-
거리 감쇠(Attenuation)
-
사운드 콘(Sound Cones)
-
차단/가림(Obstruction / Occlusion)
-
소스/리스너 기반
-
-
광범위한 선형 이펙트를 위한 컨볼루션 엔진, 특히 고품질의 룸 이펙트. 가능한 효과 예시는 다음과 같습니다:
-
작은/큰 방
-
대성당
-
콘서트홀
-
동굴
-
터널
-
복도
-
숲
-
원형극장
-
문을 통해 들리는 먼 방의 소리
-
극단적인 필터
-
이상한 역효과
-
극단적인 콤 필터 이펙트
-
-
믹스 전체 제어 및 음색 개선을 위한 다이내믹스 컴프레션
-
효율적인 바이쿼드 필터로 로우패스, 하이패스 및 기타 일반 필터 제공.
-
왜곡 및 기타 비선형 이펙트를 위한 웨이브쉐이핑 효과
-
오실레이터
모듈형 라우팅
모듈형 라우팅은 서로 다른 AudioNode
객체 간 임의의 연결을 허용합니다. 각 노드는 입력(inputs) 및/또는 출력(outputs)을 가질 수 있습니다.
소스 노드(source node)는 입력이 없고
출력이 하나입니다.
목적지 노드(destination
node)는 입력이 하나이고 출력이 없습니다. 필터와 같은 다른 노드는 소스와 목적지 노드 사이에 배치될 수 있습니다. 개발자는 두 객체를 연결할 때 저수준 스트림 포맷에 대해
걱정할 필요가 없으며, 알아서 적절하게 처리됩니다.
예를 들어, 모노 오디오 스트림이 스테레오 입력에 연결되면 적절하게 좌우 채널로 믹싱됩니다.
가장 단순한 경우, 하나의 소스를 바로 출력으로 라우팅할 수 있습니다.
모든 라우팅은 단일 AudioContext
내의 단일 AudioDestinationNode에서
발생합니다:
이 단순 라우팅을 설명하는 예시로, 하나의 사운드를 재생하는 간단한 코드입니다:
const context= new AudioContext(); function playSound() { const source= context. createBufferSource(); source. buffer= dogBarkingBuffer; source. connect( context. destination); source. start( 0 ); }
다음은 세 개의 소스와 컨볼루션 리버브, 그리고 최종 출력 단계에 다이내믹스 컴프레서를 포함한 더 복잡한 예시입니다:
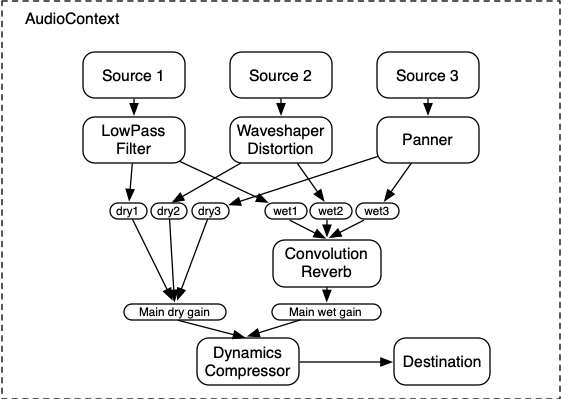
let context; let compressor; let reverb; let source1, source2, source3; let lowpassFilter; let waveShaper; let panner; let dry1, dry2, dry3; let wet1, wet2, wet3; let mainDry; let mainWet; function setupRoutingGraph() { context= new AudioContext(); // 이펙트 노드 생성 lowpassFilter= context. createBiquadFilter(); waveShaper= context. createWaveShaper(); panner= context. createPanner(); compressor= context. createDynamicsCompressor(); reverb= context. createConvolver(); // 메인 wet/dry 생성 mainDry= context. createGain(); mainWet= context. createGain(); // 최종 컴프레서를 목적지에 연결 compressor. connect( context. destination); // 메인 dry/wet를 컴프레서에 연결 mainDry. connect( compressor); mainWet. connect( compressor); // 리버브를 메인 wet에 연결 reverb. connect( mainWet); // 소스 생성 source1= context. createBufferSource(); source2= context. createBufferSource(); source3= context. createOscillator(); source1. buffer= manTalkingBuffer; source2. buffer= footstepsBuffer; source3. frequency. value= 440 ; // source1 연결 dry1= context. createGain(); wet1= context. createGain(); source1. connect( lowpassFilter); lowpassFilter. connect( dry1); lowpassFilter. connect( wet1); dry1. connect( mainDry); wet1. connect( reverb); // source2 연결 dry2= context. createGain(); wet2= context. createGain(); source2. connect( waveShaper); waveShaper. connect( dry2); waveShaper. connect( wet2); dry2. connect( mainDry); wet2. connect( reverb); // source3 연결 dry3= context. createGain(); wet3= context. createGain(); source3. connect( panner); panner. connect( dry3); panner. connect( wet3); dry3. connect( mainDry); wet3. connect( reverb); // 소스 시작 source1. start( 0 ); source2. start( 0 ); source3. start( 0 ); }
모듈형 라우팅은 AudioNode의 출력을
AudioParam
파라미터에 연결하여
다른 AudioNode의
동작을 제어할 수도 있습니다. 이 경우,
노드의 출력은 입력 신호가 아닌 변조 신호로 작동할 수 있습니다.
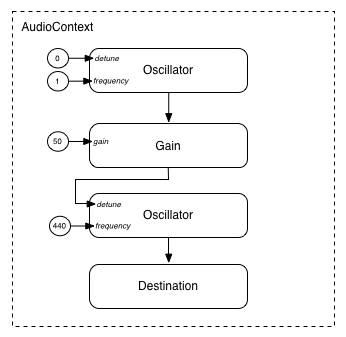
function setupRoutingGraph() { const context= new AudioContext(); // 변조 신호를 공급하는 저주파 오실레이터 생성 const lfo= context. createOscillator(); lfo. frequency. value= 1.0 ; // 변조될 고주파 오실레이터 생성 const hfo= context. createOscillator(); hfo. frequency. value= 440.0 ; // 변조 신호의 진폭(Amplitude)을 결정하는 게인 노드 생성 const modulationGain= context. createGain(); modulationGain. gain. value= 50 ; // 그래프 구성 및 오실레이터 시작 lfo. connect( modulationGain); modulationGain. connect( hfo. detune); hfo. connect( context. destination); hfo. start( 0 ); lfo. start( 0 ); }
API 개요
정의된 인터페이스는 다음과 같습니다:
-
AudioContext 인터페이스는
AudioNode들 간의 연결을 나타내는 오디오 신호 그래프를 포함합니다. -
AudioNode인터페이스는 오디오 소스, 오디오 출력, 그리고 중간 처리 모듈을 나타냅니다.AudioNode들은 모듈형 방식으로 동적으로 서로 연결될 수 있습니다.AudioNode들은AudioContext의 컨텍스트 내에 존재합니다. -
AnalyserNode인터페이스는, 음악 비주얼라이저나 기타 시각화 애플리케이션에서 사용되는AudioNode입니다. -
AudioBuffer인터페이스는, 메모리에 상주하는 오디오 자산을 다루기 위한 것으로, 일회성 사운드 또는 긴 오디오 클립을 나타낼 수 있습니다. -
AudioBufferSourceNode인터페이스는,AudioNode로서 AudioBuffer에서 오디오를 생성합니다. -
AudioDestinationNode인터페이스는,AudioNode의 하위 클래스로 모든 렌더링된 오디오의 최종 목적지를 나타냅니다. -
AudioParam인터페이스는,AudioNode의 볼륨 등 개별 동작을 제어합니다. -
AudioListener인터페이스는,PannerNode와 함께 공간화에 사용됩니다. -
AudioWorklet인터페이스는 스크립트를 직접 이용해 오디오를 처리할 수 있는 커스텀 노드를 생성하는 팩토리 역할을 합니다. -
AudioWorkletGlobalScope인터페이스는 AudioWorkletProcessor 처리 스크립트가 실행되는 컨텍스트입니다. -
AudioWorkletNode인터페이스는, AudioWorkletProcessor에서 처리되는AudioNode를 나타냅니다. -
AudioWorkletProcessor인터페이스는 오디오 워커 내부의 단일 노드 인스턴스를 나타냅니다. -
BiquadFilterNode인터페이스는, 흔히 사용되는 저차 필터(예시:)-
로우패스
-
하이패스
-
밴드패스
-
로우 셸프
-
하이 셸프
-
피킹
-
노치
-
올패스
-
-
ChannelMergerNode인터페이스는, 여러 오디오 스트림의 채널을 하나의 오디오 스트림으로 결합하는AudioNode입니다. -
ChannelSplitterNode인터페이스는, 라우팅 그래프 내 오디오 스트림의 개별 채널에 접근하는AudioNode입니다. -
ConstantSourceNode인터페이스는,AudioNode로 명목상 일정한 출력값을 생성하며,AudioParam으로 값 자동화가 가능합니다. -
ConvolverNode인터페이스는, 콘서트홀 등의 실시간 선형 이펙트를 적용하는AudioNode입니다. -
DynamicsCompressorNode인터페이스는, 다이내믹스 컴프레션에 사용되는AudioNode입니다. -
IIRFilterNode인터페이스는, 범용 IIR 필터를 위한AudioNode입니다. -
MediaElementAudioSourceNode인터페이스는,AudioNode로서audio,video등 미디어 요소의 오디오 소스입니다. -
MediaStreamAudioSourceNode인터페이스는, 라이브 오디오 입력이나 원격 피어의MediaStream에서 오디오 소스를 제공하는AudioNode입니다. -
MediaStreamTrackAudioSourceNode인터페이스는,AudioNode로서MediaStreamTrack의 오디오 소스입니다. -
MediaStreamAudioDestinationNode인터페이스는,AudioNode로서MediaStream에 오디오를 출력하여 원격 피어로 전송합니다. -
PannerNode인터페이스는, 3D 공간에서 오디오의 위치를 지정하는AudioNode입니다. -
PeriodicWave인터페이스는OscillatorNode에서 사용할 사용자 지정 주기 파형을 명시합니다. -
OscillatorNode인터페이스는, 주기적 파형을 생성하는AudioNode입니다. -
StereoPannerNode인터페이스는, 스테레오 스트림에서 오디오 입력을 equal-power 방식으로 위치시키는AudioNode입니다. -
WaveShaperNode인터페이스는, 왜곡 및 기타 미묘한 웜 효과를 위한 비선형 웨이브쉐이핑을 적용하는AudioNode입니다.
Web Audio API에서 폐지(deprecated)되었지만, 대체 기능의 구현 경험을 위해 아직 제거되지 않은 기능도 있습니다:
-
ScriptProcessorNode인터페이스는, 스크립트를 직접 사용하여 오디오를 생성하거나 처리하는AudioNode입니다. -
AudioProcessingEvent인터페이스는ScriptProcessorNode객체에서 사용되는 이벤트 타입입니다.
1. 오디오 API
1.1.
BaseAudioContext
인터페이스
이 인터페이스는 AudioNode 객체들과
그 연결을 나타냅니다.
신호를 AudioDestinationNode로
임의 라우팅할 수 있습니다.
노드는 컨텍스트에서 생성되며 서로 연결됩니다.
BaseAudioContext는
직접 인스턴스화되지 않고,
구체적 인터페이스인 AudioContext
(실시간 렌더링용)와 OfflineAudioContext
(오프라인 렌더링용)에서 확장됩니다.
BaseAudioContext는
내부 슬롯 [[pending promises]]로
생성되며, 이는 초기에는 빈 순서 리스트의 promise입니다.
각 BaseAudioContext는
고유한
미디어 요소 이벤트 태스크 소스를 갖습니다.
또한 BaseAudioContext는
여러 프라이빗 슬롯 [[rendering thread state]]와
[[control thread state]]를 가지며,
이 값은 AudioContextState에서
가져오고, 둘 다 초기값은 "suspended" 입니다.
그리고 프라이빗 슬롯 [[render quantum size]]도 가지며, 이는
부호 없는 정수입니다.
enum {AudioContextState "suspended" ,"running" ,"closed" };
| 열거값 | 설명 |
|---|---|
"suspended"
| 이 컨텍스트는 현재 일시 정지됨(컨텍스트 시간이 진행되지 않으며, 오디오 하드웨어가 꺼지거나 해제될 수 있음). |
"running"
| 오디오가 처리되고 있음. |
"closed"
| 이 컨텍스트는 해제되어 더 이상 오디오를 처리할 수 없습니다. 모든 시스템 오디오 리소스가 해제됨. |
enum {AudioContextRenderSizeCategory "default" ,"hardware" };
| 열거형 설명 | |
|---|---|
"default"
| AudioContext의 렌더 퀀텀 크기는 128 프레임의 기본값입니다. |
"hardware"
|
User-Agent가 현재 설정에 가장 적합한 렌더 퀀텀 크기를 선택합니다.
참고: 이는 호스트 정보를 노출하며, 핑거프린팅에 사용될 수 있습니다. |
callback DecodeErrorCallback =undefined (DOMException );error callback DecodeSuccessCallback =undefined (AudioBuffer ); [decodedData Exposed =Window ]interface BaseAudioContext :EventTarget {readonly attribute AudioDestinationNode destination ;readonly attribute float sampleRate ;readonly attribute double currentTime ;readonly attribute AudioListener listener ;readonly attribute AudioContextState state ;readonly attribute unsigned long renderQuantumSize ; [SameObject ,SecureContext ]readonly attribute AudioWorklet audioWorklet ;attribute EventHandler onstatechange ;AnalyserNode createAnalyser ();BiquadFilterNode createBiquadFilter ();AudioBuffer createBuffer (unsigned long ,numberOfChannels unsigned long ,length float );sampleRate AudioBufferSourceNode createBufferSource ();ChannelMergerNode createChannelMerger (optional unsigned long numberOfInputs = 6);ChannelSplitterNode createChannelSplitter (optional unsigned long numberOfOutputs = 6);ConstantSourceNode createConstantSource ();ConvolverNode createConvolver ();DelayNode createDelay (optional double maxDelayTime = 1.0);DynamicsCompressorNode createDynamicsCompressor ();GainNode createGain ();IIRFilterNode createIIRFilter (sequence <double >,feedforward sequence <double >);feedback OscillatorNode createOscillator ();PannerNode createPanner ();PeriodicWave createPeriodicWave (sequence <float >,real sequence <float >,imag optional PeriodicWaveConstraints = {});constraints ScriptProcessorNode createScriptProcessor (optional unsigned long bufferSize = 0,optional unsigned long numberOfInputChannels = 2,optional unsigned long numberOfOutputChannels = 2);StereoPannerNode createStereoPanner ();WaveShaperNode createWaveShaper ();Promise <AudioBuffer >decodeAudioData (ArrayBuffer ,audioData optional DecodeSuccessCallback ?,successCallback optional DecodeErrorCallback ?); };errorCallback
1.1.1. 속성
audioWorklet, 타입 AudioWorklet, 읽기 전용-
Worklet객체에 접근할 수 있게 해주며, [HTML]과AudioWorklet에 정의된 알고리즘을 통해AudioWorkletProcessor클래스 정의를 포함한 스크립트를 가져올 수 있습니다. currentTime, 타입 double, 읽기 전용-
이 값은 컨텍스트 렌더링 그래프가 가장 최근에 처리한 오디오 블록에서 마지막 샘플-프레임 바로 다음에 해당하는 초 단위 시간입니다. 렌더링 그래프가 아직 오디오 블록을 처리하지 않았다면
currentTime값은 0입니다.currentTime의 시간 좌표계에서 0 값은 그래프가 처음 처리한 첫 블록의 첫 번째 샘플-프레임을 의미합니다. 이 좌표계에서 경과 시간은BaseAudioContext가 생성한 오디오 스트림의 경과 시간과 일치합니다. 이는 시스템의 다른 시계와 동기화되지 않을 수 있습니다. (OfflineAudioContext의 경우, 스트림이 실제 장치에서 재생되지 않으므로 실시간과의 근사치조차 없습니다.)Web Audio API에서 모든 예약된 시간은
currentTime값을 기준으로 합니다.BaseAudioContext가 "running" 상태일 때, 이 속성 값은 단조롭게 증가하며, 렌더링 스레드에 의해 일정하게 갱신됩니다. 이는 하나의 렌더 퀀텀에 해당합니다. 따라서 실행 중인 컨텍스트에서는currentTime이 오디오 블록을 처리하면서 꾸준히 증가하며, 항상 다음에 처리될 오디오 블록의 시작 시간을 나타냅니다. 또한, 현재 상태에서 예약된 변경이 적용될 수 있는 가장 이른 시간입니다.currentTime은 반환되기 전에 제어 스레드에서 원자적으로 읽어야 합니다. destination, 타입 AudioDestinationNode, 읽기 전용-
모든 오디오의 최종 목적지를 나타내는 입력이 하나인
AudioDestinationNode입니다. 보통 실제 오디오 하드웨어를 의미합니다.AudioNode로 오디오를 렌더링하는 모든 노드는 직접 또는 간접적으로destination에 연결됩니다. listener, 타입 AudioListener, 읽기 전용-
3D 공간화에 사용되는
AudioListener입니다. onstatechange, 타입 EventHandler-
AudioContext의 상태가 변경되었을 때(즉, 해당 promise가 resolve될 때)
BaseAudioContext에 디스패치되는 이벤트의 이벤트 핸들러를 설정하는 속성입니다. 이 이벤트 핸들러의 이벤트 타입은statechange입니다.Event인터페이스를 사용하는 이벤트가 이벤트 핸들러에 디스패치되며, 이벤트 핸들러는 AudioContext의 상태를 직접 조회할 수 있습니다. 새로 생성된 AudioContext는 항상suspended상태로 시작하며, 상태가 변경될 때마다 statechange 이벤트가 발생합니다. 이 이벤트는complete이벤트가 발생하기 전에 먼저 발생합니다. sampleRate, 타입 float, 읽기 전용-
BaseAudioContext가 오디오를 처리하는 샘플 레이트(초당 샘플-프레임 수)입니다. 컨텍스트 내 모든AudioNode들이 이 샘플 레이트로 동작한다고 가정합니다. 이 조건에서는 샘플 레이트 변환기나 "varispeed" 프로세서는 실시간 처리에서는 지원되지 않습니다. 나이퀴스트 주파수(Nyquist frequency)는 이 샘플 레이트 값의 절반입니다. state, 타입 AudioContextState, 읽기 전용-
BaseAudioContext의 현재 상태를 설명합니다. 이 속성을 가져오면[[control thread state]]슬롯의 내용을 반환합니다. renderQuantumSize, 타입 unsigned long, 읽기 전용-
이 속성을 가져오면
[[render quantum size]]슬롯의 값을 반환합니다.
1.1.2. 메서드
createAnalyser()-
팩토리 메서드로,
AnalyserNode를 생성합니다.파라미터 없음.반환 타입:AnalyserNode createBiquadFilter()-
팩토리 메서드로,
BiquadFilterNode를 생성합니다. 2차 필터로, 여러 일반적인 필터 타입 중 하나로 구성할 수 있습니다.파라미터 없음.반환 타입:BiquadFilterNode createBuffer(numberOfChannels, length, sampleRate)-
지정된 크기의 AudioBuffer를 생성합니다. 버퍼의 오디오 데이터는 0으로 초기화(무음)됩니다. 파라미터가 음수, 0, 또는 허용 범위를 벗어나면
NotSupportedError예외가 반드시 발생해야 합니다.BaseAudioContext.createBuffer() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 numberOfChannelsunsigned long✘ ✘ 버퍼에 포함될 채널 수를 결정합니다. 구현체는 최소 32채널을 지원해야 합니다. lengthunsigned long✘ ✘ 샘플 프레임 단위로 버퍼의 크기를 결정합니다. 최소값은 1이어야 합니다. sampleRatefloat✘ ✘ 버퍼 내 선형 PCM 오디오 데이터의 샘플 레이트(초당 샘플 프레임 수)를 설명합니다. 구현체는 최소 8000~96000의 샘플레이트 범위를 지원해야 합니다. 반환 타입:AudioBuffer createBufferSource()-
팩토리 메서드로,
AudioBufferSourceNode를 생성합니다.파라미터 없음.반환 타입:AudioBufferSourceNode createChannelMerger(numberOfInputs)-
팩토리 메서드로,
ChannelMergerNode를 생성합니다. 채널 병합을 나타냅니다.IndexSizeError예외는numberOfInputs가 1 미만이거나 지원 채널 수를 초과하면 반드시 발생해야 합니다.BaseAudioContext.createChannelMerger(numberOfInputs) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 numberOfInputsunsigned long✘ ✔ 입력 수를 결정합니다. 최대 32까지 지원해야 하며, 지정하지 않으면 6이 사용됩니다.반환 타입:ChannelMergerNode createChannelSplitter(numberOfOutputs)-
팩토리 메서드로,
ChannelSplitterNode를 생성합니다. 채널 분리 기능을 나타냅니다.IndexSizeError예외는numberOfOutputs가 1 미만이거나 지원 채널 수를 초과하면 반드시 발생해야 합니다.BaseAudioContext.createChannelSplitter(numberOfOutputs) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 numberOfOutputsunsigned long✘ ✔ 출력 수를 결정합니다. 최대 32까지 지원해야 하며, 지정하지 않으면 6이 사용됩니다.반환 타입:ChannelSplitterNode createConstantSource()-
팩토리 메서드로,
ConstantSourceNode를 생성합니다.파라미터 없음.반환 타입:ConstantSourceNode createConvolver()-
팩토리 메서드로,
ConvolverNode를 생성합니다.파라미터 없음.반환 타입:ConvolverNode createDelay(maxDelayTime)-
팩토리 메서드로,
DelayNode를 생성합니다. 초기 기본 delay time 값은 0초입니다.BaseAudioContext.createDelay(maxDelayTime) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 maxDelayTimedouble✘ ✔ 딜레이 라인에 허용되는 최대 지연 시간(초)을 지정합니다. 지정된 경우, 반드시 0 초과 3분 미만이어야 하며, 그렇지 않으면 NotSupportedError예외가 발생해야 합니다. 지정하지 않으면1이 사용됩니다.반환 타입:DelayNode createDynamicsCompressor()-
팩토리 메서드로,
DynamicsCompressorNode를 생성합니다.파라미터 없음.반환 타입:DynamicsCompressorNode createGain()-
파라미터 없음.반환 타입:
GainNode createIIRFilter(feedforward, feedback)-
BaseAudioContext.createIIRFilter() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 feedforwardsequence<double>✘ ✘ IIR 필터의 전달 함수(transfer function)에 대한 feedforward(분자) 계수 배열입니다. 이 배열의 최대 길이는 20입니다. 모든 값이 0이면 InvalidStateError예외가 반드시 발생해야 합니다.NotSupportedError예외가 배열 길이가 0이거나 20 초과이면 반드시 발생해야 합니다.feedbacksequence<double>✘ ✘ IIR 필터의 전달 함수(transfer function)에 대한 feedback(분모) 계수 배열입니다. 이 배열의 최대 길이는 20입니다. 첫 번째 요소가 0이면 InvalidStateError예외가 반드시 발생해야 합니다.NotSupportedError예외가 배열 길이가 0이거나 20 초과이면 반드시 발생해야 합니다.반환 타입:IIRFilterNode createOscillator()-
팩토리 메서드로,
OscillatorNode를 생성합니다.파라미터 없음.반환 타입:OscillatorNode createPanner()-
팩토리 메서드로,
PannerNode를 생성합니다.파라미터 없음.반환 타입:PannerNode createPeriodicWave(real, imag, constraints)-
팩토리 메서드로,
PeriodicWave를 생성합니다.이 메서드를 호출할 때, 다음 과정을 실행합니다:-
만약
real과imag의 길이가 다르면,IndexSizeError예외가 반드시 발생해야 합니다. -
o를
PeriodicWaveOptions타입의 새 객체로 만듭니다. -
o의
disableNormalization속성을, 팩토리 메서드에 전달된constraints의disableNormalization값으로 설정합니다. -
이 팩토리 메서드가 호출된
BaseAudioContext와 o를 인수로 하여 새PeriodicWavep를 생성합니다. -
p를 반환합니다.
BaseAudioContext.createPeriodicWave() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 realsequence<float>✘ ✘ 코사인(cosine) 파라미터 시퀀스입니다. 자세한 설명은 real생성자 인수 참조.imagsequence<float>✘ ✘ 사인(sine) 파라미터 시퀀스입니다. 자세한 설명은 imag생성자 인수 참조.constraintsPeriodicWaveConstraints✘ ✔ 지정하지 않으면 웨이브폼이 정규화됩니다. 지정된 경우, constraints값에 따라 웨이브폼이 정규화됩니다.반환 타입:PeriodicWave -
createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels)-
팩토리 메서드로,
ScriptProcessorNode를 생성합니다. 이 메서드는 폐지(deprecated)되었으며,AudioWorkletNode로 대체될 예정입니다. 스크립트를 사용해 직접 오디오를 처리할ScriptProcessorNode를 생성합니다.IndexSizeError예외는bufferSize또는numberOfInputChannels또는numberOfOutputChannels값이 유효 범위를 벗어나면 반드시 발생해야 합니다.numberOfInputChannels과numberOfOutputChannels모두 0인 경우는 유효하지 않습니다. 이 경우IndexSizeError예외가 반드시 발생해야 합니다.BaseAudioContext.createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 bufferSizeunsigned long✘ ✔ bufferSize파라미터는 샘플 프레임 단위로 버퍼 크기를 결정합니다. 값을 전달하지 않거나 0이면, 구현체가 환경에 맞는 최적의 버퍼 크기를 선택하며, 노드의 전체 수명 동안 일정한 2의 거듭제곱 값이 유지됩니다. 명시적으로 bufferSize 값을 지정할 경우, 반드시 다음 값 중 하나여야 합니다: 256, 512, 1024, 2048, 4096, 8192, 16384. 이 값은audioprocess이벤트가 발생하는 빈도와 호출마다 처리해야 할 샘플 프레임 수를 결정합니다.bufferSize값이 낮을수록 지연(latency)이 낮아집니다. 값이 높으면 오디오 끊김(glitches)을 방지하는 데 필요할 수 있습니다. 구현체가 latency와 오디오 품질을 균형 있게 선택하도록, 명시적으로 버퍼 크기를 지정하지 않는 것이 권장됩니다. 지정 값이 위의 허용 값(2의 거듭제곱)이 아니면,IndexSizeError예외가 반드시 발생해야 합니다.numberOfInputChannelsunsigned long✘ ✔ 이 파라미터는 노드의 입력 채널 수를 결정합니다. 기본값은 2입니다. 최대 32까지 반드시 지원해야 합니다. NotSupportedError채널 수가 지원되지 않을 경우 반드시 발생해야 합니다.numberOfOutputChannelsunsigned long✘ ✔ 이 파라미터는 노드의 출력 채널 수를 결정합니다. 기본값은 2입니다. 최대 32까지 반드시 지원해야 합니다. NotSupportedError채널 수가 지원되지 않을 경우 반드시 발생해야 합니다.반환 타입:ScriptProcessorNode createStereoPanner()-
팩토리 메서드로,
StereoPannerNode를 생성합니다.파라미터 없음.반환 타입:StereoPannerNode createWaveShaper()-
팩토리 메서드로,
WaveShaperNode를 생성합니다. 비선형 왜곡 효과를 나타냅니다.파라미터 없음.반환 타입:WaveShaperNode decodeAudioData(audioData, successCallback, errorCallback)-
ArrayBuffer에 포함된 오디오 파일 데이터를 비동기적으로 디코딩합니다.ArrayBuffer는, 예를 들어XMLHttpRequest의response속성에서responseType을"arraybuffer"로 설정한 뒤 불러올 수 있습니다. 오디오 파일 데이터는audio요소가 지원하는 형식이어야 합니다.decodeAudioData()에 전달된 버퍼는 [mimesniff]에서 설명한 sniffing 방식으로 콘텐츠 타입이 결정됩니다.이 함수는 주로 promise 반환값으로 사용하지만, 콜백 파라미터는 레거시 지원을 위해 제공됩니다.
손상된 파일이 있을 경우 구현체가 저자에게 경고하도록 권장합니다. throw하는 것은 breaking change이므로 불가능합니다.
참고: 압축 오디오 데이터 바이트 스트림이 손상되었더라도 디코딩이 진행될 수 있을 경우, 구현체는 개발자 도구 등으로 저자에게 경고하는 것이 권장됩니다.decodeAudioData가 호출되면, 다음 단계는 반드시 제어 스레드에서 실행되어야 합니다:-
this의 관련 전역 객체의 연관 Document가 완전히 활성화(fully active)가 아니라면, 거부된 promise를 반환하며, "
InvalidStateError"DOMException을 사용합니다. -
promise를 새 Promise로 생성합니다.
-
audioData가 detached라면, 다음 단계 실행:-
promise를
[[pending promises]]에 추가합니다. -
detach 작업을
audioDataArrayBuffer에 대해 실행합니다. 이 작업에서 예외가 발생하면 3단계로 점프. -
디코딩 작업을 다른 스레드에 큐잉합니다.
-
-
그 외에는 다음 에러 단계 실행:
-
error를
DataCloneError로 지정합니다. -
promise를 error로 거부하고,
[[pending promises]]에서 제거합니다. -
미디어 요소 태스크를 큐잉하여
errorCallback을 error와 함께 호출합니다.
-
-
promise를 반환합니다.
디코딩 작업을 다른 스레드에 큐잉할 때는, 반드시 제어 스레드나 렌더링 스레드가 아닌디코딩 스레드(decoding thread)에서 다음 단계가 실행되어야 합니다.참고: 여러
디코딩 스레드(decoding thread)가 병렬로 실행되어decodeAudioData의 여러 호출을 처리할 수 있습니다.-
can decode를 true로 초기화된 불리언 플래그로 둡니다.
-
audioDataMIME 타입을 MIME Sniffing § 6.2 오디오/비디오 타입 패턴 매칭을 사용해 판별 시, 타입 패턴 매칭 알고리즘이undefined를 반환하면, can decode를 false로 설정합니다. -
만약 can decode가 true라면,
audioData를 선형 PCM(linear PCM)으로 디코딩을 시도합니다. 실패 시 can decode를 false로 설정합니다.미디어 바이트 스트림에 여러 오디오 트랙이 있으면, 첫 번째 트랙만 선형 PCM(linear pcm)으로 디코딩합니다.
참고: 디코딩 과정에 더 많은 제어가 필요하다면 [WEBCODECS]를 사용할 수 있습니다.
-
만약 can decode가
false라면, 미디어 요소 태스크를 큐잉해서 다음 단계 실행:-
error는 이름이
EncodingError인DOMException입니다.-
promise를 error로 거부하고,
[[pending promises]]에서 제거합니다.
-
-
errorCallback이 존재하면 error와 함께errorCallback을 호출합니다.
-
-
그 외에는:
-
디코딩된 선형 PCM(linear PCM) 오디오 데이터를 결과로 받아,
BaseAudioContext의 샘플레이트와 다를 경우 샘플레이트 변환을 수행합니다. -
미디어 요소 태스크를 큐잉해서 다음 단계 실행:
-
최종 결과(샘플레이트 변환을 포함할 수 있음)가 담긴
AudioBuffer를 buffer로 지정합니다. -
promise를 buffer로 resolve합니다.
-
successCallback이 존재하면 buffer와 함께successCallback을 호출합니다.
-
-
BaseAudioContext.decodeAudioData() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 audioDataArrayBuffer✘ ✘ 압축된 오디오 데이터가 담긴 ArrayBuffer. successCallbackDecodeSuccessCallback?✔ ✔ 디코딩이 완료되면 호출되는 콜백 함수. 이 콜백의 단일 인수는 디코딩된 PCM 오디오 데이터를 나타내는 AudioBuffer입니다. errorCallbackDecodeErrorCallback?✔ ✔ 오디오 파일 디코딩 에러 발생 시 호출되는 콜백 함수. 반환 타입:Promise<AudioBuffer> -
1.1.3. 콜백 DecodeSuccessCallback()
파라미터
decodedData, 타입AudioBuffer-
디코딩된 오디오 데이터가 담긴 AudioBuffer입니다.
1.1.4. 콜백 DecodeErrorCallback()
파라미터
error, 타입DOMException-
디코딩 중 발생한 오류입니다.
1.1.5. 생명주기
AudioContext가
생성되면,
더 이상 재생할 사운드가 없거나 페이지가 사라질 때까지 계속 소리를 재생합니다.
1.1.6. 인트로스펙션 또는 직렬화 프리미티브의 부재
Web Audio API는 오디오 소스 스케줄링에 fire-and-forget 방식을 취합니다. 즉, 소스 노드는 AudioContext의
생명주기 동안 각 노트마다 생성되고, 그래프에서 명시적으로 제거되지 않습니다. 이는 직렬화 API와 호환되지 않으며, 직렬화할 수 있는 안정적인 노드 집합이 존재하지 않기 때문입니다.
또한, 인트로스펙션 API가 있으면 콘텐츠 스크립트가 가비지 컬렉션(GC)을 관찰할 수 있게 됩니다.
1.1.7. BaseAudioContext
하위 클래스와 연관된 시스템 리소스
AudioContext와
OfflineAudioContext
하위 클래스는 리소스 소모가 큰 객체로 간주해야 합니다. 이러한 객체를 생성하면, 우선순위가 높은 스레드를 생성하거나 저지연 시스템 오디오 스트림을 사용할 수 있으며, 둘 다 에너지 소비에
영향을 줄 수 있습니다. 보통 하나의 문서에 AudioContext를
여러 개 생성할 필요는 없습니다.
BaseAudioContext
하위 클래스를 생성하거나 다시 시작(resume)하면 해당 컨텍스트에 시스템 리소스 할당이 필요합니다. AudioContext의
경우, 시스템 오디오 스트림 생성도 필요합니다. 이러한 작업은 컨텍스트가 연결된 오디오 그래프에서 출력을 생성하기 시작하면 완료됩니다.
또한, user-agent는 구현에 따라 AudioContext의
최대 개수를 정의할 수 있으며,
최대 개수 초과 시 새로운 AudioContext를
생성하려고 하면 NotSupportedError가
발생합니다.
suspend와
close는
저자가 시스템 리소스(스레드, 프로세스, 오디오 스트림 등)를 해제할 수 있게 해줍니다. BaseAudioContext를
일시정지(suspend)하면 일부 리소스를 해제할 수 있으며, resume을
호출해 나중에 다시 동작할 수 있습니다.
AudioContext를
닫으면 모든 리소스가 해제되어, 더 이상 사용할 수 없으며 다시 시작(resume)할 수 없습니다.
참고: 예를 들어, 오디오 콜백이 정기적으로 실행되기를 기다리거나, 하드웨어가 처리 준비될 때까지 대기해야 할 수도 있습니다.
1.2. AudioContext
인터페이스
이 인터페이스는 AudioDestinationNode가
실시간 출력 장치에 라우팅되어 사용자에게 신호를 전달하는 오디오 그래프를 나타냅니다. 대부분의 사용 사례에서는 문서당 하나의 AudioContext만
사용합니다.
enum {AudioContextLatencyCategory "balanced" ,"interactive" ,"playback" };
| 열거값 | 설명 |
|---|---|
"balanced"
| 오디오 출력 지연(latency)과 전력 소비를 균형 있게 조절합니다. |
"interactive"
| 끊김 없이 가능한 가장 낮은 오디오 출력 지연(latency)을 제공합니다. 기본값입니다. |
"playback"
| 오디오 출력 지연보다 지속적인 재생과 중단 없는 플레이백을 우선시합니다. 전력 소비가 가장 낮습니다. |
enum {AudioSinkType "none" };
| 열거값 | 설명 |
|---|---|
"none"
| 오디오 그래프가 오디오 출력 장치를 통해 재생되지 않고 처리됩니다. |
[Exposed =Window ]interface AudioContext :BaseAudioContext {constructor (optional AudioContextOptions contextOptions = {});readonly attribute double baseLatency ;readonly attribute double outputLatency ; [SecureContext ]readonly attribute (DOMString or AudioSinkInfo )sinkId ; [SecureContext ]readonly attribute AudioRenderCapacity renderCapacity ;attribute EventHandler onsinkchange ;attribute EventHandler onerror ;AudioTimestamp getOutputTimestamp ();Promise <undefined >resume ();Promise <undefined >suspend ();Promise <undefined >close (); [SecureContext ]Promise <undefined >((setSinkId DOMString or AudioSinkOptions ));sinkId MediaElementAudioSourceNode createMediaElementSource (HTMLMediaElement );mediaElement MediaStreamAudioSourceNode createMediaStreamSource (MediaStream );mediaStream MediaStreamTrackAudioSourceNode createMediaStreamTrackSource (MediaStreamTrack );mediaStreamTrack MediaStreamAudioDestinationNode createMediaStreamDestination (); };
AudioContext가
시작 가능(allowed to
start)하다고 하는 것은 user agent가 컨텍스트 상태를 "suspended"
에서
"running"으로
전환하는 것을 허용하는 경우를 의미합니다.
User agent는 이 초기 전환을 허용하지 않을 수 있으며,
AudioContext의
관련 전역 객체(relevant global object)가 sticky activation 상태일 때만 허용할 수 있습니다.
AudioContext에는
다음과 같은 내부 슬롯이 있습니다:
[[suspended by user]]-
컨텍스트가 사용자 코드에 의해 일시정지되었는지를 나타내는 boolean 플래그입니다. 초기값은
false입니다. [[sink ID]]-
현재 오디오 출력 장치의 식별자 또는 정보를 각각 나타내는
DOMString또는AudioSinkInfo입니다. 초기값은""이며, 이는 기본 오디오 출력 장치를 의미합니다. [[pending resume promises]]-
Promise를resume()호출로 생성한 대기 중인 순서 리스트로 저장합니다. 초기값은 빈 리스트입니다.
1.2.1. 생성자
AudioContext(contextOptions)-
현재 설정 객체의 관련 전역 객체의 연결된 Document가 완전히 활성화(fully active)가 아니면, "
InvalidStateError" 예외를 발생시키고, 이 단계들을 중단합니다.AudioContext를 생성할 때, 다음 단계를 실행합니다:-
context를 새
AudioContext객체로 만듭니다. -
[[control thread state]]를 context에서suspended로 설정합니다. -
[[rendering thread state]]를 context에서suspended로 설정합니다. -
messageChannel을 새
MessageChannel로 만듭니다. -
controlSidePort를 messageChannel의
port1의 값으로 설정합니다. -
renderingSidePort를 messageChannel의
port2의 값으로 설정합니다. -
serializedRenderingSidePort를 StructuredSerializeWithTransfer(renderingSidePort, « renderingSidePort »)의 결과로 설정합니다.
-
이
audioWorklet의port를 controlSidePort로 설정합니다. -
제어 메시지 큐잉를 통해 AudioContextGlobalScope에 MessagePort 설정을 serializedRenderingSidePort로 실행합니다.
-
contextOptions가 주어진 경우, 다음 하위 단계를 수행합니다:-
sinkId가 지정된 경우, sinkId를contextOptions.의 값으로 두고, 다음 하위 단계 실행:sinkId-
sinkId와
[[sink ID]]가 모두DOMString타입이고, 서로 같다면 이 하위 단계를 중단합니다. -
sinkId가
AudioSinkOptions타입이고,[[sink ID]]가AudioSinkInfo타입이며, sinkId의type과type이 같다면 이 하위 단계를 중단합니다. -
validationResult를 sink identifier validation 의 반환값으로 설정합니다.
-
validationResult가
DOMException타입이면, 해당 예외를 발생시키고 이 하위 단계를 중단합니다. -
sinkId가
DOMString타입이면,[[sink ID]]를 sinkId로 설정하고 이 하위 단계를 중단합니다. -
sinkId가
AudioSinkOptions타입이면,[[sink ID]]를 sinkId의type값으로 생성한 새AudioSinkInfo인스턴스로 설정합니다.
-
-
내부 latency를
contextOptions.값에 따라 설정합니다. 상세 내용은latencyHintlatencyHint참조. -
contextOptions.가 지정된 경우, context의sampleRatesampleRate를 해당 값으로 설정합니다. 그렇지 않으면 다음 하위 단계 실행:-
sinkId가 빈 문자열이거나
AudioSinkOptions타입이면, 기본 출력 장치의 샘플레이트를 사용합니다. 이 하위 단계를 중단합니다. -
sinkId가
DOMString타입이면, 해당 sinkId가 식별하는 출력 장치의 샘플레이트를 사용합니다. 이 하위 단계를 중단합니다.
contextOptions.가 출력 장치의 샘플레이트와 다르면, user agent는 반드시 오디오 출력을 출력 장치의 샘플레이트와 맞도록 리샘플링해야 합니다.sampleRate참고: 리샘플링이 필요하면 context의 latency에 큰 영향이 있을 수 있습니다.
-
-
-
context를 반환합니다.
처리를 시작하라는 제어 메시지를 전송하는 것은 다음 단계를 실행하는 것을 의미합니다:-
document를 현재 설정 객체의 관련 전역 객체의 연결된 Document로 설정합니다.
-
[[sink ID]]를 기반으로, 렌더링에 사용할 오디오 출력 장치를 위한 시스템 리소스 할당을 시도합니다:-
빈 문자열일 경우 기본 오디오 출력 장치.
-
[[sink ID]]가 식별하는 오디오 출력 장치.
-
리소스 할당에 실패하면, 다음 단계 실행:
-
document가
"speaker-selection"으로 식별되는 기능을 사용할 수 없으면, 이 하위 단계 중단. -
미디어 요소 태스크 큐잉을 통해
error이벤트를AudioContext에 발생시키고, 이후 단계 중단.
-
-
-
this
[[rendering thread state]]를running으로 설정합니다. 대상AudioContext입니다. -
미디어 요소 태스크 큐잉을 통해 다음 단계 실행:
-
state속성을AudioContext에서 "running"으로 설정합니다. -
statechange 이벤트를
AudioContext에 발생시킵니다.
-
참고:
AudioContext가 인수 없이 생성되고 리소스 할당에 실패하는 경우, User-Agent는 오디오 출력 장치를 에뮬레이션하는 메커니즘을 사용하여 오디오 그래프를 조용히 렌더링 시도할 수 있습니다.제어 메시지를 통해MessagePort를AudioWorkletGlobalScope에 설정하는 것은, 렌더링 스레드에서, 전달된 serializedRenderingSidePort로 다음 단계를 실행하는 것을 의미합니다:-
deserializedPort를 StructuredDeserialize(serializedRenderingSidePort, 현재 Realm)의 결과로 설정합니다.
-
port를 deserializedPort로 설정합니다.
AudioContext.constructor(contextOptions) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 contextOptionsAudioContextOptions✘ ✔ AudioContext생성 방식을 제어하는 사용자 지정 옵션입니다. -
1.2.2. 속성
baseLatency, 타입 double, 읽기 전용-
이 값은
AudioContext가AudioDestinationNode에서 오디오를 오디오 서브시스템으로 전달할 때 소모되는 처리 지연(초)을 나타냅니다.AudioDestinationNode의 출력과 오디오 하드웨어 사이의 추가 처리, 또는 오디오 그래프 자체에서 발생하는 지연은 포함되지 않습니다.예시로, 오디오 컨텍스트가 44.1 kHz에서 기본 렌더 퀀텀 크기로 실행되고,
AudioDestinationNode가 내부적으로 더블 버퍼링을 구현하여 각 렌더 퀀텀마다 오디오를 처리 및 출력할 수 있다면, 처리 지연은 \((2\cdot128)/44100 = 5.805 \mathrm{ ms}\) 정도입니다. outputLatency, 타입 double, 읽기 전용-
오디오 출력 지연의 초 단위 추정값입니다. 즉, UA가 호스트 시스템에 버퍼 재생을 요청한 시점과, 버퍼의 첫 샘플이 실제 오디오 출력 장치에서 처리되는 시점 사이의 간격입니다. 스피커나 헤드폰처럼 음향 신호를 생성하는 장치의 경우, 이 시점은 샘플의 소리가 실제로 발생하는 시점을 의미합니다.
outputLatency속성 값은 플랫폼 및 연결된 오디오 출력 장치 하드웨어에 따라 달라집니다.outputLatency값은 컨텍스트가 실행 중이거나 연결된 오디오 출력 장치가 변경될 때 변할 수 있습니다. 정확한 동기화가 필요할 때 이 값을 자주 쿼리하는 것이 좋습니다. renderCapacity, 타입 AudioRenderCapacity, 읽기 전용-
이 속성은
AudioContext와 연관된AudioRenderCapacity인스턴스를 반환합니다. sinkId, 타입(DOMString or AudioSinkInfo), 읽기 전용-
이 속성은
[[sink ID]]내부 슬롯의 값을 반환합니다. 이 속성은 업데이트 시 캐시되며, 캐싱 후에는 동일한 객체를 반환합니다. onsinkchange, 타입 EventHandler-
setSinkId()에서 발생하는 이벤트 핸들러입니다. 이 핸들러의 이벤트 타입은sinkchange입니다. 출력 장치 변경이 완료되면 이 이벤트가 디스패치됩니다.참고:
AudioContext생성 시 초기 장치 선택에는 이 이벤트가 발생하지 않습니다. 초기 출력 장치 준비 여부는statechange이벤트로 확인할 수 있습니다. onerror, 타입 EventHandler-
Event가AudioContext에서 디스패치될 때 사용하는 이벤트 핸들러입니다. 이 핸들러의 이벤트 타입은error이며, user agent가 다음과 같은 경우에 이벤트를 디스패치할 수 있습니다:-
선택한 오디오 장치 초기화 및 활성화에 실패한 경우
-
AudioContext와 연결된 오디오 출력 장치가 컨텍스트가running상태일 때 분리된 경우 -
운영체제에서 오디오 장치 오류가 보고된 경우
-
1.2.3. 메서드
close()-
AudioContext를 닫고, 사용 중인 시스템 리소스를 해제합니다. 이는AudioContext가 생성한 모든 객체를 자동으로 해제하지는 않지만,AudioContext의currentTime진행을 일시정지하고, 오디오 데이터 처리를 중단합니다.close가 호출되면, 다음 단계를 실행합니다:-
this의 관련 전역 객체의 연결된 Document가 완전히 활성화 상태가 아니면, "
InvalidStateError"DOMException으로 거부된 promise를 반환합니다. -
promise를 새 Promise로 둡니다.
-
AudioContext의[[control thread state]]플래그가closed라면 해당 promise를InvalidStateError로 거부하고, 이 단계를 중단하며 promise를 반환합니다. -
AudioContext의[[control thread state]]플래그를closed로 설정합니다. -
제어 메시지를 큐잉하여
AudioContext를 닫습니다. -
promise를 반환합니다.
제어 메시지를 실행하여AudioContext를 닫는다는 것은 렌더링 스레드에서 다음 단계를 수행하는 것을 의미합니다:-
시스템 리소스 해제를 시도합니다.
-
[[rendering thread state]]를suspended로 설정합니다.이는 렌더링을 중단합니다. -
이 제어 메시지가 문서 언로드에 대한 반응으로 실행되는 경우, 이 알고리즘을 중단합니다.
이 경우에는 제어 스레드에 알릴 필요가 없습니다. -
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
promise를 resolve합니다.
-
AudioContext의state속성이 이미 "closed"가 아니라면:-
AudioContext의state속성을 "closed"로 설정합니다. -
미디어 요소 태스크를 큐잉하여 statechange라는 이름의 이벤트를
AudioContext에 발생시킵니다.
-
-
AudioContext가 닫히면, 해당MediaStream과HTMLMediaElement에 연결되어 있던 출력은 무시됩니다. 즉, 더 이상 스피커나 기타 출력 장치로의 출력이 발생하지 않습니다. 동작의 유연성이 더 필요하다면HTMLMediaElement.captureStream()사용을 고려하세요.Note:
AudioContext가 닫히면, 구현체는 일시정지(suspend)할 때보다 더 적극적으로 리소스를 해제하도록 선택할 수 있습니다.파라미터 없음. -
createMediaElementSource(mediaElement)-
MediaElementAudioSourceNode를 지정된HTMLMediaElement로부터 생성합니다. 이 메서드를 호출하면HTMLMediaElement의 오디오 재생은AudioContext의 처리 그래프로 재라우팅됩니다.AudioContext.createMediaElementSource() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 mediaElementHTMLMediaElement✘ ✘ 재라우팅될 미디어 요소. 반환 타입:MediaElementAudioSourceNode createMediaStreamDestination()-
MediaStreamAudioDestinationNode를 생성합니다.파라미터 없음. createMediaStreamSource(mediaStream)-
MediaStreamAudioSourceNode를 생성합니다.AudioContext.createMediaStreamSource() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 mediaStreamMediaStream✘ ✘ 소스로 동작할 미디어 스트림. 반환 타입:MediaStreamAudioSourceNode createMediaStreamTrackSource(mediaStreamTrack)-
MediaStreamTrackAudioSourceNode를 생성합니다.AudioContext.createMediaStreamTrackSource() 메서드의 인수. 파라미터 타입 Nullable Optional 설명 mediaStreamTrackMediaStreamTrack✘ ✘ 소스로 동작할 MediaStreamTrack. 이 객체의kind속성 값은"audio"와 같아야 하며, 그렇지 않으면InvalidStateError예외가 반드시 발생해야 합니다. getOutputTimestamp()-
컨텍스트에 대해 서로 관련된 두 오디오 스트림 위치 값을 담는 새
AudioTimestamp인스턴스를 반환합니다:contextTime멤버는 오디오 출력 장치에 의해 현재 렌더링 중인 샘플 프레임의 시간을 포함하며(즉, 출력 오디오 스트림 위치), 컨텍스트의currentTime과 동일한 단위와 기준점을 갖습니다.performanceTime멤버는 저장된contextTime값에 해당하는 샘플 프레임이 오디오 출력 장치에 의해 렌더링된 시점을 추정한 시간을 포함하며, [hr-time-3]에 설명된performance.now()와 동일한 단위와 기준점을 갖습니다.컨텍스트의 렌더링 그래프가 아직 오디오 블록을 처리하지 않았다면,
getOutputTimestamp호출은 두 멤버가 모두 0을 포함하는AudioTimestamp인스턴스를 반환합니다.컨텍스트의 렌더링 그래프가 오디오 블록 처리를 시작한 이후에는,
currentTime속성 값이 항상contextTime값보다 큽니다. 이getOutputTimestamp메서드 호출에서 얻은 값과 비교했을 때 그렇습니다.getOutputTimestamp메서드에서 반환된 값을 사용하여, 약간 이후의 컨텍스트 시간 값에 대한 퍼포먼스 시간 추정을 얻을 수 있습니다:function outputPerformanceTime( contextTime) { const timestamp= context. getOutputTimestamp(); const elapsedTime= contextTime- timestamp. contextTime; return timestamp. performanceTime+ elapsedTime* 1000 ; } 위 예시에서 추정의 정확도는 인수 값이 현재 출력 오디오 스트림 위치에 얼마나 가까운지에 달려 있습니다. 즉, 전달된
contextTime이timestamp.contextTime에 가까울수록 얻은 추정의 정확도는 더 좋아집니다.Note: 컨텍스트의
currentTime과contextTime(getOutputTimestamp호출로 얻은 값) 간의 차이는 신뢰할 수 있는 출력 지연 추정으로 간주될 수 없습니다. 그 이유는currentTime이 일정하지 않은 시간 간격으로 증가할 수 있기 때문입니다. 대신outputLatency속성을 사용해야 합니다.파라미터 없음.반환 타입:AudioTimestamp resume()-
일시정지된 경우
AudioContext의currentTime진행을 재개합니다.resume이 호출되면, 다음 단계를 실행합니다:-
this의 관련 전역 객체의 연결된 Document가 완전히 활성화 상태가 아니면, "
InvalidStateError"DOMException으로 거부된 promise를 반환합니다. -
promise를 새 Promise로 둡니다.
-
AudioContext의[[control thread state]]가closed라면 해당 promise를InvalidStateError로 거부하고, 이 단계를 중단하며 promise를 반환합니다. -
[[suspended by user]]를false로 설정합니다. -
컨텍스트가 시작 가능하지 않다면, promise를
[[pending promises]]와[[pending resume promises]]에 추가하고, 이 단계를 중단하며 promise를 반환합니다. -
AudioContext의[[control thread state]]를running으로 설정합니다. -
제어 메시지를 큐잉하여
AudioContext를 재개합니다. -
promise를 반환합니다.
제어 메시지를 실행하여AudioContext를 재개한다는 것은 렌더링 스레드에서 다음 단계를 수행하는 것을 의미합니다:-
시스템 리소스 확보를 시도합니다.
-
AudioContext의[[rendering thread state]]를running으로 설정합니다. -
오디오 그래프 렌더링을 시작합니다.
-
실패한 경우, 미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
[[pending resume promises]]의 모든 promise를 순서대로 거부하고, 이어서[[pending resume promises]]를 비웁니다. -
추가로, 해당 promise들을
[[pending promises]]에서 제거합니다.
-
-
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
[[pending resume promises]]의 모든 promise를 순서대로 resolve합니다. -
[[pending resume promises]]를 비우고, 또한 해당 promise들을[[pending promises]]에서 제거합니다. -
promise를 resolve합니다.
-
AudioContext의state속성이 이미 "running"이 아니라면:-
AudioContext의state속성을 "running"으로 설정합니다. -
미디어 요소 태스크를 큐잉하여 statechange라는 이름의 이벤트를
AudioContext에 발생시킵니다.
-
-
파라미터 없음. -
suspend()-
AudioContext의currentTime진행을 일시정지합니다. 이미 처리된 현재 컨텍스트 처리 블록이 목적지로 재생되도록 허용한 다음, 시스템이 오디오 하드웨어에 대한 점유를 해제할 수 있도록 합니다. 이는 애플리케이션이 일정 시간 동안AudioContext가 필요하지 않음을 알고, 해당AudioContext와 연결된 시스템 리소스를 일시적으로 해제하려고 할 때 일반적으로 유용합니다. 프레임 버퍼가 비어(하드웨어에 전달 완료) 있으면 promise가 resolve되며, 컨텍스트가 이미suspended라면 즉시(다른 효과 없이) resolve됩니다. 컨텍스트가 닫혀 있으면 promise는 거부됩니다.suspend가 호출되면, 다음 단계를 실행합니다:-
this의 관련 전역 객체의 연결된 Document가 완전히 활성화 상태가 아니면, "
InvalidStateError"DOMException으로 거부된 promise를 반환합니다. -
promise를 새 Promise로 둡니다.
-
AudioContext의[[control thread state]]가closed라면 해당 promise를InvalidStateError로 거부하고, 이 단계를 중단하며 promise를 반환합니다. -
promise를
[[pending promises]]에 추가합니다. -
[[suspended by user]]를true로 설정합니다. -
AudioContext의[[control thread state]]를suspended로 설정합니다. -
제어 메시지를 큐잉하여
AudioContext를 일시정지합니다. -
promise를 반환합니다.
제어 메시지를 실행하여AudioContext를 일시정지한다는 것은 렌더링 스레드에서 다음 단계를 수행하는 것을 의미합니다:-
시스템 리소스 해제를 시도합니다.
-
AudioContext의[[rendering thread state]]를suspended로 설정합니다. -
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
promise를 resolve합니다.
-
AudioContext의state속성이 이미 "suspended"가 아니라면:-
AudioContext의state속성을 "suspended"로 설정합니다. -
미디어 요소 태스크를 큐잉하여 statechange라는 이름의 이벤트를
AudioContext에 발생시킵니다.
-
-
AudioContext가 일시정지된 동안에는,MediaStream의 출력이 무시되며(실시간 스트림의 특성상 데이터가 손실됨),HTMLMediaElement도 시스템이 재개될 때까지 마찬가지로 출력이 무시됩니다.AudioWorkletNode와ScriptProcessorNode의 처리 핸들러는 일시정지 중 호출되지 않지만, 컨텍스트가 재개되면 다시 호출됩니다.AnalyserNode의 윈도 함수 목적상 데이터는 연속 스트림으로 간주됩니다. 즉,resume()/suspend()는AnalyserNode의 데이터 스트림에 무음을 삽입하지 않습니다. 특히,AudioContext가 일시정지된 동안AnalyserNode함수를 반복적으로 호출하면 동일한 데이터가 반환되어야 합니다.파라미터 없음. -
setSinkId((DOMString or AudioSinkOptions) sinkId)-
출력 장치의 식별자를 설정합니다. 이 메서드가 호출되면, 사용자 에이전트는 다음 단계를 수행해야 합니다:
-
sinkId를 메서드의 첫 번째 인수로 둡니다.
-
sinkId가
[[sink ID]]와 같다면, promise를 반환하고 즉시 resolve한 뒤 이 단계를 중단합니다. -
validationResult를 sink 식별자 검증의 반환 값으로 둡니다 (sinkId에 대해).
-
validationResult가
null이 아니면, validationResult로 거부된 promise를 반환하고 이 단계를 중단합니다. -
p를 새 promise로 둡니다.
-
p와 sinkId를 포함한 제어 메시지를 전송하여 처리를 시작합니다.
-
p를 반환합니다.
setSinkId()중 처리를 시작하기 위해 제어 메시지를 전송한다는 것은 다음 단계를 수행하는 것을 의미합니다:-
이 알고리즘에 전달된 promise를 p로 둡니다.
-
이 알고리즘에 전달된 sink 식별자를 sinkId로 둡니다.
-
sinkId와
[[sink ID]]가 모두DOMString타입이고 서로 같다면, 미디어 요소 태스크를 큐잉하여 p를 resolve하고 이 단계를 중단합니다. -
sinkId가
AudioSinkOptions타입이고,[[sink ID]]가AudioSinkInfo타입이며, sinkId의type과type이 서로 같다면, 미디어 요소 태스크를 큐잉하여 p를 resolve하고 이 단계를 중단합니다. -
wasRunning을 true로 둡니다.
-
AudioContext의[[rendering thread state]]가"suspended"이면 wasRunning을 false로 설정합니다. -
현재 렌더 퀀텀을 처리한 뒤 렌더러를 일시정지합니다.
-
시스템 리소스 해제를 시도합니다.
-
wasRunning이 true라면:
-
AudioContext의[[rendering thread state]]를"suspended"로 설정합니다. -
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
AudioContext의state속성이 이미 "suspended"가 아니라면:-
AudioContext의state속성을 "suspended"로 설정합니다. -
statechange라는 이름의 이벤트를 연결된
AudioContext에 발생시킵니다.
-
-
-
-
[[sink ID]]에 기반하여 렌더링에 사용할 다음 오디오 출력 장치를 위해 시스템 리소스 확보를 시도합니다:-
빈 문자열의 경우 기본 오디오 출력 장치.
-
[[sink ID]]로 식별되는 오디오 출력 장치.
실패한 경우, "
InvalidAccessError"로 p를 거부하고 이후 단계를 중단합니다. -
-
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
sinkId가
DOMString타입이면,[[sink ID]]를 sinkId로 설정하고 이 단계를 중단합니다. -
sinkId가
AudioSinkOptions타입이고[[sink ID]]가DOMString타입이면,[[sink ID]]를 sinkId의type값으로 생성한 새AudioSinkInfo인스턴스로 설정합니다. -
sinkId가
AudioSinkOptions타입이고[[sink ID]]가AudioSinkInfo타입이면,type을[[sink ID]]의 sinkId의type값으로 설정합니다. -
p를 resolve합니다.
-
sinkchange라는 이름의 이벤트를 연결된
AudioContext에 발생시킵니다.
-
-
wasRunning이 true라면:
-
AudioContext의[[rendering thread state]]를"running"으로 설정합니다. -
미디어 요소 태스크를 큐잉하여 다음 단계를 실행합니다:
-
AudioContext의state속성이 이미 "running"이 아니라면:-
AudioContext의state속성을 "running"으로 설정합니다. -
statechange라는 이름의 이벤트를 연결된
AudioContext에 발생시킵니다.
-
-
-
-
1.2.4.
sinkId
유효성 검사
이 알고리즘은 sinkId를
수정하기 위해 제공된 정보를 검증하는 데 사용됩니다:
-
document를 현재 설정 객체의 연결된 Document로 둡니다.
-
sinkIdArg를 이 알고리즘에 전달된 값으로 둡니다.
-
document가
"speaker-selection"로 식별된 기능을 사용할 수 없다면, 이름이 "NotAllowedError"인 새DOMException을 반환합니다. -
sinkIdArg가
DOMString타입이지만 빈 문자열이 아니거나enumerateDevices()에서 반환되는 오디오 출력 장치와 일치하지 않으면, 이름이 "NotFoundError"인 새DOMException을 반환합니다. -
null을 반환합니다.
1.2.5. AudioContextOptions
AudioContextOptions
딕셔너리는 AudioContext에
사용자 지정 옵션을 지정하는 데 사용됩니다.
dictionary AudioContextOptions { (AudioContextLatencyCategory or double )latencyHint = "interactive";float sampleRate ; (DOMString or AudioSinkOptions )sinkId ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.2.5.1. 딕셔너리 AudioContextOptions
멤버
latencyHint, 타입(AudioContextLatencyCategory or double), 기본값은"interactive"-
오디오 출력 지연(latency)과 전력 소비 간의 트레이드오프에 영향을 주는 재생 유형을 지정합니다.
latencyHint의 권장 값은AudioContextLatencyCategory중 하나입니다. 하지만, 더 세밀하게 latency와 전력 소비의 균형을 제어하기 위해 초 단위의 double 값을 지정할 수도 있습니다. 브라우저는 해당 값을 적절히 해석할 수 있습니다. 실제로 적용되는 지연값은 AudioContext의baseLatency속성에서 확인할 수 있습니다. sampleRate, 타입 float-
생성될
AudioContext의sampleRate를 이 값으로 설정합니다. 지원되는 값은AudioBuffer의 샘플레이트와 동일합니다. 지정한 샘플레이트가 지원되지 않을 경우NotSupportedError예외가 반드시 발생해야 합니다.sampleRate가 지정되지 않은 경우, 해당AudioContext에 대해 출력 장치의 권장 샘플레이트가 사용됩니다. sinkId, 타입(DOMString or AudioSinkOptions)-
오디오 출력 장치의 식별자 또는 관련 정보입니다. 자세한 내용은
sinkId를 참조하세요. renderSizeHint, 타입(AudioContextRenderSizeCategory or unsigned long), 기본값은"default"-
정수값을 전달하면 특정 렌더 퀀텀 크기를 요청할 수 있고, 아무 값도 전달하지 않거나
"default"를 지정하면 128 프레임의 기본값을 사용합니다."hardware"를 지정하면 User-Agent가 적합한 렌더 퀀텀 크기를 선택하도록 요청할 수 있습니다.이 값은 힌트이며 반드시 반영되는 것은 아닙니다.
1.2.6.
AudioSinkOptions
AudioSinkOptions
딕셔너리는 sinkId에
대한 옵션을 지정하는 데 사용됩니다.
dictionary AudioSinkOptions {required AudioSinkType type ; };
1.2.6.1. 딕셔너리 AudioSinkOptions
멤버
type, 타입 AudioSinkType-
장치의 타입을 지정하기 위한
AudioSinkType값입니다.
1.2.7. AudioSinkInfo
AudioSinkInfo
인터페이스는 sinkId를
통해 현재 오디오 출력 장치의 정보를 얻는 데 사용됩니다.
[Exposed =Window ]interface AudioSinkInfo {readonly attribute AudioSinkType type ; };
1.2.7.1. 속성
type, 타입 AudioSinkType, 읽기 전용-
장치의 타입을 나타내는
AudioSinkType값입니다.
1.2.8. AudioTimestamp
dictionary AudioTimestamp {double contextTime ;DOMHighResTimeStamp performanceTime ; };
1.2.8.1. 딕셔너리 AudioTimestamp
멤버
contextTime, 타입 double-
BaseAudioContext의
currentTime시간 좌표계의 한 지점을 나타냅니다. performanceTime, 타입 DOMHighResTimeStamp-
[hr-time-3]에서 설명한
Performance인터페이스의 시간 좌표계의 한 지점을 나타냅니다.
1.2.9. AudioRenderCapacity
[Exposed =Window ]interface :AudioRenderCapacity EventTarget {undefined start (optional AudioRenderCapacityOptions = {});options undefined stop ();attribute EventHandler onupdate ; };
이 인터페이스는 AudioContext의
렌더링 성능 지표를 제공합니다.
이를 계산하기 위해 렌더러는 load value를 시스템 레벨
오디오 콜백마다 수집합니다.
1.2.9.1. 속성
onupdate, 타입 EventHandler-
이 이벤트 핸들러의 이벤트 타입은
update입니다. 이벤트는AudioRenderCapacityEvent인터페이스를 사용하여 디스패치됩니다.
1.2.9.2. 메서드
start(options)-
메트릭 수집 및 분석을 시작합니다. 이는 주기적으로 update라는 이벤트를
update이름으로AudioRenderCapacity에서,AudioRenderCapacityEvent를 사용하여,AudioRenderCapacityOptions에 지정된 업데이트 간격으로 발생시킵니다. stop()-
메트릭 수집 및 분석을 중단합니다. 또한
update이벤트의 디스패치를 중단합니다.
1.2.10.
AudioRenderCapacityOptions
AudioRenderCapacityOptions
딕셔너리는 AudioRenderCapacity에
대한 사용자 옵션을 제공하는 데 사용할 수 있습니다.
dictionary {AudioRenderCapacityOptions double updateInterval = 1; };
1.2.10.1. 딕셔너리 AudioRenderCapacityOptions
멤버
updateInterval, 타입 double, 기본값1-
AudioRenderCapacityEvent디스패치를 위한 갱신 간격(초 단위)입니다. load value는 시스템 레벨 오디오 콜백마다 계산되며, 지정된 간격 동안 여러 load value가 수집됩니다. 예를 들어, 렌더러가 48Khz 샘플레이트로 실행되고 시스템 레벨 오디오 콜백의 버퍼 크기가 192 프레임이면, 1초 간격 동안 250개의 load value가 수집됩니다.주어진 값이 시스템 레벨 오디오 콜백의 지속 시간보다 작으면,
NotSupportedError예외가 발생합니다.
1.2.11. AudioRenderCapacityEvent
[Exposed =Window ]interface :AudioRenderCapacityEvent Event {(constructor DOMString ,type optional AudioRenderCapacityEventInit = {});eventInitDict readonly attribute double timestamp ;readonly attribute double averageLoad ;readonly attribute double peakLoad ;readonly attribute double underrunRatio ; };dictionary :AudioRenderCapacityEventInit EventInit {double = 0;timestamp double = 0;averageLoad double = 0;peakLoad double = 0; };underrunRatio
1.2.11.1. 속성
timestamp, 타입 double, 읽기 전용-
데이터 수집 기간의 시작 시점을 연결된
AudioContext의currentTime기준으로 나타냅니다. averageLoad, 타입 double, 읽기 전용-
지정된 갱신 간격 동안 수집된 load 값들의 평균입니다. 정밀도는 1/100까지 제한됩니다.
peakLoad, 타입 double, 읽기 전용-
지정된 갱신 간격 동안 수집된 load 값들 중 최대값입니다. 정밀도 역시 1/100까지 제한됩니다.
underrunRatio, 타입 double, 읽기 전용-
지정된 갱신 간격 동안 load value가 1.0을 초과하는 버퍼 언더런 횟수와 전체 시스템 레벨 오디오 콜백 횟수의 비율입니다.
여기서 \(u\)는 버퍼 언더런 횟수이고 \(N\)은 해당 간격 동안의 시스템 레벨 오디오 콜백 횟수입니다. 버퍼 언더런 비율은 다음과 같습니다:
-
\(u\) = 0이면 0.0입니다.
-
그 밖의 경우 \(u/N\)을 계산하고, 가장 가까운 100분위로 올림(ceiling) 값을 사용합니다.
-
1.3. OfflineAudioContext
인터페이스
OfflineAudioContext
는 렌더링/믹스다운을 (실시간보다) 더 빠르게 처리할 수 있는 BaseAudioContext의
특수한 타입입니다.
오디오 하드웨어에 렌더링하지 않고, 가능한 한 빠르게 렌더링하며, 렌더링 결과를 AudioBuffer로
반환된 promise를 통해 제공합니다.
[Exposed =Window ]interface OfflineAudioContext :BaseAudioContext {constructor (OfflineAudioContextOptions contextOptions );constructor (unsigned long numberOfChannels ,unsigned long length ,float sampleRate );Promise <AudioBuffer >startRendering ();Promise <undefined >resume ();Promise <undefined >suspend (double );suspendTime readonly attribute unsigned long length ;attribute EventHandler oncomplete ; };
1.3.1. 생성자
OfflineAudioContext(contextOptions)-
현재 설정 객체의 관련 전역 객체의 연결된 Document가 완전히 활성화가 아니면,
c를 새InvalidStateError예외를 발생시키고, 이 단계를 중단합니다.OfflineAudioContext객체로 두고, 다음과 같이 초기화합니다:-
c의
[[control thread state]]를"suspended"로 설정합니다. -
c의
[[rendering thread state]]를"suspended"로 설정합니다. -
이
OfflineAudioContext의[[render quantum size]]를renderSizeHint값에 따라 결정합니다:-
값이
"default"또는"hardware"이면,[[render quantum size]]를 128로 설정합니다. -
그 밖에 정수가 전달된 경우, User-Agent가 이 값을 반영하여
[[render quantum size]]를 설정할 수 있습니다.
-
-
AudioDestinationNode를contextOptions.numberOfChannels값으로channelCount를 설정하여 생성합니다. -
messageChannel을 새
MessageChannel로 만듭니다. -
controlSidePort를 messageChannel의
port1값으로 둡니다. -
renderingSidePort를 messageChannel의
port2값으로 둡니다. -
serializedRenderingSidePort를 StructuredSerializeWithTransfer(renderingSidePort, « renderingSidePort ») 결과로 둡니다.
-
이
audioWorklet의port를 controlSidePort로 설정합니다. -
제어 메시지 큐잉을 통해 AudioContextGlobalScope에 MessagePort 설정을 serializedRenderingSidePort로 실행합니다.
OfflineAudioContext.constructor(contextOptions) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 contextOptions이 컨텍스트를 생성하는 데 필요한 초기 파라미터. -
OfflineAudioContext(numberOfChannels, length, sampleRate)-
OfflineAudioContext는 AudioContext.createBuffer와 동일한 인수로 생성할 수 있습니다. 인수 중 하나라도 음수, 0, 또는 허용 범위를 벗어나면NotSupportedError예외가 반드시 발생해야 합니다.OfflineAudioContext는 아래와 같이 생성한 것과 동일하게 동작합니다.
new OfflineAudioContext({ numberOfChannels: numberOfChannels, length: length, sampleRate: sampleRate}) 를 호출한 것과 같습니다.
OfflineAudioContext.constructor(numberOfChannels, length, sampleRate) 메서드의 인수. 파라미터 타입 Nullable Optional 설명 numberOfChannelsunsigned long✘ ✘ 버퍼의 채널 수를 결정합니다. 지원 채널 수는 createBuffer()참조.lengthunsigned long✘ ✘ 버퍼의 크기(샘플 프레임 단위)를 결정합니다. sampleRatefloat✘ ✘ 버퍼 내 선형 PCM 오디오 데이터의 샘플레이트(초당 샘플 프레임 수)를 설명합니다. 유효 샘플레이트는 createBuffer()참조.
1.3.2. 속성
length, 타입 unsigned long, 읽기 전용-
버퍼의 크기(샘플 프레임 단위). 생성자의
length파라미터 값과 동일합니다. oncomplete, 타입 EventHandler-
이 이벤트 핸들러의 이벤트 타입은
complete입니다. 이벤트는OfflineAudioCompletionEvent인터페이스를 사용하여 디스패치됩니다.OfflineAudioContext에서 발생하는 마지막 이벤트입니다.
1.3.3. 메서드
startRendering()-
현재 연결과 예약된 변경 사항을 기반으로 오디오 렌더링을 시작합니다.
렌더링된 오디오 데이터를 얻는 주요 방법은 반환된 promise를 사용하는 것이지만, 인스턴스는 레거시 이유로
complete라는 이벤트도 발생시킵니다.[[rendering started]]는 이OfflineAudioContext의 내부 슬롯입니다. 이 슬롯을 false로 초기화합니다.startRendering이 호출되면 다음 단계는 컨트롤 스레드에서 반드시 수행되어야 합니다:- this의 관련 글로벌 객체의 연관된 Document가 완전히 활성화되어 있지 않다면, promise를 reject하고 "
InvalidStateError"DOMException을 반환합니다. [[rendering started]]슬롯이 true라면,InvalidStateError로 reject된 promise를 반환하고, 이 단계를 중단합니다.[[rendering started]]슬롯을 true로 설정합니다.- promise를 새 promise로 생성합니다.
- 채널 수, 길이, 샘플레이트가 해당 인스턴스의 생성자
contextOptions파라미터로 전달된numberOfChannels,length,sampleRate값과 각각 동일한AudioBuffer를 생성합니다. 이 버퍼를 내부 슬롯[[rendered buffer]]에 할당합니다. - 이전
AudioBuffer생성 과정에서 예외가 발생했다면, 해당 예외로 promise를 reject합니다. - 버퍼가 성공적으로 생성되었다면, 오프라인 렌더링을 시작합니다.
- promise를
[[pending promises]]에 추가합니다. - promise를 반환합니다.
오프라인 렌더링 시작을 위해 다음 단계는 해당 작업을 위해 생성된 렌더링 스레드에서 반드시 실행되어야 합니다.- 현재 연결과 예약된 변경 사항을 기반으로
length샘플 프레임을[[rendered buffer]]에 렌더링합니다. - 각 렌더 퀀텀마다
렌더링을
suspend해야 하는지 확인합니다. - 중단된 컨텍스트가 재개되면, 버퍼 렌더링을 계속합니다.
-
렌더링이 완료되면 미디어 요소 태스크를 큐에 추가하여 다음 단계를 실행합니다:
startRendering()에서 생성된 promise를[[rendered buffer]]로 resolve합니다.- 미디어 요소 태스크를 큐에 추가하여 이벤트를 발생시킵니다. 이벤트 이름은
complete이며,OfflineAudioContext에서OfflineAudioCompletionEvent인스턴스를 사용하고renderedBuffer속성은[[rendered buffer]]로 설정됩니다.
파라미터 없음.반환 타입:Promise<AudioBuffer> - this의 관련 글로벌 객체의 연관된 Document가 완전히 활성화되어 있지 않다면, promise를 reject하고 "
resume()-
OfflineAudioContext의currentTime진행이 중단된 경우, 진행을 다시 시작합니다.resume이 호출되면, 다음 단계를 수행합니다:-
this의 관련 글로벌 객체의 연관된 Document가 완전히 활성화되어 있지 않다면, promise를 reject하고 "
InvalidStateError"DOMException을 반환합니다. -
promise를 새 Promise로 생성합니다.
-
다음 조건 중 하나라도 참이면, 이 단계를 중단하고 promise를
InvalidStateError로 reject합니다:-
[[control thread state]]값이closed인 경우. -
[[rendering started]]슬롯 값이 false인 경우.
-
-
[[control thread state]]플래그를OfflineAudioContext에서running으로 설정합니다. -
컨트롤 메시지 큐에 추가하여
OfflineAudioContext를 재개합니다. -
promise를 반환합니다.
컨트롤 메시지를 실행하여OfflineAudioContext를 재개한다는 것은 렌더링 스레드에서 다음 단계를 실행한다는 의미입니다:-
[[rendering thread state]]값을running으로 설정합니다. -
오디오 그래프 렌더링을 시작합니다.
-
실패 시 미디어 요소 태스크를 큐에 추가하여 promise를 reject하고 남은 단계를 중단합니다.
-
미디어 요소 태스크를 큐에 추가하여 다음 단계를 실행합니다:
-
promise를 resolve합니다.
-
-
state속성을OfflineAudioContext에서 "running"으로 설정합니다. -
미디어 요소 태스크를 큐에 추가하여 이벤트를 발생시킵니다. 이벤트 이름은
statechange이며,OfflineAudioContext에서 발생합니다.
-
-
파라미터 없음. -
suspend(suspendTime)-
오디오 컨텍스트의 시간 진행을 지정된 시점에 일시 중지하도록 예약하고 promise를 반환합니다. 이는
OfflineAudioContext에서 오디오 그래프를 동기적으로 조작할 때 일반적으로 유용합니다.일시 중지의 최대 정밀도는 렌더 퀀텀 크기이며, 지정한 일시 중지 시간은 가장 가까운 렌더 퀀텀 경계로 올림 처리됩니다. 이로 인해 동일한 양자화 프레임에서 여러 번 suspend를 예약할 수 없습니다. 또한, 정확한 일시 중지를 위해서는 컨텍스트가 실행 중이 아닐 때 예약해야 합니다.
OfflineAudioContext.suspend() 메서드의 인자. 파라미터 타입 Nullable Optional 설명 suspendTimedouble✘ ✘ 지정한 시간에 렌더링을 일시 중지하도록 예약합니다. 이 시간은 양자화되어 렌더 퀀텀 크기에 맞게 올림 처리됩니다. 만약 양자화된 프레임 번호가 - 음수이거나
- 현재 시간 이하이거나
- 전체 렌더링 기간 이상이거나
- 동일한 시간에 다른 suspend가 예약되어 있으면,
InvalidStateError로 reject됩니다.
1.3.4. OfflineAudioContextOptions
이는 OfflineAudioContext를
생성할 때 사용할 옵션을 지정합니다.
dictionary OfflineAudioContextOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.3.4.1. Dictionary OfflineAudioContextOptions
멤버
length, 타입 unsigned long-
렌더링된
AudioBuffer의 샘플 프레임 길이입니다. numberOfChannels, 타입 unsigned long, 기본값1-
이
OfflineAudioContext의 채널 수입니다. sampleRate, 타입 float-
이
OfflineAudioContext의 샘플레이트입니다. renderSizeHint, 타입(AudioContextRenderSizeCategory or unsigned long), 기본값"default"-
이
OfflineAudioContext의 렌더 퀀텀 크기에 대한 힌트입니다.
1.3.5.
OfflineAudioCompletionEvent
인터페이스
이는 Event
객체로, 레거시 이유로 OfflineAudioContext에
디스패치됩니다.
[Exposed =Window ]interface OfflineAudioCompletionEvent :Event {(constructor DOMString ,type OfflineAudioCompletionEventInit );eventInitDict readonly attribute AudioBuffer renderedBuffer ; };
1.3.5.1. 속성
renderedBuffer, 타입 AudioBuffer, 읽기 전용-
렌더링된 오디오 데이터를 담고 있는
AudioBuffer입니다.
1.3.5.2.
OfflineAudioCompletionEventInit
dictionary OfflineAudioCompletionEventInit :EventInit {required AudioBuffer renderedBuffer ; };
1.3.5.2.1. Dictionary OfflineAudioCompletionEventInit
멤버
renderedBuffer, 타입 AudioBuffer-
이 이벤트의
renderedBuffer속성에 할당될 값입니다.
1.4. AudioBuffer
인터페이스
이 인터페이스는 메모리에 상주하는 오디오 에셋을 나타냅니다. 하나 이상의 채널을 포함할 수 있으며, 각 채널은 32비트 부동소수점 linear PCM 값(명목 범위 \([-1,1]\))을 가진 것으로 보이지만
실제 값은 이 범위에 제한되지 않습니다. 일반적으로 PCM 데이터의 길이는 상당히 짧을 것으로(대개 1분 미만) 예상됩니다.
더 긴 사운드(예: 음악 사운드트랙)의 경우
audio
요소와 MediaElementAudioSourceNode를
이용해 스트리밍해야 합니다.
AudioBuffer
는 하나 이상의 AudioContext에서
사용할 수 있으며,
OfflineAudioContext와
AudioContext
간에 공유할 수 있습니다.
AudioBuffer
는 네 개의 내부 슬롯을 가집니다:
[[number of channels]]-
이
AudioBuffer의 오디오 채널 수로, unsigned long 타입입니다. [[length]]-
이
AudioBuffer의 각 채널 길이로, unsigned long 타입입니다. [[sample rate]]-
이
AudioBuffer의 샘플레이트(Hz)로, float 타입입니다. [[internal data]]-
오디오 샘플 데이터를 저장하는 data block입니다.
[Exposed =Window ]interface AudioBuffer {constructor (AudioBufferOptions );options readonly attribute float sampleRate ;readonly attribute unsigned long length ;readonly attribute double duration ;readonly attribute unsigned long numberOfChannels ;Float32Array getChannelData (unsigned long );channel undefined copyFromChannel (Float32Array ,destination unsigned long ,channelNumber optional unsigned long = 0);bufferOffset undefined copyToChannel (Float32Array ,source unsigned long ,channelNumber optional unsigned long = 0); };bufferOffset
1.4.1. 생성자
AudioBuffer(options)-
-
options값 중 어떤 값이라도 명목 범위를 벗어나면NotSupportedError예외를 던지고 이후 단계를 중단합니다. -
b를 새
AudioBuffer객체로 생성합니다. -
생성자에 전달된
AudioBufferOptions의numberOfChannels,length,sampleRate속성 값을 각각 내부 슬롯[[number of channels]],[[length]],[[sample rate]]에 할당합니다. -
이
AudioBuffer의 내부 슬롯[[internal data]]를CreateByteDataBlock(호출 결과로 설정합니다.[[length]]*[[number of channels]])참고: 이는 기본 저장소를 0으로 초기화합니다.
-
b를 반환합니다.
AudioBuffer.constructor() 메서드의 인자. 파라미터 타입 Nullable Optional 설명 optionsAudioBufferOptions✘ ✘ 이 AudioBuffer의 속성을 결정하는AudioBufferOptions입니다. -
1.4.2. 속성
duration, 타입 double, 읽기 전용-
PCM 오디오 데이터의 초 단위 길이입니다.
이 값은
[[sample rate]]와[[length]]를 이용해AudioBuffer에서[[length]]를[[sample rate]]로 나누어 계산합니다. length, 타입 unsigned long, 읽기 전용-
PCM 오디오 데이터의 샘플 프레임 단위 길이.
[[length]]값을 반환해야 합니다. numberOfChannels, 타입 unsigned long, 읽기 전용-
개별 오디오 채널의 개수.
[[number of channels]]값을 반환해야 합니다. sampleRate, 타입 float, 읽기 전용-
PCM 오디오 데이터의 초당 샘플 수.
[[sample rate]]값을 반환해야 합니다.
1.4.3. 메서드
copyFromChannel(destination, channelNumber, bufferOffset)-
copyFromChannel()메서드는 지정한AudioBuffer의 채널에서destination배열로 샘플을 복사합니다.buffer를 \(N_b\) 프레임을 가진AudioBuffer로, \(N_f\)를destination배열의 요소 개수로, \(k\)를bufferOffset값으로 두면,buffer에서destination으로 복사되는 프레임 개수는 \(\max(0, \min(N_b - k, N_f))\)입니다. 만약 이 값이 \(N_f\)보다 작으면destination의 나머지 요소는 수정되지 않습니다.AudioBuffer.copyFromChannel() 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationFloat32Array✘ ✘ 채널 데이터를 복사할 배열. channelNumberunsigned long✘ ✘ 데이터를 복사할 채널의 인덱스. channelNumber가AudioBuffer의 채널 수 이상이면,IndexSizeError를 반드시 throw해야 합니다.bufferOffsetunsigned long✘ ✔ 옵션 오프셋 (기본값 0). AudioBuffer에서 해당 오프셋부터destination으로 복사됨.반환 타입:undefined copyToChannel(source, channelNumber, bufferOffset)-
copyToChannel()메서드는source배열에서 지정한AudioBuffer의 채널로 샘플을 복사합니다.UnknownError는source를 버퍼로 복사할 수 없을 때 throw될 수 있습니다.buffer를 \(N_b\) 프레임을 가진AudioBuffer로, \(N_f\)를source배열의 요소 개수로, \(k\)를bufferOffset값으로 두면,source에서buffer로 복사되는 프레임 개수는 \(\max(0, \min(N_b - k, N_f))\)입니다. 만약 이 값이 \(N_f\)보다 작으면 buffer의 나머지 요소는 수정되지 않습니다.AudioBuffer.copyToChannel() 메서드 인자. 파라미터 타입 Nullable Optional 설명 sourceFloat32Array✘ ✘ 채널 데이터가 복사될 배열. channelNumberunsigned long✘ ✘ 데이터를 복사할 채널의 인덱스. channelNumber가AudioBuffer의 채널 수 이상이면,IndexSizeError를 반드시 throw해야 합니다.bufferOffsetunsigned long✘ ✔ 옵션 오프셋(기본값 0). source에서 이 오프셋부터AudioBuffer로 복사됨.반환 타입:undefined getChannelData(channel)-
acquire the content 규칙에 따라 쓰기 또는 복사본 획득을 허용하며,
[[internal data]]에 저장된 바이트를 새로운Float32Array로 반환합니다.UnknownError는[[internal data]]또는 새로운Float32Array를 생성할 수 없을 때 throw될 수 있습니다.AudioBuffer.getChannelData() 메서드 인자. 파라미터 타입 Nullable Optional 설명 channelunsigned long✘ ✘ 데이터를 가져올 채널의 인덱스. 0은 첫 번째 채널을 의미하며, 이 인덱스 값은 [[number of channels]]보다 작아야 하며, 아니면IndexSizeError예외를 반드시 throw해야 합니다.반환 타입:Float32Array
참고: copyToChannel()
및 copyFromChannel()
은 Float32Array
뷰를 사용해 큰 배열의 일부만 채울 수 있습니다.
AudioBuffer의
채널 데이터를 읽고, 데이터를 청크 단위로 처리할 때는 copyFromChannel()
을 사용하는 것이 getChannelData()
를 호출하여 결과 배열에 접근하는 것보다
불필요한 메모리 할당과 복사를 줄일 수 있어 더 바람직합니다.
AudioBuffer의
내용을 API 구현에서 필요로 할 때 acquire the
contents of an AudioBuffer 내부 연산이 호출됩니다. 이 연산은 호출자에게 불변 채널 데이터를 반환합니다.
AudioBuffer에서
발생하면 다음 단계를 실행합니다:
-
해당
AudioBuffer의ArrayBuffer중 하나라도 detached 상태라면true를 반환하고, 단계를 중단하며, 호출자에게 길이가 0인 채널 데이터 버퍼를 반환합니다. -
이
AudioBuffer의ArrayBuffer중getChannelData()에서 반환한 배열에 대해 모두 Detach를 수행합니다.참고:
AudioBuffer는createBuffer()또는AudioBuffer생성자를 통해서만 생성되므로, 이는 throw되지 않습니다. -
해당
[[internal data]]를ArrayBuffer로부터 보존하고, 호출자에게 참조를 반환합니다. -
복사본 데이터를 담은
ArrayBuffer를AudioBuffer에 연결하여, 다음getChannelData()호출 시 반환합니다.
acquire the contents of an AudioBuffer 연산은 다음의 경우에 호출됩니다:
-
AudioBufferSourceNode.start호출 시, 해당 노드의buffer의 내용을 획득합니다. 실패하면 아무 것도 재생되지 않습니다. -
AudioBufferSourceNode의buffer가 설정되고, 이전에AudioBufferSourceNode.start가 호출된 경우, setter는 내용을 획득합니다. 실패하면 아무 것도 재생되지 않습니다. -
ConvolverNode의buffer가AudioBuffer로 설정될 때, 내용을 획득합니다. -
AudioProcessingEvent디스패치가 완료될 때, 해당 이벤트의outputBuffer의 내용을 획득합니다.
참고: copyToChannel()
은 acquire the
content of an AudioBuffer가 호출된 AudioNode가 현재
사용하는
AudioBuffer의
내용을
변경할 수 없습니다. 해당 AudioNode는 이전에
획득한 데이터를 계속 사용합니다.
1.4.4. AudioBufferOptions
이는 AudioBuffer를
생성할 때 사용할 옵션을 지정합니다.
length와
sampleRate
멤버는 필수입니다.
dictionary AudioBufferOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; };
1.4.4.1. Dictionary AudioBufferOptions
멤버
이 딕셔너리의 멤버에 허용되는 값들은 제한됩니다. createBuffer()를
참고하세요.
length, 타입 unsigned long-
버퍼의 샘플 프레임 길이입니다. 제한 사항은
length를 참고하세요. numberOfChannels, 타입 unsigned long, 기본값1-
버퍼의 채널 수. 제한 사항은
numberOfChannels를 참고하세요. sampleRate, 타입 float-
버퍼의 샘플레이트(Hz). 제한 사항은
sampleRate를 참고하세요.
1.5. AudioNode
인터페이스
AudioNode는
AudioContext의
빌딩 블록입니다.
이 인터페이스는
오디오 소스, 오디오 목적지, 그리고 중간 처리 모듈을 나타냅니다. 이러한 모듈들은 서로 연결되어 오디오 하드웨어에 오디오를 렌더링하기 위한 처리
그래프를 구성할 수 있습니다.
각 노드는 입력 및/또는 출력을 가질 수 있습니다. 소스 노드는 입력이 없고 출력이 하나입니다. 대부분의 필터와 같은 처리 노드는 입력 하나와 출력 하나를 가집니다.
각 AudioNode의
오디오 처리 방법은 세부적으로 다르지만, 일반적으로 AudioNode는
입력(있는 경우)을 처리하고 출력(있는 경우)을 생성합니다.
각 출력은 하나 이상의 채널을 가집니다. 정확한 채널 수는 해당 AudioNode의 세부
사항에 따라 달라집니다.
출력은 하나 이상의 AudioNode 입력에
연결될 수 있으므로 fan-out이 지원됩니다. 입력은 처음엔 연결이 없지만 하나 이상의 AudioNode 출력에서
연결될 수 있으므로 fan-in도 지원됩니다.
connect() 메서드를 사용해 AudioNode의 출력을
다른 AudioNode의 입력에
연결하면,
이를 입력에 대한 연결이라고 합니다.
각 AudioNode
입력은 언제든 특정 채널 수를 가집니다. 이 수는 입력에
대한 연결에 따라 달라질 수 있습니다. 입력에 연결이 없으면 한
채널(무음)을 가집니다.
각 입력에 대해 AudioNode는
해당 입력에 대한 모든 연결을 믹싱합니다.
규범적 요구사항과 세부 사항은 § 4 채널 업믹싱과 다운믹싱에서 참고하세요.
입력 처리 및 AudioNode의 내부
동작은
AudioContext
시간에 따라 연결된 출력이 있든 없든,
그리고 이 출력이 궁극적으로 AudioContext의
AudioDestinationNode에
도달하든 상관없이
계속적으로 이루어집니다.
[Exposed =Window ]interface AudioNode :EventTarget {AudioNode connect (AudioNode destinationNode ,optional unsigned long output = 0,optional unsigned long input = 0);undefined connect (AudioParam destinationParam ,optional unsigned long output = 0);undefined disconnect ();undefined disconnect (unsigned long output );undefined disconnect (AudioNode destinationNode );undefined disconnect (AudioNode destinationNode ,unsigned long output );undefined disconnect (AudioNode destinationNode ,unsigned long output ,unsigned long input );undefined disconnect (AudioParam destinationParam );undefined disconnect (AudioParam destinationParam ,unsigned long output );readonly attribute BaseAudioContext context ;readonly attribute unsigned long numberOfInputs ;readonly attribute unsigned long numberOfOutputs ;attribute unsigned long channelCount ;attribute ChannelCountMode channelCountMode ;attribute ChannelInterpretation channelInterpretation ; };
1.5.1. AudioNode 생성
AudioNode는 두
가지 방법으로 생성할 수 있습니다. 해당 인터페이스의 생성자를 사용하거나, BaseAudioContext
또는 AudioContext에서
팩토리 메서드를 사용하는 방법입니다.
BaseAudioContext가
AudioNode
생성자의 첫 번째 인자로 전달되면, 생성될 AudioNode의
연결된 BaseAudioContext라고
합니다.
마찬가지로 팩토리 메서드를 사용할 때, 연결된
BaseAudioContext는 해당 팩토리 메서드를 호출하는 BaseAudioContext가
됩니다.
AudioNode를 팩토리 메서드로 BaseAudioContext
c에서 생성하려면 다음 단계를 수행합니다:
-
node를 타입 n의 새 객체로 만듭니다.
-
option을 해당 팩토리 메서드와 연결된 인터페이스의 연결된 딕셔너리 타입으로 만듭니다.
-
팩토리 메서드에 전달된 각 파라미터에 대해 option의 동일한 이름의 멤버에 해당 값을 설정합니다.
-
node에 c와 option을 인자로 하여 n의 생성자를 호출합니다.
-
node를 반환합니다.
AudioNode를
상속하는 객체 o에 대해,
해당 인터페이스의 생성자에 전달된 context, dict 인자를 가지고 다음 단계를 실행하는 것을 의미합니다.
-
o의 연결된
BaseAudioContext를 context로 설정합니다. -
이 인터페이스의 각
numberOfInputs,numberOfOutputs,channelCount,channelCountMode,channelInterpretation값을 해당AudioNode에 대한 섹션에 명시된 기본값으로 설정합니다. -
dict의 각 멤버에 대해 다음 단계를 실행합니다. k는 멤버의 키, v는 값입니다. 이 과정에서 예외가 발생하면 반복을 중단하고 해당 예외를 호출자(생성자 또는 팩토리 메서드)로 전달합니다.
-
k가 이 인터페이스의
AudioParam이름이면, 해당value속성을 v로 설정합니다. -
그 외에 k가 이 인터페이스의 속성 이름이면 해당 속성 객체를 v로 설정합니다.
-
연결된 인터페이스란 팩토리 메서드에서 반환되는 객체의 인터페이스입니다. 연결된 옵션 객체란 해당 인터페이스의 생성자에 전달할 수 있는 옵션 객체입니다.
AudioNode는
EventTarget입니다.
[DOM]에 설명된 대로,
AudioNode에
이벤트를 디스패치할 수 있습니다. 이는 다른 EventTarget이
이벤트를 받을 수 있는 것과 동일합니다.
enum {ChannelCountMode "max" ,"clamped-max" ,"explicit" };
ChannelCountMode는
노드의 channelCount
및 channelInterpretation
값과 함께,
입력 채널 믹싱 방식을 결정하는 computedNumberOfChannels을 결정하는 데 사용됩니다. computedNumberOfChannels는 아래와
같이 결정됩니다. 믹싱 방법 상세는 § 4 채널 업믹싱과 다운믹싱을 참고하세요.
| 열거값 | 설명 |
|---|---|
"max"
| computedNumberOfChannels는 입력에 연결된 모든 채널 수 중
최대값입니다. 이 모드에서는 channelCount가
무시됩니다.
|
"clamped-max"
| computedNumberOfChannels는 "max"와
동일하게 결정되고, 그 값이 channelCount의
최대값으로 제한됩니다.
|
"explicit"
| computedNumberOfChannels는 channelCount에
명시된 정확한 값입니다.
|
enum {ChannelInterpretation "speakers" ,"discrete" };
| 열거값 | 설명 |
|---|---|
"speakers"
| 업믹스 방정식 또는 다운믹스 방정식을 사용합니다. 채널 수가 기본 스피커
레이아웃과 일치하지 않는 경우 "discrete"로
전환합니다.
|
"discrete"
| 채널 수가 다 소진될 때까지 채널을 채운 후 남은 채널을 0으로 채웁니다(업믹스). 다운믹스 시 가능한 채널만 채우고 나머지 채널은 버립니다. |
1.5.2. AudioNode 테일 타임
AudioNode는
테일 타임을 가질 수 있습니다. 즉, AudioNode에 무음이
입력되어도 출력이 무음이 아닐 수 있습니다.
AudioNode는 내부
처리 상태에 따라 과거 입력이 미래 출력에 영향을 주는 경우 0이 아닌 테일 타임을 가집니다. AudioNode는 입력이
무음으로 전환된 이후에도 계산된 테일 타임 동안 무음이 아닌 출력을 계속 생성할 수 있습니다.
1.5.3. AudioNode 생명주기
AudioNode는 다음
조건 중 하나라도 만족하면 렌더 퀀텀 동안 활성 처리 중일 수 있습니다.
-
AudioScheduledSourceNode는 오직 현재 렌더링 퀀텀의 일부라도 재생 중일 때 활성 처리 중입니다. -
MediaElementAudioSourceNode는 해당mediaElement가 현재 렌더링 퀀텀의 일부라도 재생 중일 때 활성 처리 중입니다. -
MediaStreamAudioSourceNode또는MediaStreamTrackAudioSourceNode는 연결된MediaStreamTrack객체가readyState속성이"live"이고muted가false,enabled가true일 때 활성 처리 중입니다. -
순환 구조 내의
DelayNode는 현재 렌더 퀀텀의 출력 샘플 절대값이 \( 2^{-126} \) 이상일 때만 활성 처리 중입니다. -
ScriptProcessorNode는 입력 또는 출력이 연결되어 있을 때 활성 처리 중입니다. -
AudioWorkletNode는 해당AudioWorkletProcessor의[[callable process]]가true를 반환하고, active source 플래그가true이거나, 입력으로 연결된AudioNode중 하나라도 활성 처리 중일 때 활성 처리 중입니다. -
그 밖의 모든
AudioNode는 입력으로 연결된AudioNode중 하나라도 활성 처리 중이면 활성 처리 중이 되고, 입력으로부터 받은 활성 처리 중AudioNode가 더 이상 출력에 영향을 주지 않으면 활성 처리 중이 아닙니다.
참고: 이는 테일 타임을 가진 AudioNode도
고려합니다.
활성 처리 중이 아닌 AudioNode는 한
채널의 무음만 출력합니다.
1.5.4. 속성
channelCount, 타입 unsigned long-
channelCount는 노드의 입력 연결에 대해 업믹싱과 다운믹싱에 사용되는 채널 수입니다. 기본값은 2이며, 특정 노드에서는 특별히 결정된 값이 사용됩니다. 입력이 없는 노드에는 이 속성이 영향을 주지 않습니다. 이 값을 0 또는 구현 최대 채널 수를 초과하는 값으로 설정하면, 구현은 반드시NotSupportedError예외를 던져야 합니다.또한 일부 노드는 채널 수에 대해 추가 channelCount 제약을 가집니다:
AudioDestinationNode-
동작은 목적지 노드가
AudioContext또는OfflineAudioContext의 목적지인지에 따라 달라집니다:AudioContext-
채널 수는 1에서
maxChannelCount사이여야 합니다. 이 범위를 벗어나 설정하면IndexSizeError예외를 반드시 던져야 합니다. OfflineAudioContext-
채널 수는 변경할 수 없습니다. 값을 변경하려 하면
InvalidStateError예외를 반드시 던져야 합니다.
AudioWorkletNode-
자세한 내용은 § 1.32.4.3.2 AudioWorkletNodeOptions로 채널 구성를 참고하세요.
ChannelMergerNode-
채널 수는 변경할 수 없으며, 값을 변경하려 하면
InvalidStateError예외를 반드시 던져야 합니다. ChannelSplitterNode-
채널 수는 변경할 수 없으며, 값을 변경하려 하면
InvalidStateError예외를 반드시 던져야 합니다. ConvolverNode-
채널 수는 2를 초과할 수 없으며, 2를 초과하는 값으로 변경하려 하면
NotSupportedError예외를 반드시 던져야 합니다. DynamicsCompressorNode-
채널 수는 2를 초과할 수 없으며, 2를 초과하는 값으로 변경하려 하면
NotSupportedError예외를 반드시 던져야 합니다. PannerNode-
채널 수는 2를 초과할 수 없으며, 2를 초과하는 값으로 변경하려 하면
NotSupportedError예외를 반드시 던져야 합니다. ScriptProcessorNode-
채널 수는 변경할 수 없으며, 값을 변경하려 하면
NotSupportedError예외를 반드시 던져야 합니다. StereoPannerNode-
채널 수는 2를 초과할 수 없으며, 2를 초과하는 값으로 변경하려 하면
NotSupportedError예외를 반드시 던져야 합니다.
이 속성에 대한 자세한 내용은 § 4 채널 업믹싱과 다운믹싱을 참고하세요.
channelCountMode, 타입 ChannelCountMode-
channelCountMode는 노드의 입력 연결에 대해 업믹싱과 다운믹싱 시 채널 수를 어떻게 결정할지 지정합니다. 기본값은 "max"입니다. 입력이 없는 노드에는 이 속성이 영향을 주지 않습니다.또한 일부 노드는 channelCountMode 값에 대해 추가 channelCountMode 제약을 가집니다:
AudioDestinationNode-
AudioDestinationNode가destination노드이면서OfflineAudioContext의 목적지인 경우 channelCountMode는 변경할 수 없습니다. 값을 변경하려 하면InvalidStateError예외를 반드시 던져야 합니다. ChannelMergerNode-
channelCountMode는 "
explicit"에서 변경할 수 없으며, 값을 변경하려 하면InvalidStateError예외를 반드시 던져야 합니다. ChannelSplitterNode-
channelCountMode는 "
explicit"에서 변경할 수 없으며, 값을 변경하려 하면InvalidStateError예외를 반드시 던져야 합니다. ConvolverNode-
channelCountMode를 "
max"로 설정할 수 없으며, 그러한 시도에 대해NotSupportedError예외를 반드시 던져야 합니다. DynamicsCompressorNode-
channelCountMode를 "
max"로 설정할 수 없으며, 그러한 시도에 대해NotSupportedError예외를 반드시 던져야 합니다. PannerNode-
channelCountMode를 "
max"로 설정할 수 없으며, 그러한 시도에 대해NotSupportedError예외를 반드시 던져야 합니다. ScriptProcessorNode-
channelCountMode는 "
explicit"에서 변경할 수 없으며, 값을 변경하려 하면NotSupportedError예외를 반드시 던져야 합니다. StereoPannerNode-
channelCountMode를 "
max"로 설정할 수 없으며, 그러한 시도에 대해NotSupportedError예외를 반드시 던져야 합니다.
이 속성에 대한 자세한 내용은 § 4 채널 업믹싱과 다운믹싱을 참고하세요.
channelInterpretation, 타입 ChannelInterpretation-
channelInterpretation는 노드의 입력 연결에 대해 업믹싱과 다운믹싱 시 개별 채널을 어떻게 처리할지 지정합니다. 기본값은 "speakers"입니다. 입력이 없는 노드에는 이 속성이 영향을 주지 않습니다.또한 일부 노드는 channelInterpretation 값에 대해 추가 channelInterpretation 제약을 가집니다:
ChannelSplitterNode-
channelInterpretation은 "
discrete"에서 변경할 수 없으며, 값을 변경하려 하면InvalidStateError예외를 반드시 던져야 합니다.
이 속성에 대한 자세한 내용은 § 4 채널 업믹싱과 다운믹싱을 참고하세요.
context, 타입 BaseAudioContext, 읽기 전용-
이
AudioNode를 소유하는BaseAudioContext입니다. numberOfInputs, 타입 unsigned long, 읽기 전용-
이
AudioNode로 입력되는 입력 수입니다. 소스 노드의 경우 0입니다. 이 속성은 많은AudioNode타입에서 미리 결정되어 있지만,ChannelMergerNode나AudioWorkletNode처럼 입력 수가 가변적인 노드도 있습니다. numberOfOutputs, 타입 unsigned long, 읽기 전용-
이
AudioNode에서 나오는 출력 수입니다. 이 속성은 일부AudioNode타입에서 미리 결정되어 있지만,ChannelSplitterNode나AudioWorkletNode처럼 출력 수가 가변적인 노드도 있습니다.
1.5.5. 메서드
connect(destinationNode, output, input)-
특정 노드의 한 출력과 다른 특정 노드의 한 입력 사이에는 오직 하나의 연결만 존재할 수 있습니다. 동일한 결합점에 대해 여러 번 연결을 시도해도 무시됩니다.
이 메서드는
destinationAudioNode객체를 반환합니다.AudioNode.connect(destinationNode, output, input) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationNodedestination파라미터는 연결할AudioNode입니다.destination파라미터가 다른AudioContext에서 생성된AudioNode라면InvalidAccessError를 반드시 던져야 합니다. 즉,AudioNode는 서로 다른AudioContext간에 공유할 수 없습니다. 여러AudioNode를 같은AudioNode에 연결할 수 있으며, 이는 채널 업믹싱과 다운믹싱 섹션에서 설명됩니다.outputunsigned long✘ ✔ output파라미터는 연결할AudioNode의 출력 인덱스입니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다. 하나의AudioNode출력은 여러 입력에 연결할 수 있으므로 "팬-아웃"이 지원됩니다.inputinput파라미터는 대상AudioNode의 입력 인덱스입니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다. 하나의AudioNode를 다른AudioNode에 연결하여, 순환(cycle)을 만들 수 있습니다: 한AudioNode가 다른AudioNode에 연결되고, 이것이 다시 첫 번째AudioNode의 입력 또는AudioParam에 연결될 수 있습니다.반환 타입:AudioNode connect(destinationParam, output)-
AudioNode를AudioParam에 연결하여, 해당 파라미터 값을 a-rate 신호로 제어합니다.하나의
AudioNode출력은 여러AudioParam에 여러 번 connect() 호출로 연결할 수 있으므로 "팬-아웃"이 지원됩니다.여러
AudioNode출력은 하나의AudioParam에 여러 번 connect() 호출로 연결할 수 있으므로 "팬-인"이 지원됩니다.AudioParam은 연결된AudioNode출력의 렌더링 오디오 데이터를 받아서, 이미 모노가 아니면 다운믹스하여 모노로 변환 후, 다른 출력들과 함께 믹싱합니다. 마지막으로 내재적 파라미터 값(AudioParam이 오디오 연결 없이 갖는value값)과, 해당 파라미터에 예약된 타임라인 변경도 함께 믹싱합니다.모노로 다운믹스하는 것은
AudioNode의channelCount= 1,channelCountMode= "explicit",channelInterpretation= "speakers"인 경우와 동일합니다.특정 노드의 한 출력과 특정
AudioParam사이에는 오직 하나의 연결만 존재할 수 있으며, 동일한 결합점에 대해 여러 번 연결을 시도해도 무시됩니다.AudioNode.connect(destinationParam, output) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationParamAudioParam✘ ✘ destination파라미터는 연결할AudioParam입니다. 이 메서드는destinationAudioParam객체를 반환하지 않습니다.destinationParam이AudioNode에 속해 있고, 그BaseAudioContext가 이 메서드를 호출한AudioNode를 생성한BaseAudioContext와 다르면InvalidAccessError를 반드시 던져야 합니다.outputunsigned long✘ ✔ output파라미터는 연결할AudioNode의 출력 인덱스입니다.parameter가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect()-
이
AudioNode에서 나가는 모든 연결을 끊습니다.파라미터 없음.반환 타입:undefined disconnect(output)-
이
AudioNode의 특정 출력에서 연결된 모든AudioNode또는AudioParam객체와의 연결을 끊습니다.AudioNode.disconnect(output) 메서드 인자. 파라미터 타입 Nullable Optional 설명 outputunsigned long✘ ✘ 끊을 AudioNode의 출력 인덱스입니다. 해당 출력에서 나가는 모든 연결을 끊습니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect(destinationNode)-
이
AudioNode에서 특정 목적지AudioNode로 가는 모든 출력을 끊습니다.AudioNode.disconnect(destinationNode) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationNodedestinationNode파라미터는 연결을 끊을AudioNode입니다. 해당 목적지로 가는 모든 연결을 끊습니다. 연결이 없으면InvalidAccessError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect(destinationNode, output)-
이
AudioNode의 특정 출력에서 특정 목적지AudioNode의 모든 입력과의 연결을 끊습니다.AudioNode.disconnect(destinationNode, output) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationNodedestinationNode파라미터는 연결을 끊을AudioNode입니다. 해당 출력에서 해당 목적지로 연결이 없으면InvalidAccessError예외를 반드시 던져야 합니다.outputunsigned long✘ ✘ 끊을 AudioNode의 출력 인덱스입니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect(destinationNode, output, input)-
이
AudioNode의 특정 출력에서 특정 목적지AudioNode의 특정 입력과의 연결을 끊습니다.AudioNode.disconnect(destinationNode, output, input) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationNodedestinationNode파라미터는 연결을 끊을AudioNode입니다. 해당 출력에서 해당 목적지의 해당 입력으로의 연결이 없으면InvalidAccessError예외를 반드시 던져야 합니다.outputunsigned long✘ ✘ 끊을 AudioNode의 출력 인덱스입니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.input끊을 대상 AudioNode의 입력 인덱스입니다. 이 파라미터가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect(destinationParam)-
이
AudioNode에서 특정 목적지AudioParam으로 가는 모든 출력을 끊습니다. 이AudioNode가 계산된 파라미터 값에 기여하는 값은 이 작업이 적용되면 0이 됩니다. 내재적 파라미터 값에는 영향이 없습니다.AudioNode.disconnect(destinationParam) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationParamAudioParam✘ ✘ destinationParam파라미터는 연결을 끊을AudioParam입니다. 연결이 없으면InvalidAccessError예외를 반드시 던져야 합니다.반환 타입:undefined disconnect(destinationParam, output)-
이
AudioNode의 특정 출력에서 특정 목적지AudioParam과의 연결을 끊습니다. 이AudioNode가 계산된 파라미터 값에 기여하는 값은 이 작업이 적용되면 0이 됩니다. 내재적 파라미터 값에는 영향이 없습니다.AudioNode.disconnect(destinationParam, output) 메서드 인자. 파라미터 타입 Nullable Optional 설명 destinationParamAudioParam✘ ✘ destinationParam파라미터는 연결을 끊을AudioParam입니다. 연결이 없으면InvalidAccessError예외를 반드시 던져야 합니다.outputunsigned long✘ ✘ 끊을 AudioNode의 출력 인덱스입니다.parameter가 범위를 벗어나면IndexSizeError예외를 반드시 던져야 합니다.반환 타입:undefined
1.5.6.
AudioNodeOptions
이는 모든 AudioNode를
생성할 때 사용할 수 있는 옵션을 지정합니다.
모든 멤버는 선택 사항입니다. 하지만 실제로 각 노드에 사용되는 값은 해당 노드에 따라 달라집니다.
dictionary AudioNodeOptions {unsigned long channelCount ;ChannelCountMode channelCountMode ;ChannelInterpretation channelInterpretation ; };
1.5.6.1. 딕셔너리 AudioNodeOptions
멤버
channelCount, 타입 unsigned long-
channelCount속성에 대한 원하는 채널 수입니다. channelCountMode, 타입 ChannelCountMode-
channelCountMode속성에 대한 원하는 모드입니다. channelInterpretation, 타입 ChannelInterpretation-
channelInterpretation속성에 대한 원하는 모드입니다.
1.6. AudioParam
인터페이스
AudioParam
은 AudioNode의 세부
동작(예: 볼륨)을 제어합니다.
파라미터는 value 속성을 사용해 즉시 특정 값으로 설정할 수 있습니다. 또는 값의 변화를 AudioContext의
currentTime
속성의 시간 좌표계에서 매우 정밀한 시점에 맞춰 예약할 수 있습니다(엔벌로프, 볼륨 페이드, LFO, 필터 스윕, 그레인 윈도 등). 이런 방식으로
임의의 타임라인 기반 자동화 곡선을 모든 AudioParam에
설정할 수 있습니다.
또한 AudioNode의 출력
오디오 신호를 AudioParam에
연결해 내재적 파라미터 값과 합산할 수도 있습니다.
일부 합성 및 처리 AudioNode는
AudioParam
속성을 가지며, 해당 값은 오디오 샘플마다 반드시 반영되어야 합니다. 그 외의 AudioParam는
샘플 단위 정확도가 중요하지 않으므로 값의 변화를 더 느슨하게 샘플링할 수 있습니다. 각 AudioParam마다
a-rate 파라미터(오디오 샘플마다 반드시 반영)인지 k-rate 파라미터인지 명시됩니다.
구현체는 반드시 블록 단위로 처리해야 하며, 각 AudioNode는 한
렌더 퀀텀을 처리합니다.
각 렌더 퀀텀마다 k-rate 파라미터의 값은 첫 번째 샘플 프레임 시점에
샘플링되어 그 블록 전체에서 사용됩니다. a-rate
파라미터는 블록 내 모든 샘플 프레임마다 샘플링됩니다.
AudioParam마다
automationRate 속성을 "a-rate"
또는 "k-rate"로
설정해 동작 속도를 제어할 수 있습니다.
개별 AudioParam의
설명을 참고하세요.
각 AudioParam
에는 minValue
와 maxValue
속성이 포함되어 있으며, 이 두 속성은 파라미터의 단순 명목 범위를 구성합니다. 실제로 파라미터의 값은 \([\mathrm{minValue},
\mathrm{maxValue}]\) 범위로 클램프(clamp)됩니다. 자세한 내용은 § 1.6.3 값의 계산을 참조하세요.
많은 AudioParam에
대해 minValue와
maxValue는
최대 허용 범위로 설정하는 것이 권장됩니다. 이때 maxValue는
최대 단정도
float 값인 3.4028235e38이어야 합니다.
(단, JavaScript에서는 IEEE-754 배정도 float만 지원하므로 3.4028234663852886e38로 작성해야 합니다.)
마찬가지로 minValue는
최소 단정도
float 값인 -3.4028235e38(즉, 최대 단정도 float의 음수)로 설정해야 합니다.
(JavaScript에서는 -3.4028234663852886e38로 작성해야 합니다.)
AudioParam
은 0개 이상의 자동화 이벤트
리스트를 유지합니다. 각 자동화 이벤트는 해당 파라미터 값이 특정 시간 범위에 어떻게 변화하는지 명시하며, 자동화 이벤트 시간을 AudioContext의
currentTime
시간 좌표계로 사용합니다. 자동화 이벤트 리스트는 이벤트 시간 오름차순으로 관리됩니다.
특정 자동화 이벤트의 동작은 AudioContext의
현재 시간, 해당 이벤트와 리스트 내 인접 이벤트의 자동화 이벤트 시간에 따라 결정됩니다. 다음 자동화 메서드들은 이벤트 리스트에 각 메서드에 특화된
타입의 새 이벤트를 추가합니다:
-
setValueAtTime()-SetValue -
linearRampToValueAtTime()-LinearRampToValue -
exponentialRampToValueAtTime()-ExponentialRampToValue -
setTargetAtTime()-SetTarget -
setValueCurveAtTime()-SetValueCurve
이 메서드를 호출할 때 적용되는 규칙은 다음과 같습니다:
-
자동화 이벤트 시간은 현행 샘플레이트와 관련하여 양자화되지 않습니다. 곡선 및 램프를 결정하는 공식은 이벤트 예약 시 입력한 정확한 실수 시간에 적용됩니다.
-
이미 한 시점에 하나 이상의 이벤트가 있을 때, 새 이벤트를 추가하면 해당 이벤트들 뒤에, 그 이후 시점의 이벤트들 앞에 리스트에 위치하게 됩니다.
-
setValueCurveAtTime()이 시간 \(T\)와 지속 시간 \(D\)로 호출되고, \(T\)보다 크고 \(T + D\)보다 작은 시간에 다른 이벤트가 있다면NotSupportedError예외를 반드시 던져야 합니다. 즉, 값 곡선이 포함된 기간에 다른 이벤트를 예약하는 것은 허용되지 않지만, 곡선이 다른 이벤트와 정확히 같은 시간에 예약되는 것은 허용됩니다. -
마찬가지로, 어떤 자동화 메서드가 \([T, T+D)\) 구간 내(여기서 \(T\)는 곡선의 시작, \(D\)는 지속 시간) 호출되면
NotSupportedError예외를 반드시 던져야 합니다.
참고: AudioParam
속성은 value
속성을 제외하고 모두 읽기 전용입니다.
AudioParam의
automation rate은 automationRate
속성으로 다음 값 중 하나로 설정할 수 있습니다. 단, 일부 AudioParam은
automation rate 변경에 제약이 있습니다.
enum {AutomationRate "a-rate" ,"k-rate" };
| 열거값 | 설명 |
|---|---|
"a-rate"
| 이 AudioParam은
a-rate 처리에 사용됩니다.
|
"k-rate"
| 이 AudioParam은
k-rate 처리에 사용됩니다.
|
각 AudioParam에는
내부 슬롯 [[current value]]이 있으며,
초기값은 해당 AudioParam의
defaultValue입니다.
[Exposed =Window ]interface AudioParam {attribute float value ;attribute AutomationRate automationRate ;readonly attribute float defaultValue ;readonly attribute float minValue ;readonly attribute float maxValue ;AudioParam setValueAtTime (float ,value double );startTime AudioParam linearRampToValueAtTime (float ,value double );endTime AudioParam exponentialRampToValueAtTime (float ,value double );endTime AudioParam setTargetAtTime (float ,target double ,startTime float );timeConstant AudioParam setValueCurveAtTime (sequence <float >,values double ,startTime double );duration AudioParam cancelScheduledValues (double );cancelTime AudioParam cancelAndHoldAtTime (double ); };cancelTime
1.6.1. 속성
automationRate, 타입 AutomationRate-
이
AudioParam의 자동화 속도입니다. 기본값은 실제AudioParam에 따라 다르며, 각AudioParam설명을 참고하세요.일부 노드에는 아래와 같이 추가 automation rate 제약이 있습니다:
AudioBufferSourceNode-
AudioParam의playbackRate와detune는 반드시 "k-rate"이어야 합니다. 속도를 "a-rate"로 변경하면InvalidStateError예외를 반드시 던져야 합니다. DynamicsCompressorNode-
AudioParam의threshold,knee,ratio,attack,release는 반드시 "k-rate"이어야 합니다. 속도를 "a-rate"로 변경하면InvalidStateError예외를 반드시 던져야 합니다. PannerNode-
panningModel이 "HRTF"이면,PannerNode의 모든AudioParam에 대한automationRate설정은 무시됩니다. 마찬가지로AudioListener의 모든AudioParam에 대한automationRate설정도 무시됩니다. 이 경우AudioParam은automationRate가 "k-rate"로 설정된 것과 동일하게 동작합니다.
defaultValue, 타입 float, 읽기 전용-
value속성의 초기값입니다. maxValue, 타입 float, 읽기 전용-
이 파라미터가 가질 수 있는 명목상 최대값입니다.
minValue와 함께 이 파라미터의 명목 범위를 구성합니다. minValue, 타입 float, 읽기 전용-
이 파라미터가 가질 수 있는 명목상 최소값입니다.
maxValue와 함께 이 파라미터의 명목 범위를 구성합니다. value, 타입 float-
파라미터의 부동소수점 값입니다. 이 속성은
defaultValue로 초기화됩니다.이 속성을 가져오면
[[current value]]슬롯의 내용을 반환합니다. 반환값 계산 알고리즘은 § 1.6.3 값의 계산을 참고하세요.이 속성을 설정하면 요청한 값이
[[current value]]슬롯에 할당되고, setValueAtTime()가 현재AudioContext의currentTime과[[current value]]로 호출됩니다.setValueAtTime()에서 던질 예외는 이 속성에 값을 설정할 때도 동일하게 던져집니다.
1.6.2. 메서드
cancelAndHoldAtTime(cancelTime)-
이 메서드는
cancelScheduledValues()와 유사하게cancelTime이상의 시간에 예약된 모든 파라미터 변화를 취소합니다. 추가적으로,cancelTime시점에 발생할 자동화 값이 이후 다른 자동화 이벤트가 등록될 때까지 계속 유지됩니다.자동화가 실행되고
cancelAndHoldAtTime()호출 이후,cancelTime이전에 자동화가 도입될 수 있는 경우 타임라인의 동작은 다소 복잡합니다.cancelAndHoldAtTime()의 동작은 다음 알고리즘에 따라 정의됩니다.\(t_c\)를cancelTime의 값으로 둡니다.-
\(E_1\)을 시간 \(t_1\)의 이벤트(있는 경우)로 둡니다. 여기서 \(t_1\)은 \(t_1 \le t_c\)를 만족하는 가장 큰 값입니다.
-
\(E_2\)를 시간 \(t_2\)의 이벤트(있는 경우)로 둡니다. 여기서 \(t_2\)는 \(t_c \lt t_2\)를 만족하는 가장 작은 값입니다.
-
\(E_2\)가 존재한다면:
-
\(E_2\)가 선형 또는 지수 램프라면,
-
\(E_2\)를 \(t_c\)에서 끝나는 동일 종류의 램프로 재작성하며, 종료값은 원래 램프의 \(t_c\) 시점 값으로 합니다.

-
5단계로 이동.
-
-
그 외에는 4단계로 이동.
-
-
\(E_1\)이 존재한다면:
-
\(E_1\)이
setTarget이벤트라면,-
\(t_c\) 시점에
setTarget이 갖게 될 값으로setValueAtTime이벤트를 암묵적으로 삽입합니다.
-
5단계로 이동.
-
-
\(E_1\)이 시작 시간 \(t_3\)와 지속시간 \(d\)를 갖는
setValueCurve이벤트라면,-
\(t_c \gt t_3 + d\)라면 5단계로 이동합니다.
-
그 외에는,
-
이 이벤트를 시작 시간 \(t_3\)와 새 지속시간 \(t_c-t_3\)로
setValueCurve이벤트로 대체합니다. 단, 실제로는 기존 곡선과 동일한 결과가 나오도록 해야 하며, 새 지속시간으로 계산하면 값이 달라질 수 있으므로 반드시 원래 곡선의 샘플링 결과와 같아야 합니다.
-
5단계로 이동.
-
-
-
-
\(t_c\)보다 큰 시간의 모든 이벤트를 제거합니다.
이벤트가 추가되지 않으면,
cancelAndHoldAtTime()이후 자동화 값은 원래 타임라인이 \(t_c\)에서 갖는 상수값입니다.AudioParam.cancelAndHoldAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 cancelTimedouble✘ ✘ 이 시점 이후 예약된 파라미터 변화가 모두 취소됩니다. AudioContext의currentTime과 동일한 시간 좌표계의 값입니다.RangeError예외는cancelTime이 음수일 때 반드시 던져야 합니다.cancelTime이currentTime보다 작으면currentTime으로 클램핑됩니다.반환 타입:AudioParam -
cancelScheduledValues(cancelTime)-
cancelTime이상인 모든 예약된 파라미터 변화를 취소합니다. 예약된 변화를 취소한다는 것은 이벤트 리스트에서 이벤트를 삭제하는 것입니다.automation event time이cancelTime보다 작은 활성 자동화도 취소되며, 원래 값이 즉시 복원되어 불연속이 발생할 수 있습니다.cancelAndHoldAtTime()로 예약된 hold 값도 hold 시간이cancelTime이후라면 삭제됩니다.setValueCurveAtTime()의 경우, \(T_0\)와 \(T_D\)를 해당 이벤트의startTime과duration으로 둡니다. 만약cancelTime이 \([T_0, T_0 + T_D]\) 범위 내에 있다면 해당 이벤트는 타임라인에서 제거됩니다.AudioParam.cancelScheduledValues() 메서드 인자. 파라미터 타입 Nullable Optional 설명 cancelTimedouble✘ ✘ 이 시점 이후 예약된 파라미터 변화를 모두 취소합니다. AudioContext의currentTime과 동일한 시간 좌표계의 값입니다.RangeError예외는cancelTime이 음수일 때 반드시 던져야 합니다.cancelTime이currentTime보다 작으면currentTime으로 클램핑됩니다.반환 타입:AudioParam exponentialRampToValueAtTime(value, endTime)-
이전 예약 값에서 지정된 값까지 지수적으로 연속적으로 파라미터 값을 변화시키도록 예약합니다. 필터 주파수, 재생속도 등은 인간의 청각 특성 때문에 지수적으로 변경하는 것이 가장 자연스럽습니다.
\(T_0 \leq t < T_1\) 구간(여기서 \(T_0\)은 이전 이벤트 시간, \(T_1\)은
endTime파라미터) 동안의 값은 다음과 같이 계산됩니다:$$ v(t) = V_0 \left(\frac{V_1}{V_0}\right)^\frac{t - T_0}{T_1 - T_0} $$여기서 \(V_0\)는 \(T_0\) 시점 값이고, \(V_1\)은
value파라미터입니다. \(V_0\), \(V_1\)가 부호가 다르거나, \(V_0\)가 0이면 \(v(t) = V_0\)로 유지됩니다.즉, 0으로의 지수 램프는 불가능합니다. 적절한 타임상수를 사용한
setTargetAtTime()으로 근사할 수 있습니다.이벤트 이후 추가 이벤트가 없으면 \(t \geq T_1\)에 대해 \(v(t) = V_1\)입니다.
이벤트 앞에 이벤트가 없다면,
setValueAtTime(value, currentTime)이 호출된 것처럼 동작합니다.value는 현재 속성 값,currentTime은 메서드 호출 시점의 컨텍스트 시간입니다.앞선 이벤트가
SetTarget이면, \(T_0\)와 \(V_0\)는 현재SetTarget자동화의 시간과 값으로 선택됩니다.SetTarget이벤트가 시작되지 않았다면 \(T_0\)는 이벤트 시작 시간, \(V_0\)는 시작 직전 값입니다. 이 경우ExponentialRampToValue이벤트가SetTarget을 대체합니다.SetTarget이 시작된 경우 \(T_0\)는 현재 시간, \(V_0\)는 해당 시점의SetTarget값입니다. 두 경우 모두 곡선은 연속입니다.AudioParam.exponentialRampToValueAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 valuefloat✘ ✘ 파라미터가 지정 시간에 지수적으로 변화할 목표 값입니다. RangeError예외는 값이 0이면 반드시 던져야 합니다.endTimedouble✘ ✘ 지수 램프가 끝나는 시간(초 단위). AudioContext의currentTime과 동일한 시간 좌표계입니다.RangeError예외는endTime이 음수거나 유한한 수가 아니면 반드시 던져야 합니다. endTime이currentTime보다 작으면currentTime으로 클램핑됩니다.반환 타입:AudioParam linearRampToValueAtTime(value, endTime)-
이전 예약 값에서 지정된 값까지 선형적으로 연속적으로 파라미터 값을 변화시키도록 예약합니다.
\(T_0 \leq t < T_1\) 구간(여기서 \(T_0\)은 이전 이벤트 시간, \(T_1\)은
endTime파라미터) 동안의 값은 다음과 같이 계산됩니다:$$ v(t) = V_0 + (V_1 - V_0) \frac{t - T_0}{T_1 - T_0} $$여기서 \(V_0\)는 \(T_0\) 시점 값이고, \(V_1\)은
value파라미터입니다.이벤트 이후 추가 이벤트가 없으면 \(t \geq T_1\)에 대해 \(v(t) = V_1\)입니다.
이벤트 앞에 이벤트가 없다면,
setValueAtTime(value, currentTime)이 호출된 것처럼 동작합니다.value는 현재 속성 값,currentTime은 메서드 호출 시점의 컨텍스트 시간입니다.앞선 이벤트가
SetTarget이면, \(T_0\)와 \(V_0\)는 현재SetTarget자동화의 시간과 값으로 선택됩니다.SetTarget이벤트가 시작되지 않았다면 \(T_0\)는 이벤트 시작 시간, \(V_0\)는 시작 직전 값입니다. 이 경우LinearRampToValue이벤트가SetTarget을 대체합니다.SetTarget이 시작된 경우 \(T_0\)는 현재 시간, \(V_0\)는 해당 시점의SetTarget값입니다. 두 경우 모두 곡선은 연속입니다.AudioParam.linearRampToValueAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 valuefloat✘ ✘ 파라미터가 지정 시간에 선형적으로 변화할 목표 값입니다. endTimedouble✘ ✘ 자동화가 끝나는 시간(초 단위). AudioContext의currentTime과 동일한 시간 좌표계입니다.RangeError예외는endTime이 음수거나 유한한 수가 아니면 반드시 던져야 합니다. endTime이currentTime보다 작으면currentTime으로 클램핑됩니다.반환 타입:AudioParam setTargetAtTime(target, startTime, timeConstant)-
지정한 시간에 지정한 타임상수(rate)로 목표 값에 지수적으로 접근하기 시작합니다. ADSR 엔벌로프의 "감쇠" 및 "릴리즈" 구현에 유용합니다. 파라미터 값은 지정 시간에 즉시 목표 값으로 변하지 않고 점진적으로 목표 값에 도달합니다.
구간: \(T_0 \leq t\), \(T_0\)는
startTime파라미터:$$ v(t) = V_1 + (V_0 - V_1)\, e^{-\left(\frac{t - T_0}{\tau}\right)} $$여기서 \(V_0\)는 \(T_0\) 시점의 초기값(
[[current value]]), \(V_1\)은target, \(\tau\)는timeConstant입니다.이후
LinearRampToValue나ExponentialRampToValue이벤트가 오면 각각linearRampToValueAtTime()또는exponentialRampToValueAtTime()설명을 참조. 그 외 이벤트에서는 다음 이벤트 시간에SetTarget이 종료됩니다.AudioParam.setTargetAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 targetfloat✘ ✘ 파라미터가 지정 시간에 변화하기 시작할 목표 값입니다. startTimedouble✘ ✘ 지수 접근이 시작되는 시간(초 단위). AudioContext의currentTime과 동일한 시간 좌표계입니다.RangeError예외는start가 음수이거나 유한한 수가 아니면 반드시 던져야 합니다. startTime이currentTime보다 작으면currentTime으로 클램핑됩니다.timeConstantfloat✘ ✘ 목표 값으로 지수적으로 접근하는 1차 필터(지수) 타임상수 값입니다. 값이 클수록 변이가 느려집니다. 값은 음수가 아니어야 하며, 음수면 RangeError예외를 반드시 던져야 합니다.timeConstant이 0이면 출력값은 즉시 목표 값으로 점프합니다. 더 정확히는, timeConstant은 1차 선형 연속 시간 불변 시스템이 step 입력(0에서 1로)에서 값 1 - 1/e(약 63.2%)에 도달하는 데 걸리는 시간입니다.반환 타입:AudioParam setValueAtTime(value, startTime)-
지정한 시간에 파라미터 값을 예약합니다.
이 이벤트 이후 추가 이벤트가 없으면 \(t \geq T_0\)에서 \(v(t) = V\)입니다. 여기서 \(T_0\)는
startTime, \(V\)는value입니다. 즉, 값은 상수로 유지됩니다.이
SetValue이벤트 다음 이벤트(\(T_1\))가LinearRampToValue또는ExponentialRampToValue타입이 아니면, \(T_0 \leq t < T_1\)에서$$ v(t) = V $$즉, 해당 구간 동안 값은 상수로 유지되어 "계단" 함수 생성이 가능합니다.
SetValue 다음 이벤트가
LinearRampToValue또는ExponentialRampToValue라면 각각linearRampToValueAtTime()또는exponentialRampToValueAtTime()설명을 참조.AudioParam.setValueAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 valuefloat✘ ✘ 파라미터가 지정 시간에 변화할 값입니다. startTimedouble✘ ✘ 파라미터가 지정 값으로 바뀌는 시간(초 단위). BaseAudioContext의currentTime과 동일한 시간 좌표계입니다.RangeError예외는startTime이 음수이거나 유한한 수가 아니면 반드시 던져야 합니다. startTime이currentTime보다 작으면currentTime으로 클램핑됩니다.반환 타입:AudioParam setValueCurveAtTime(values, startTime, duration)-
지정 시간부터 지정한 기간 동안 임의의 값 배열을 파라미터 값 곡선으로 예약합니다. 값 개수는 지정한 기간에 맞춰 스케일링됩니다.
\(T_0\)를
startTime, \(T_D\)를duration, \(V\)를values배열, \(N\)을values배열 길이라 하면, \(T_0 \le t < T_0 + T_D\) 구간에서$$ \begin{align*} k &= \left\lfloor \frac{N - 1}{T_D}(t-T_0) \right\rfloor \\ \end{align*} $$\(v(t)\)는 \(V[k]\)와 \(V[k+1]\) 사이를 선형 보간하여 계산합니다.
곡선 구간이 끝난 후(\(t \ge T_0 + T_D\)), 값은 곡선의 마지막 값으로 유지되며, 이후에 다른 자동화 이벤트가 오면 값이 변경됩니다.
내부적으로 \(T_0 + T_D\) 시점에 \(V[N-1]\) 값으로
setValueAtTime()이 암묵적으로 호출되어 이후 자동화가 곡선 종료값에서 시작하도록 합니다.AudioParam.setValueCurveAtTime() 메서드 인자. 파라미터 타입 Nullable Optional 설명 valuessequence<float>✘ ✘ 파라미터 값 곡선을 나타내는 float 값 배열. 지정한 시간과 기간에 적용됩니다. 메서드 호출 시 내부적으로 곡선 복사본이 생성되므로, 이후 배열 수정은 AudioParam에 영향을 주지 않습니다.InvalidStateError예외는 배열 길이가 2 미만이면 반드시 던져야 합니다.startTimedouble✘ ✘ 값 곡선이 적용될 시작 시간(초 단위). AudioContext의currentTime과 동일한 시간 좌표계입니다.RangeError예외는startTime이 음수이거나 유한한 수가 아니면 반드시 던져야 합니다. startTime이currentTime보다 작으면currentTime으로 클램핑됩니다.durationdouble✘ ✘ startTime이후 값이 계산될 기간(초 단위).RangeError예외는duration이 0 이하이거나 유한한 수가 아니면 반드시 던져야 합니다.반환 타입:AudioParam
1.6.3. 값의 계산
AudioParam에는
두 가지 종류가 있습니다.
단순 파라미터와 복합 파라미터입니다. 단순 파라미터(기본값)은
AudioNode의
최종 오디오 출력 계산에 단독으로 사용됩니다.
복합 파라미터는 여러 AudioParam을
함께 사용해 값을 계산하고,
그 값을 AudioNode의 출력
계산에 입력값으로 사용합니다.
computedValue는 오디오 DSP를 제어하는 최종 값이며, 오디오 렌더링 스레드에서 각 렌더링 시간 퀀텀마다 계산됩니다.
AudioParam의
값 계산은 두 부분으로 구성됩니다:
-
paramComputedValue는 오디오 DSP를 최종적으로 제어하는 값으로, 각 렌더 퀀텀에서 오디오 렌더링 스레드가 계산합니다.
이 값들은 다음과 같이 계산되어야 합니다:
-
paramIntrinsicValue는 각 시점마다 직접
value속성으로 설정된 값이거나, 해당 시점보다 이전 또는 같은 시간에 자동화 이벤트가 있으면 그 이벤트들로부터 계산된 값입니다. 자동화 이벤트가 특정 시간 범위에서 제거되면, paramIntrinsicValue 값은 변경되지 않고 이전 값을 유지합니다. 이후value속성이 직접 설정되거나, 해당 시간 범위에 자동화 이벤트가 추가될 때까지 유지됩니다. -
이 렌더 퀀텀의 시작에서
[[current value]]를 paramIntrinsicValue 값으로 설정합니다. -
paramComputedValue는 paramIntrinsicValue 값과 입력 AudioParam 버퍼 값을 합산한 값입니다. 합이
NaN이면, 합 대신defaultValue값을 사용합니다. -
이
AudioParam이 복합 파라미터라면, 다른AudioParam들과 함께 최종 값을 계산합니다. -
computedValue를 paramComputedValue로 설정합니다.
computedValue의 명목 범위는
해당 파라미터가 실질적으로 가질 수 있는 최저/최고 값입니다. 단순 파라미터의 computedValue는 파라미터의 단순 명목 범위로 클램핑됩니다. 복합 파라미터의 최종 값은 여러
AudioParam
값으로 계산한 뒤 명목 범위로 클램핑됩니다.
자동화 메서드를 사용할 때도 클램핑이 적용됩니다. 다만, 자동화는 클램핑 없이 실행되는 것처럼 동작하고, 실제 출력에 값을 적용할 때만 위에서 명시한 대로 클램핑됩니다.
N. p. setValueAtTime( 0 , 0 ); N. p. linearRampToValueAtTime( 4 , 1 ); N. p. linearRampToValueAtTime( 0 , 2 );
초기 곡선 기울기는 4이며, 값이 최대값 1에 도달하면 출력은 그대로 유지됩니다. 마지막에 2 근처에서 곡선 기울기는 -4가 됩니다. 아래 그래프에서 점선은 클리핑이 없을 때 예상 동작, 실선은 명목 범위에 따라 클리핑된 실제 AudioParam 동작을 나타냅니다.
1.6.4. AudioParam
자동화 예시
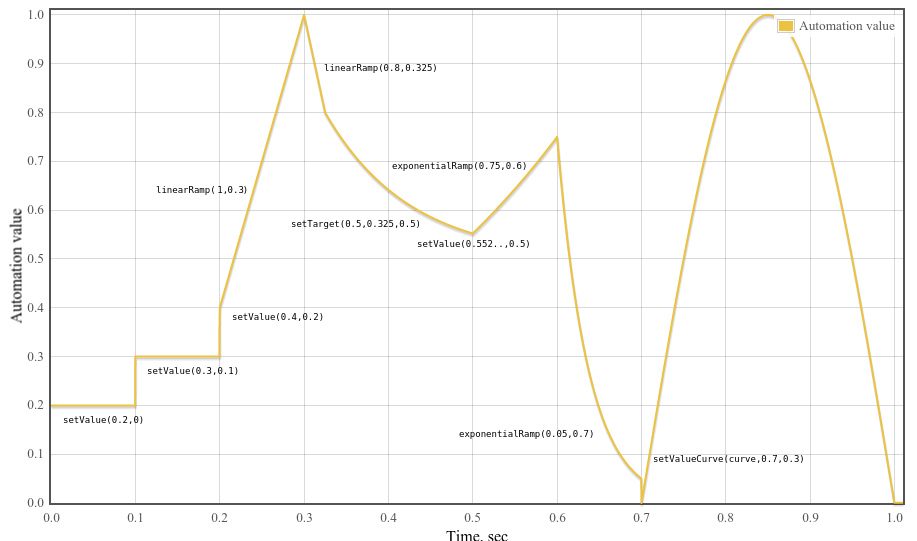
const curveLength= 44100 ; const curve= new Float32Array( curveLength); for ( const i= 0 ; i< curveLength; ++ i) curve[ i] = Math. sin( Math. PI* i/ curveLength); const t0= 0 ; const t1= 0.1 ; const t2= 0.2 ; const t3= 0.3 ; const t4= 0.325 ; const t5= 0.5 ; const t6= 0.6 ; const t7= 0.7 ; const t8= 1.0 ; const timeConstant= 0.1 ; param. setValueAtTime( 0.2 , t0); param. setValueAtTime( 0.3 , t1); param. setValueAtTime( 0.4 , t2); param. linearRampToValueAtTime( 1 , t3); param. linearRampToValueAtTime( 0.8 , t4); param. setTargetAtTime( .5 , t4, timeConstant); // t5 시점에서 setTargetAtTime 값 계산 후, 다음 지수 자동화가 불연속 없이 시작되도록 // 스펙에 따라 아래와 같이 계산됨 // v(t) = 0.5 + (0.8 - 0.5)*exp(-(t-t4)/timeConstant) // 따라서 v(t5) = 0.5 + (0.8 - 0.5)*exp(-(t5-t4)/timeConstant) param. setValueAtTime( 0.5 + ( 0.8 - 0.5 ) * Math. exp( - ( t5- t4) / timeConstant), t5); param. exponentialRampToValueAtTime( 0.75 , t6); param. exponentialRampToValueAtTime( 0.05 , t7); param. setValueCurveAtTime( curve, t7, t8- t7);
1.7. AudioScheduledSourceNode
인터페이스
이 인터페이스는 AudioBufferSourceNode,
ConstantSourceNode,
OscillatorNode
등 소스 노드의 공통 기능을 나타냅니다.
소스를 시작하기 전(start()
호출 전)에는
소스 노드는 반드시 무음(0)을 출력해야 합니다. 소스를 중지한 후(stop()
호출 후)에도 반드시 무음(0)을 출력해야 합니다.
AudioScheduledSourceNode
는 직접 인스턴스화할 수 없으며,
각 소스 노드의 구체적 인터페이스에서 확장됩니다.
AudioScheduledSourceNode
는 연결된 BaseAudioContext의
currentTime이
해당 AudioScheduledSourceNode의
시작 시간 이상,
중지 시간 미만일 때 재생 중이라 합니다.
AudioScheduledSourceNode는
내부적으로 불리언 슬롯
[[source started]]를
갖고,
초기값은 false입니다.
[Exposed =Window ]interface AudioScheduledSourceNode :AudioNode {attribute EventHandler onended ;undefined start (optional double when = 0);undefined stop (optional double when = 0); };
1.7.1. 속성
onended, 타입 EventHandler-
AudioScheduledSourceNode노드 타입에서ended이벤트 타입의 이벤트 핸들러를 설정하는 속성입니다. 소스 노드가 재생을 멈추면(구체 노드에서 결정),Event인터페이스를 사용하는 이벤트가 이벤트 핸들러로 디스패치됩니다.모든
AudioScheduledSourceNode에서,ended이벤트는stop()로 결정된 중지 시간이 도달할 때 디스패치됩니다.AudioBufferSourceNode에서는duration이 도달하거나 전체buffer가 모두 재생되었을 때에도 이벤트가 디스패치됩니다.
1.7.2. 메서드
start(when)-
정확한 시점에 사운드 재생을 예약합니다.
이 메서드가 호출되면 다음 단계를 실행합니다:-
이
AudioScheduledSourceNode의 내부 슬롯[[source started]]가 true면,InvalidStateError예외를 반드시 던져야 합니다. -
아래 파라미터 제약 조건으로 인해 던져야 하는 오류가 있는지 확인합니다. 이 단계에서 예외가 발생하면 이후 단계를 중단합니다.
-
이
AudioScheduledSourceNode의 내부 슬롯[[source started]]를true로 설정합니다. -
컨트롤 메시지 큐잉을 통해
AudioScheduledSourceNode시작을 예약하며, 파라미터 값도 메시지에 포함합니다. -
다음 조건을 모두 만족할 때만 연결된
AudioContext에 렌더링 스레드 시작을 위한 컨트롤 메시지를 전송합니다:-
컨텍스트의
[[control thread state]]가 "suspended"입니다. -
컨텍스트가 시작 허용됨 상태입니다.
-
[[suspended by user]]플래그가false입니다.
참고: 이로 인해
start()가 현재 시작 허용됨 상태이지만, 이전에 시작이 차단된AudioContext도 시작할 수 있습니다. -
AudioScheduledSourceNode.start(when) 메서드 인자. 파라미터 타입 Nullable Optional 설명 whendouble✘ ✔ when파라미터는 사운드가 몇 초 후 재생을 시작할지 지정합니다.AudioContext의currentTime과 동일한 시간 좌표계입니다. 사운드의 시작 시간에 따라AudioScheduledSourceNode의 출력 신호가 달라질 경우,when의 정확한 값이 샘플 프레임으로 반올림 없이 항상 사용됩니다. 0을 지정하거나currentTime보다 작은 값을 지정하면 즉시 재생이 시작됩니다.RangeError예외는when이 음수일 때 반드시 던져야 합니다.반환 타입:undefined -
stop(when)-
정확한 시점에 사운드 재생을 중지하도록 예약합니다.
stop이 이미 호출된 후 다시 호출하면, 마지막 호출만 적용됩니다. 이전 호출에서 지정된 중지 시간은 적용되지 않으며, 버퍼가 이미 멈췄다면 이후stop호출은 아무 효과도 없습니다. 중지 시간이 시작 시간보다 먼저 도달하면 사운드는 재생되지 않습니다.이 메서드가 호출되면 다음 단계를 실행합니다:-
이
AudioScheduledSourceNode의 내부 슬롯[[source started]]가true가 아니면,InvalidStateError예외를 반드시 던져야 합니다. -
아래 파라미터 제약 조건으로 인해 던져야 하는 오류가 있는지 확인합니다.
-
컨트롤 메시지 큐잉을 통해
AudioScheduledSourceNode중지를 예약하며, 파라미터 값도 메시지에 포함합니다.
이 노드가AudioBufferSourceNode라면, 컨트롤 메시지를 실행해AudioBufferSourceNode를 중지시키는 것은 재생 알고리즘에서handleStop()함수를 호출하는 것을 의미합니다.AudioScheduledSourceNode.stop(when) 메서드 인자. 파라미터 타입 Nullable Optional 설명 whendouble✘ ✔ when파라미터는 소스가 몇 초 후 중지될지 지정합니다.AudioContext의currentTime과 동일한 시간 좌표계입니다. 0을 지정하거나currentTime보다 작은 값을 지정하면 즉시 중지됩니다.RangeError예외는when이 음수일 때 반드시 던져야 합니다.반환 타입:undefined -
1.8. AnalyserNode
인터페이스
이 인터페이스는 실시간 주파수 및 시간 영역 분석 정보를 제공할 수 있는 노드를 나타냅니다. 오디오 스트림은 입력에서 출력으로 아무런 처리 없이 전달됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | 이 출력은 연결하지 않아도 됩니다. |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
[Exposed =Window ]interface AnalyserNode :AudioNode {constructor (BaseAudioContext ,context optional AnalyserOptions = {});options undefined getFloatFrequencyData (Float32Array );array undefined getByteFrequencyData (Uint8Array );array undefined getFloatTimeDomainData (Float32Array );array undefined getByteTimeDomainData (Uint8Array );array attribute unsigned long fftSize ;readonly attribute unsigned long frequencyBinCount ;attribute double minDecibels ;attribute double maxDecibels ;attribute double smoothingTimeConstant ; };
1.8.1. 생성자
AnalyserNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option과 함께 호출되면, 사용자 에이전트는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.AnalyserNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 AnalyserNode가 연결될BaseAudioContext입니다.optionsAnalyserOptions✘ ✔ 이 AnalyserNode의 초기 파라미터 값(선택 사항).
1.8.2. 속성
fftSize, 타입 unsigned long-
주파수 영역 분석을 위한 FFT 크기(샘플 프레임 단위). 이 값은 32~32768 범위의 2의 거듭제곱이어야 하며, 그렇지 않으면
IndexSizeError예외를 반드시 던져야 합니다. 기본값은 2048입니다. 큰 FFT 크기는 계산 비용이 높을 수 있습니다.fftSize값이 변경되면,getByteFrequencyData()및getFloatFrequencyData()등 주파수 데이터 스무딩과 관련된 모든 상태가 리셋됩니다. 즉, 이전 블록(\(\hat{X}_{-1}[k]\))은 모든 \(k\)에 대해 0으로 설정됩니다(시간 평활화 참조).fftSize가 증가하면, 현재 시간 영역 데이터는 과거 프레임까지 확장되어야 하며,AnalyserNode는 반드시 최근 32768 샘플 프레임 전체를 내부적으로 유지해야 합니다. 현재 시간 영역 데이터는 그중 최근fftSize샘플 프레임입니다. frequencyBinCount, 타입 unsigned long, 읽기 전용-
FFT 크기의 절반.
maxDecibels, 타입 double-
FFT 분석 데이터를 부호 없는 바이트 값으로 변환할 때 스케일링 범위에서 최대 파워 값. 기본값은 -30 입니다. 이 속성 값이
minDecibels이하로 설정되면IndexSizeError예외를 반드시 던져야 합니다. minDecibels, 타입 double-
FFT 분석 데이터를 부호 없는 바이트 값으로 변환할 때 스케일링 범위에서 최소 파워 값. 기본값은 -100 입니다. 이 속성 값이
maxDecibels이상으로 설정되면IndexSizeError예외를 반드시 던져야 합니다. smoothingTimeConstant, 타입 double-
0~1 범위의 값으로, 0은 직전 분석 프레임과의 시간 평균이 없는 상태를 의미합니다. 기본값은 0.8입니다. 이 속성 값이 0 미만 또는 1 초과로 설정되면
IndexSizeError예외를 반드시 던져야 합니다.
1.8.3. 메서드
getByteFrequencyData(array)-
현재 주파수 데이터를 array에 기록합니다. array의 byte length가
frequencyBinCount보다 작으면 초과된 요소는 버려집니다. array의 byte length가frequencyBinCount보다 크면 초과된 요소는 무시됩니다. 가장 최근의fftSize프레임이 주파수 데이터를 계산하는 데 사용됩니다.동일 렌더 퀀텀 내에서
getByteFrequencyData()또는getFloatFrequencyData()를 여러 번 호출하면, 현재 주파수 데이터가 갱신되지 않고, 이전에 계산된 데이터가 반환됩니다.부호 없는 바이트 배열에 저장되는 값은 다음과 같이 계산됩니다. \(Y[k]\)를 현재 주파수 데이터라고 할 때, 바이트 값 \(b[k]\)는
$$ b[k] = \left\lfloor \frac{255}{\mbox{dB}_{max} - \mbox{dB}_{min}} \left(Y[k] - \mbox{dB}_{min}\right) \right\rfloor $$여기서 \(\mbox{dB}_{min}\)은
minDecibels이고, \(\mbox{dB}_{max}\)는maxDecibels입니다. \(b[k]\)가 0~255 범위를 벗어나면, \(b[k]\)는 해당 범위로 클리핑됩니다.AnalyserNode.getByteFrequencyData() 메서드 인자. 파라미터 타입 Nullable Optional 설명 arrayUint8Array✘ ✘ 주파수 영역 분석 데이터가 복사될 파라미터입니다. 반환 타입:undefined getByteTimeDomainData(array)-
현재 시간 영역 데이터(파형 데이터)를 array에 기록합니다. array의 바이트 길이가
fftSize보다 작으면 초과 요소는 버려집니다. array의 바이트 길이가fftSize보다 크면 초과 요소는 무시됩니다. 가장 최근fftSize프레임을 사용하여 바이트 데이터를 계산합니다.부호 없는 바이트 배열에 저장되는 값은 다음과 같이 계산됩니다. \(x[k]\)를 시간 영역 데이터라 할 때, 바이트 값 \(b[k]\)는
$$ b[k] = \left\lfloor 128(1 + x[k]) \right\rfloor. $$\(b[k]\)가 0~255 범위를 벗어나면, \(b[k]\)는 해당 범위로 클리핑됩니다.
AnalyserNode.getByteTimeDomainData() 메서드 인자. 파라미터 타입 Nullable Optional 설명 arrayUint8Array✘ ✘ 시간 영역 샘플 데이터가 복사될 파라미터입니다. 반환 타입:undefined getFloatFrequencyData(array)-
현재 주파수 데이터를 array에 기록합니다. array의 요소수가
frequencyBinCount보다 적으면 초과 요소는 버려집니다. array의 요소수가frequencyBinCount보다 많으면 초과 요소는 무시됩니다. 가장 최근fftSize프레임을 사용하여 주파수 데이터를 계산합니다.동일 렌더 퀀텀 내에서
getFloatFrequencyData()또는getByteFrequencyData()를 여러 번 호출하면, 현재 주파수 데이터가 갱신되지 않고, 이전에 계산된 데이터가 반환됩니다.주파수 데이터는 dB 단위입니다.
AnalyserNode.getFloatFrequencyData() 메서드 인자. 파라미터 타입 Nullable Optional 설명 arrayFloat32Array✘ ✘ 주파수 영역 분석 데이터가 복사될 파라미터입니다. 반환 타입:undefined getFloatTimeDomainData(array)-
현재 시간 영역 데이터(파형 데이터)를 array에 기록합니다. array의 요소수가
fftSize보다 적으면 초과 요소는 버려집니다. array의 요소수가fftSize보다 많으면 초과 요소는 무시됩니다. 다운믹싱 후, 가장 최근fftSize프레임이 기록됩니다.AnalyserNode.getFloatTimeDomainData() 메서드 인자. 파라미터 타입 Nullable Optional 설명 arrayFloat32Array✘ ✘ 시간 영역 샘플 데이터가 복사될 파라미터입니다. 반환 타입:undefined
1.8.4.
AnalyserOptions
이는 AnalyserNode를
생성할 때 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary AnalyserOptions :AudioNodeOptions {unsigned long fftSize = 2048;double maxDecibels = -30;double minDecibels = -100;double smoothingTimeConstant = 0.8; };
1.8.4.1. 딕셔너리 AnalyserOptions
멤버
fftSize, 타입 unsigned long, 기본값2048-
주파수 영역 분석을 위한 FFT의 초기 크기.
maxDecibels, 타입 double, 기본값-30-
FFT 분석을 위한 최대 파워(dB)의 초기값.
minDecibels, 타입 double, 기본값-100-
FFT 분석을 위한 최소 파워(dB)의 초기값.
smoothingTimeConstant, 타입 double, 기본값0.8-
FFT 분석을 위한 초기 스무딩 상수.
1.8.5. 시간 영역 다운믹싱
현재 시간 영역 데이터를
계산할 때,
입력 신호는 반드시 다운믹싱되어 모노로 변환되어야 하며, 이 때 channelCount
는 1, channelCountMode
는
"max"
그리고 channelInterpretation
은 "speakers"로
처리합니다.
이는 AnalyserNode의
설정과 무관합니다. 가장 최근 fftSize
프레임이 다운믹싱에 사용됩니다.
1.8.6. FFT 윈도우와 시간에 따른 평활화
현재 주파수 데이터를 계산할 때, 다음 연산을 수행합니다:
-
현재 시간 영역 데이터를 계산합니다.
-
Blackman 윈도우를 시간 영역 입력 데이터에 적용합니다.
-
푸리에 변환을 윈도우 처리된 시간 영역 입력 데이터에 적용하여 실수 및 허수 주파수 데이터를 얻습니다.
-
시간에 따른 평활화를 주파수 영역 데이터에 적용합니다.
-
dB로 변환합니다.
다음에서 \(N\)은 이 AnalyserNode의
fftSize
속성 값입니다.
$$
\begin{align*}
\alpha &= \mbox{0.16} \\ a_0 &= \frac{1-\alpha}{2} \\
a_1 &= \frac{1}{2} \\
a_2 &= \frac{\alpha}{2} \\
w[n] &= a_0 - a_1 \cos\frac{2\pi n}{N} + a_2 \cos\frac{4\pi n}{N}, \mbox{ for } n = 0, \ldots, N - 1
\end{align*}
$$
윈도우 적용 신호 \(\hat{x}[n]\)은
$$
\hat{x}[n] = x[n] w[n], \mbox{ for } n = 0, \ldots, N - 1
$$
$$
X[k] = \frac{1}{N} \sum_{n = 0}^{N - 1} \hat{x}[n]\, W^{-kn}_{N}
$$
여기서 \(k = 0, \dots, N/2-1\)이고, \(W_N = e^{2\pi i/N}\)입니다.
-
\(\hat{X}_{-1}[k]\)는 이전 블록에 이 연산을 수행한 결과입니다. 이전 블록은 직전 시간 평활화 연산에서 계산된 버퍼이거나, 해당 연산이 처음이라면 \(N\)개의 0 배열입니다.
-
\(\tau\)는 이
AnalyserNode의smoothingTimeConstant속성 값입니다. -
\(X[k]\)는 현재 블록에 푸리에 변환 적용 결과입니다.
그럼 평활화 값 \(\hat{X}[k]\)는 다음과 같이 계산됩니다:
$$
\hat{X}[k] = \tau\, \hat{X}_{-1}[k] + (1 - \tau)\, \left|X[k]\right|
$$
-
\(\hat{X}[k]\)가
NaN이거나 양/음의 무한대면 \(\hat{X}[k] = 0\)으로 설정합니다.
여기서 \(k = 0, \ldots, N - 1\)입니다.
$$
Y[k] = 20\log_{10}\hat{X}[k]
$$
여기서 \(k = 0, \ldots, N-1\)입니다.
이 배열 \(Y[k]\)는 getFloatFrequencyData()의
출력 배열로 복사됩니다.
getByteFrequencyData()의
경우,
\(Y[k]\)는 minDecibels와
maxDecibelsminDecibels는
값 0,
maxDecibels
1.9. AudioBufferSourceNode
인터페이스
이 인터페이스는 AudioBuffer에
저장된 오디오 에셋을 사용하는 오디오 소스를 나타냅니다.
높은 스케줄링 유연성과 정확도가 필요한 오디오 에셋 재생에 유용합니다. 네트워크 또는 디스크 기반 에셋을 샘플 단위로 정확하게 재생하려면, 구현자는 AudioWorkletNode를
사용해 재생을 구현해야 합니다.
start()
메서드는 사운드 재생 시점을 예약하는 데 사용됩니다. start()
메서드는 여러 번 호출할 수 없습니다. 버퍼의 오디오 데이터를 모두 재생하면(만약 loop
속성이 false인 경우) 또는 stop()
메서드가 호출되어 지정된 시간이 도달하면 재생이 자동으로 중지됩니다. 더 자세한 내용은 start()
및 stop()
설명을 참고하세요.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
출력 채널 수는 buffer
속성에 할당된 AudioBuffer의 채널 수와 같으며,
buffer가
null이면 1채널 무음입니다.
또한, 버퍼가 2개 이상의 채널을 가진 경우, 아래 조건 중 하나가 성립하는 시점(렌더 퀀텀의 시작)부터 AudioBufferSourceNode의 출력은 1채널 무음으로 바뀌어야 합니다:
AudioBufferSourceNode의
재생헤드 위치는
버퍼 첫 샘플 프레임의 시간 좌표에 대한 초 단위 오프셋을 나타내는 값으로 정의됩니다. 이런 값들은 노드의 playbackRate 및 detune
파라미터와는 독립적으로 고려해야 합니다.
일반적으로 재생헤드 위치는 샘플 단위 이하의 정확도를 가질 수 있으며, 정확한 샘플 프레임 위치를 가리킬 필요는 없습니다. 유효 값 범위는 0에서 버퍼의 길이까지입니다.
playbackRate와
detune
속성은 복합 파라미터를 구성합니다.
이 두 값은 함께 computedPlaybackRate 값을 결정합니다:
computedPlaybackRate(t) = playbackRate(t) * pow(2, detune(t) / 1200)
이 복합 파라미터의 명목 범위는 \((-\infty, \infty)\)입니다.
AudioBufferSourceNode는
내부적으로 불리언 슬롯
[[buffer set]]을 갖고, 초기값은 false입니다.
[Exposed =Window ]interface AudioBufferSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional AudioBufferSourceOptions = {});options attribute AudioBuffer ?buffer ;readonly attribute AudioParam playbackRate ;readonly attribute AudioParam detune ;attribute boolean loop ;attribute double loopStart ;attribute double loopEnd ;undefined start (optional double when = 0,optional double offset ,optional double duration ); };
1.9.1. 생성자
AudioBufferSourceNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option과 함께 호출되면, 사용자 에이전트는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.AudioBufferSourceNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 AudioBufferSourceNode가 연결될BaseAudioContext입니다.optionsAudioBufferSourceOptions✘ ✔ 이 AudioBufferSourceNode의 초기 파라미터 값(선택 사항).
1.9.2. 속성
buffer, 타입 AudioBuffer, null 허용-
재생할 오디오 에셋을 나타냅니다.
buffer속성 설정 시 다음 순서를 따릅니다:-
new buffer를
AudioBuffer또는null값으로 둡니다. -
new buffer가
null이 아니고[[buffer set]]값이 true이면,InvalidStateError예외를 던지고 중단합니다. -
new buffer가
null이 아니면[[buffer set]]값을 true로 설정합니다. -
new buffer를
buffer속성에 할당합니다. -
이 노드에서
start()가 이미 호출된 경우,buffer에 대해 acquire the content 연산을 수행합니다.
-
detune, 타입 AudioParam, 읽기 전용-
오디오 스트림의 재생 속도를 센트 단위로 추가적으로 변조하는 파라미터입니다. 이 파라미터는
playbackRate와 함께 복합 파라미터를 이루어 computedPlaybackRate를 만듭니다.파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" k-rate"자동화 속도 제약 있음 loop, 타입 boolean-
loopStart와loopEnd로 지정된 오디오 데이터 영역을 연속적으로 반복 재생할지 여부를 나타냅니다. 기본값은false입니다. loopEnd, 타입 double-
loop속성이 true일 때 반복 재생이 끝나는 재생헤드 위치를 지정하는 선택적 값입니다. 해당 값은 루프 내용에 포함되지 않는(Exclusive) 값입니다. 기본값은0이며, 버퍼 길이 내에서 아무 값이나 유용하게 설정할 수 있습니다.loopEnd가 0 이하이거나 버퍼 길이보다 크면, 반복 재생은 버퍼 끝에서 종료됩니다. loopStart, 타입 double-
loop속성이 true일 때 반복 재생이 시작되는 재생헤드 위치를 지정하는 선택적 값입니다. 기본값은0이며, 버퍼 길이 내에서 아무 값이나 유용하게 설정할 수 있습니다.loopStart가 0 미만이면 0에서 반복이 시작되고, 버퍼 길이보다 크면 버퍼 끝에서 반복이 시작됩니다. playbackRate, 타입 AudioParam, 읽기 전용-
오디오 스트림 재생 속도를 지정합니다. 이 파라미터는
detune과 함께 복합 파라미터를 이루어 computedPlaybackRate를 만듭니다.파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" k-rate"자동화 속도 제약 있음
1.9.3. 메서드
start(when, offset, duration)-
정확한 시점에 사운드 재생을 예약합니다.
이 메서드가 호출되면 다음 단계를 실행합니다:-
이
AudioBufferSourceNode의 내부 슬롯[[source started]]가true이면,InvalidStateError예외를 반드시 던져야 합니다. -
아래 파라미터 제약 조건으로 인해 던져야 하는 오류가 있는지 확인합니다. 이 단계에서 예외가 발생하면 이후 단계를 중단합니다.
-
이
AudioBufferSourceNode의 내부 슬롯[[source started]]를true로 설정합니다. -
컨트롤 메시지 큐잉을 통해
AudioBufferSourceNode시작을 예약하며, 파라미터 값도 메시지에 포함합니다. -
다음 조건을 모두 만족할 때만 연결된
AudioContext에 렌더링 스레드 시작을 위한 컨트롤 메시지를 전송합니다:-
컨텍스트의
[[control thread state]]가suspended입니다. -
컨텍스트가 시작 허용됨 상태입니다.
-
[[suspended by user]]플래그가false입니다.
참고: 이로 인해
start()가 현재 시작 허용됨 상태이지만, 이전에 시작이 차단된AudioContext도 시작할 수 있습니다. -
AudioBufferSourceNode.start(when, offset, duration) 메서드 인자. 파라미터 타입 Nullable Optional 설명 whendouble✘ ✔ when파라미터는 사운드가 몇 초 후 재생을 시작할지 지정합니다.AudioContext의currentTime과 동일한 시간 좌표계입니다. 0 또는 currentTime보다 작은 값이면 즉시 재생됩니다.RangeError예외는when이 음수일 때 반드시 던져야 합니다.offsetdouble✘ ✔ offset파라미터는 재생이 시작될 재생헤드 위치를 지정합니다. 0을 지정하면 버퍼 처음부터 재생됩니다.RangeError예외는offset이 음수일 때 반드시 던져야 합니다.offset이loopEnd보다 크고playbackRate가 0 이상이며loop가 true면,loopEnd에서 시작됩니다.offset이loopStart보다 크고playbackRate가 음수이며loop가 true면,loopStart에서 시작됩니다.offset은startTime에 도달하면 [0,duration] 범위로 클램핑되며,duration은 이AudioBufferSourceNode의buffer에 할당된AudioBuffer의duration속성 값입니다.durationdouble✘ ✔ duration파라미터는 재생될 소리의 지속 시간을 설명하며, 전체 버퍼 내용이 출력될 초 단위로 표현되고, 반복(loop)이 있을 경우 전체 또는 부분 반복도 포함합니다.duration의 단위는playbackRate의 영향과는 무관합니다. 예를 들어,duration이 5초이고 재생 속도가 0.5이면, 버퍼의 5초 분량이 느린 속도로 출력되어 실제로 10초 동안 소리가 들리게 됩니다.RangeError예외는duration이 음수일 경우 반드시 발생해야 합니다.반환 타입:undefined -
1.9.4. AudioBufferSourceOptions
이는 AudioBufferSourceNode를
생성할 때 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary AudioBufferSourceOptions {AudioBuffer ?buffer ;float detune = 0;boolean loop =false ;double loopEnd = 0;double loopStart = 0;float playbackRate = 1; };
1.9.4.1. 딕셔너리 AudioBufferSourceOptions
멤버
buffer, 타입 AudioBuffer, null 허용-
재생할 오디오 에셋. 이는
buffer를buffer속성에 할당하는 것과 동일합니다.AudioBufferSourceNode에서. detune, 타입 float, 기본값0-
detuneAudioParam의 초기값입니다. loop, 타입 boolean, 기본값false-
loop속성의 초기값입니다. loopEnd, 타입 double, 기본값0-
loopEnd속성의 초기값입니다. loopStart, 타입 double, 기본값0-
loopStart속성의 초기값입니다. playbackRate, 타입 float, 기본값1-
playbackRateAudioParam의 초기값입니다.
1.9.5. 루핑
이 부분은 비규범적입니다. 규범 요구사항은 재생 알고리즘을 참조하세요.
loop
속성을 true로 설정하면, loopStart
와 loopEnd로
정의된 버퍼 영역이 반복적으로 재생됩니다. loop 영역의 일부가 한번이라도 재생되면, loop가
true인 동안에는 아래 조건 중 하나가 발생할 때까지 루프 재생이 계속됩니다:
루프 본체는 loopStart
부터 loopEnd
바로 전까지(Exclusive) 영역을 차지합니다.
재생 방향은 노드의 재생 속도 부호를 따릅니다.
재생 속도가 양수면 loopStart에서
loopEnd로,
음수면 loopEnd에서
loopStart로
반복됩니다.
루핑은 offset 인자의 해석에 영향을 주지 않습니다. 재생은 항상 요청된 offset에서 시작하며, 루프 본체가 재생 중에 처음 등장할 때부터 루프가 시작됩니다.
실질적인 루프 시작·끝 지점은 아래 알고리즘에서 명시된 대로 0과 버퍼 길이 사이에 있어야 합니다. loopEnd는
loopStart
이후여야 합니다.
위 조건 중 하나라도 위반되면, 전체 버퍼 내용이 루프에 포함된 것으로 간주됩니다.
루프 지점은 샘플 프레임 이하의 정밀도로 지정됩니다. 지점이 정확한 샘플 프레임 위치가 아니거나 재생 속도가 1이 아니면, 루프 재생은 시작과 끝을 연결할 때 마치 루프 오디오가 버퍼에 연속적으로 존재하는 것처럼 보간(interpolate)됩니다.
루프 관련 속성은 버퍼 재생 중에 변경될 수 있으며, 일반적으로 다음 렌더링 퀀텀에 적용됩니다. 정확한 동작은 이후 규범적 재생 알고리즘에 정의되어 있습니다.
loopStart
와 loopEnd
속성의 기본값은 모두 0입니다. loopEnd가
0이면 버퍼 길이와 같으므로, 기본값은 전체 버퍼가 루프에 포함되도록 합니다.
루프 지점 값은 버퍼의 샘플 레이트 기준 시간 오프셋으로 표현되므로, 이 값들은 노드의 playbackRate
파라미터와 무관하게 정적으로 적용됩니다.
1.9.6. AudioBuffer 내용 재생
이 규범적 섹션은 버퍼 내용 재생을 설명하며, 재생은 다음 요소들이 함께 작용하여 결정됩니다:
-
샘플 단위 이하의 정밀도로 지정될 수 있는 시작 offset
-
재생 중 동적으로 변경될 수 있고, 샘플 단위 이하의 정밀도로 지정될 수 있는 루프 지점
-
재생 속도 및 detune 파라미터는 computedPlaybackRate로 합쳐지며, 유한한 양수 또는 음수 값을 가질 수 있습니다.
내부적으로 AudioBufferSourceNode가
출력을 생성하는 알고리즘은 다음 원칙을 따릅니다:
-
UA는 효율이나 품질 향상을 위해 버퍼의 리샘플링을 임의 시점에 수행할 수 있습니다.
-
샘플 단위 이하의 시작 offset 또는 루프 지점은 추가 보간(interpolation)이 필요할 수 있습니다.
-
루프된 버퍼 재생은, 보간 효과를 제외하면, 루프 오디오가 연속적으로 버퍼에 존재하는 일반 버퍼와 동일하게 동작해야 합니다.
알고리즘 설명은 다음과 같습니다:
let buffer; // 이 노드가 사용하는 AudioBuffer let context; // 이 노드가 사용하는 AudioContext // 아래 변수들은 노드의 속성 및 AudioParam 값을 저장합니다. // process() 호출 전에 k-rate 단위로 갱신됩니다. let loop; let detune; let loopStart; let loopEnd; let playbackRate; // 노드의 재생 파라미터 변수 let start= 0 , offset= 0 , duration= Infinity ; // start()에서 설정 let stop= Infinity ; // stop()에서 설정 // 노드의 재생 상태 추적 변수 let bufferTime= 0 , started= false , enteredLoop= false ; let bufferTimeElapsed= 0 ; let dt= 1 / context. sampleRate; // start() 호출 시 처리 function handleStart( when, pos, dur) { if ( arguments. length>= 1 ) { start= when; } offset= pos; if ( arguments. length>= 3 ) { duration= dur; } } // stop() 호출 시 처리 function handleStop( when) { if ( arguments. length>= 1 ) { stop= when; } else { stop= context. currentTime; } } // 다채널 버퍼의 샘플 프레임을 보간 // 신호값 배열 반환 function playbackSignal( position) { /* 이 함수는 buffer의 재생 신호 함수로, playhead 위치에서 각 출력 채널별 신호값을 반환합니다. position이 버퍼의 정확한 샘플 프레임 위치에 해당하면 해당 프레임 반환, 그렇지 않으면 인근 프레임을 UA가 보간하여 반환합니다. position이 loopEnd보다 크고 buffer에 이후 샘플 프레임이 없으면 loopStart부터의 프레임을 보간합니다. 자세한 보간 방식은 UA에 따라 다를 수 있습니다. */ ... } // 한 번의 렌더 퀀텀에 대해 numberOfFrames만큼의 오디오 샘플 프레임을 출력 배열에 생성 function process( numberOfFrames) { let currentTime= context. currentTime; // 다음 렌더된 프레임의 컨텍스트 시간 const output= []; // 렌더된 샘플 프레임 누적 // playbackRate와 detune 두 k-rate 파라미터 합성 const computedPlaybackRate= playbackRate* Math. pow( 2 , detune/ 1200 ); // 실제 루프 시작/끝점 결정 let actualLoopStart, actualLoopEnd; if ( loop&& buffer!= null ) { if ( loopStart>= 0 && loopEnd> 0 && loopStart< loopEnd) { actualLoopStart= loopStart; actualLoopEnd= Math. min( loopEnd, buffer. duration); } else { actualLoopStart= 0 ; actualLoopEnd= buffer. duration; } } else { // loop 플래그가 false면 loop 진입 기록 제거 enteredLoop= false ; } // buffer가 null인 경우 처리 if ( buffer== null ) { stop= currentTime; // 항상 무음 출력 } // 렌더 퀀텀의 각 샘플 프레임 처리 for ( let index= 0 ; index< numberOfFrames; index++ ) { // currentTime 및 bufferTimeElapsed가 재생 허용 범위 내인지 확인 if ( currentTime< start|| currentTime>= stop|| bufferTimeElapsed>= duration) { output. push( 0 ); // 무음 프레임 currentTime+= dt; continue ; } if ( ! started) { // 재생 시작 시 bufferTime 결정 if ( loop&& computedPlaybackRate>= 0 && offset>= actualLoopEnd) { offset= actualLoopEnd; } if ( computedPlaybackRate< 0 && loop&& offset< actualLoopStart) { offset= actualLoopStart; } bufferTime= offset; started= true ; } // 루프 관련 계산 처리 if ( loop) { if ( ! enteredLoop) { if ( offset< actualLoopEnd&& bufferTime>= actualLoopStart) { enteredLoop= true ; } if ( offset>= actualLoopEnd&& bufferTime< actualLoopEnd) { enteredLoop= true ; } } if ( enteredLoop) { while ( bufferTime>= actualLoopEnd) { bufferTime-= actualLoopEnd- actualLoopStart; } while ( bufferTime< actualLoopStart) { bufferTime+= actualLoopEnd- actualLoopStart; } } } if ( bufferTime>= 0 && bufferTime< buffer. duration) { output. push( playbackSignal( bufferTime)); } else { output. push( 0 ); // 버퍼 끝을 넘으면 무음 프레임 } bufferTime+= dt* computedPlaybackRate; bufferTimeElapsed+= dt* computedPlaybackRate; currentTime+= dt; } // 렌더 퀀텀 루프 끝 if ( currentTime>= stop) { // 이 노드의 재생 상태 종료. 이후 process() 호출 없음, 출력 채널 수 1로 변경 예약 } return output; }
아래 비규범적 그림들은 다양한 주요 시나리오에서 알고리즘 동작을 보여줍니다. 버퍼의 동적 리샘플링은 고려하지 않았지만, 루프 위치 시간이 변경되지 않는 한 결과 재생에는 영향이 없습니다. 모든 그림에서 다음 규칙이 적용됩니다:
-
context 샘플 레이트는 1000 Hz
-
AudioBuffer내용은 첫 번째 샘플 프레임이 x축 원점에 위치합니다. -
출력 신호는
start시점의 샘플 프레임이 x축 원점에 위치하도록 표시됩니다. -
선형 보간이 사용되고 있지만 UA는 다른 보간 알고리즘을 사용할 수도 있습니다.
-
그림에 표기된
duration값은buffer의 값이며,start()인자가 아닙니다.
아래 그림은 버퍼의 기본 재생과 마지막 샘플 프레임에서 루프가 끝나는 간단한 루프를 보여줍니다:
AudioBufferSourceNode
기본 재생 아래 그림은 playbackRate 보간을 보여줍니다. 버퍼 내용을 절반 속도로 재생할 때, 출력 샘플 프레임마다 버퍼가 보간됩니다. 특히 루프 출력의 마지막 샘플 프레임은
루프 시작점으로 보간됩니다:
AudioBufferSourceNode
playbackRate 보간 아래 그림은 샘플 레이트 보간을 보여줍니다. 버퍼의 샘플 레이트가 context의 50%일 때, computed playback rate가 0.5가 되어 두 예시 모두 출력이 동일하지만 원인은 다릅니다.
AudioBufferSourceNode
샘플 레이트 보간. 아래 그림은 샘플 프레임의 정확히 절반 offset에서 재생을 시작하는 경우를 보여줍니다. 모든 출력 프레임이 보간됩니다:
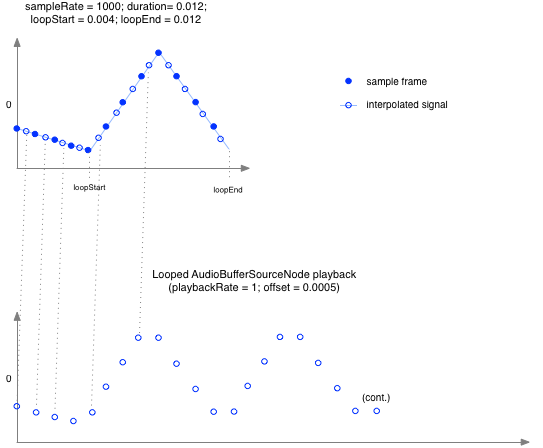
AudioBufferSourceNode
서브샘플 offset 재생 아래 그림은 서브샘플 루프 재생을 보여줍니다. 루프 시작/끝점이 샘플 프레임의 소수점 위치에 지정된 경우, 그 위치를 정확한 샘플 프레임처럼 취급하여 보간된 데이터 포인트가 생성됩니다:
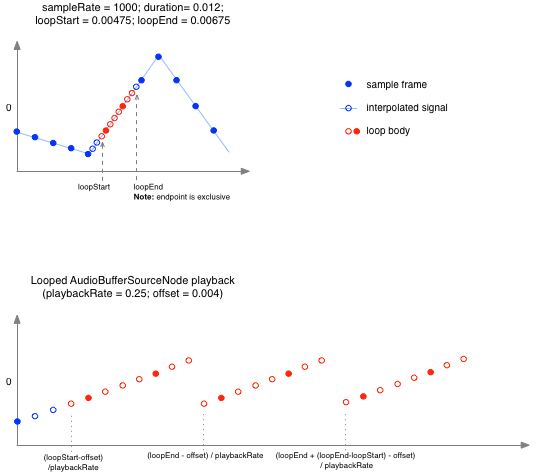
AudioBufferSourceNode
서브샘플 루프 재생 1.10. AudioDestinationNode
인터페이스
이 노드는 최종 오디오 목적지를 나타내는 AudioNode로,
사용자가 궁극적으로 듣게 되는 오디오입니다. 일반적으로 스피커에 연결된 오디오 출력 장치로 볼 수 있습니다. 들을 수 있도록 렌더링된 모든 오디오는 이 노드(즉, AudioContext의
라우팅 그래프에서 "터미널" 노드)에 라우팅됩니다. AudioContext마다
오직 하나의 AudioDestinationNode가 존재하며, destination 속성을 통해 제공합니다.
AudioDestinationNode의
출력은 입력의 합산을 통해 생성되며, 예를 들어 MediaStreamAudioDestinationNode나
MediaRecorder ([mediastream-recording] 참조)에 오디오 컨텍스트 출력을 캡처할 수 있습니다.
AudioDestinationNode는
AudioContext
또는 OfflineAudioContext의
목적지가 될 수 있으며, 채널 속성은 어떤 컨텍스트인지에 따라 달라집니다.
AudioContext의
경우 기본값은 다음과 같습니다:
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
channelCount
값은 maxChannelCount
이하의 아무 값으로 설정할 수 있습니다.
IndexSizeError
예외는 값이 유효 범위를 벗어나면 반드시 던져야 합니다. 예를 들어 오디오 하드웨어가 8채널 출력을 지원하면 channelCount를
8로 설정해 8채널 출력을 렌더링할 수 있습니다.
OfflineAudioContext의
경우 기본값은 다음과 같습니다:
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfChannels | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
여기서 numberOfChannels는 OfflineAudioContext를
생성할 때 지정한 채널 수입니다.
이 값은 변경할 수 없습니다. NotSupportedError
예외는 channelCount
값을 다르게 변경하면 반드시 던져야 합니다.
[Exposed =Window ]interface AudioDestinationNode :AudioNode {readonly attribute unsigned long maxChannelCount ; };
1.10.1. 속성
maxChannelCount, 타입 unsigned long, 읽기 전용-
channelCount속성에 설정할 수 있는 최대 채널 수입니다. 오디오 하드웨어 엔드포인트(일반적인 경우)를 나타내는AudioDestinationNode는 오디오 하드웨어가 멀티채널이면 2개 초과의 오디오 채널을 출력할 수도 있습니다.maxChannelCount는 하드웨어가 지원 가능한 최대 채널 수입니다.
1.11. AudioListener
인터페이스
이 인터페이스는 오디오 장면을 듣는 사람의 위치와 방향을 나타냅니다. 모든 PannerNode
객체는 BaseAudioContext의
listener를
기준으로 공간화됩니다.
공간화에 대한 자세한 내용은 § 6 공간화/패닝을 참조하세요.
positionX,
positionY,
positionZ
파라미터는 3차원 직교 좌표계에서 리스너의 위치를 나타냅니다. PannerNode
객체들은 이 위치를 개별 오디오 소스와의 상대값으로 공간화에 사용합니다.
forwardX,
forwardY,
forwardZ
파라미터는 3차원 공간에서 방향 벡터를 나타냅니다. forward 벡터와 up 벡터 모두 리스너의 방향을 결정하는 데 사용됩니다. 간단히 말해
forward 벡터는 사람의 코가 향하는 방향을, up 벡터는 머리 윗부분이 향하는 방향을 나타냅니다. 이 두 벡터는 선형 독립이어야 합니다.
이러한 값 해석의 규범적 요구사항은 § 6 공간화/패닝 섹션을 참조하세요.
[Exposed =Window ]interface AudioListener {readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam forwardX ;readonly attribute AudioParam forwardY ;readonly attribute AudioParam forwardZ ;readonly attribute AudioParam upX ;readonly attribute AudioParam upY ;readonly attribute AudioParam upZ ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ,z float ,xUp float ,yUp float ); };zUp
1.11.1. 속성
forwardX, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 forward 방향의 x좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" forwardY, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 forward 방향의 y좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" forwardZ, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 forward 방향의 z좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue-1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" positionX, 타입 AudioParam, 읽기 전용-
오디오 리스너의 x좌표 위치를 3차원 직교 좌표계에서 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" positionY, 타입 AudioParam, 읽기 전용-
오디오 리스너의 y좌표 위치를 3차원 직교 좌표계에서 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" positionZ, 타입 AudioParam, 읽기 전용-
오디오 리스너의 z좌표 위치를 3차원 직교 좌표계에서 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" upX, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 up 방향의 x좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" upY, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 up 방향의 y좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate" upZ, 타입 AudioParam, 읽기 전용-
리스너가 3차원 직교 좌표계에서 향하는 up 방향의 z좌표 성분을 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"
1.11.2. 메서드
setOrientation(x, y, z, xUp, yUp, zUp)-
이 메서드는 더 이상 사용되지 않습니다(DEPRECATED).
forwardX.value,forwardY.value,forwardZ.value,upX.value,upY.value,upZ.value에 각각 x, y, z, xUp, yUp, zUp 값을 직접 할당하는 것과 같습니다.따라서
forwardX,forwardY,forwardZ,upX,upY,upZAudioParam에setValueCurveAtTime()으로 오토메이션 커브가 설정된 경우, 이 메서드 호출 시NotSupportedError가 반드시 발생해야 합니다.setOrientation()은 3차원 직교좌표계에서 리스너가 어느 방향을 향하는지 지정합니다. forward 벡터와 up 벡터 모두 제공됩니다. 간단히 말해 forward는 사람의 코가 향하는 방향, up은 머리 윗부분이 향하는 방향입니다. 두 벡터는 선형 독립이어야 합니다. 해석의 규범적 요구사항은 § 6 공간화/패닝을 참조하세요.x,y,z파라미터는 3차원 공간상의 forward 방향 벡터이며, 기본값은 (0,0,-1)입니다.xUp,yUp,zUp파라미터는 3차원 공간상의 up 방향 벡터이며, 기본값은 (0,1,0)입니다.AudioListener.setOrientation() 메서드 인자 파라미터 타입 Nullable Optional 설명 xfloat✘ ✘ AudioListener의 forward x 방향yfloat✘ ✘ AudioListener의 forward y 방향zfloat✘ ✘ AudioListener의 forward z 방향xUpfloat✘ ✘ AudioListener의 up x 방향yUpfloat✘ ✘ AudioListener의 up y 방향zUpfloat✘ ✘ AudioListener의 up z 방향반환 타입:undefined setPosition(x, y, z)-
이 메서드는 더 이상 사용되지 않습니다(DEPRECATED).
positionX.value,positionY.value,positionZ.value에 각각 x, y, z 값을 직접 할당하는 것과 같습니다.따라서
positionX,positionY,positionZAudioParam에setValueCurveAtTime()으로 오토메이션 커브가 설정된 경우, 이 메서드 호출 시NotSupportedError가 반드시 발생해야 합니다.setPosition()은 리스너의 위치를 3차원 직교좌표계에서 설정합니다.PannerNode객체들은 이 위치를 개별 오디오 소스와의 상대값으로 공간화에 사용합니다.기본값은 (0,0,0)입니다.
AudioListener.setPosition() 메서드 인자 파라미터 타입 Nullable Optional 설명 xfloat✘ ✘ AudioListener위치의 x 좌표yfloat✘ ✘ AudioListener위치의 y 좌표zfloat✘ ✘ AudioListener위치의 z 좌표
1.11.3. 처리
AudioListener의
파라미터가 AudioNode와
연결될 수 있고,
PannerNode의
출력에도 영향을 줄 수 있으므로,
노드 순서 결정 알고리즘에서 AudioListener
를 고려하여 처리 순서를 결정해야 합니다. 이 이유로 그래프 내의 모든 PannerNode
는 AudioListener
를 입력으로 가집니다.
1.12. AudioProcessingEvent
인터페이스 - 더 이상 사용되지 않음(DEPRECATED)
이 객체는 Event로,
ScriptProcessorNode
노드에 전달됩니다. ScriptProcessorNode가 삭제될 때 이 객체도 제거되며, 대체 노드인 AudioWorkletNode는
다른 방식을 사용합니다.
이벤트 핸들러는 입력이 있을 경우 inputBuffer 속성에서 오디오 데이터를 가져와 처리합니다.
처리 결과(혹은 입력이 없을 경우 합성된 데이터)는 outputBuffer
속성에 기록됩니다.
[Exposed =Window ]interface AudioProcessingEvent :Event {(constructor DOMString ,type AudioProcessingEventInit );eventInitDict readonly attribute double playbackTime ;readonly attribute AudioBuffer inputBuffer ;readonly attribute AudioBuffer outputBuffer ; };
1.12.1. 속성
inputBuffer, 타입 AudioBuffer, 읽기 전용-
입력 오디오 데이터가 담긴 AudioBuffer입니다. 채널 수는 createScriptProcessor() 메서드의
numberOfInputChannels파라미터와 동일합니다. 이 AudioBuffer는audioprocess이벤트 핸들러 함수의 범위 내에서만 유효합니다. 이 범위를 벗어나면 값이 의미가 없습니다. outputBuffer, 타입 AudioBuffer, 읽기 전용-
출력 오디오 데이터를 반드시 기록해야 하는 AudioBuffer입니다. 채널 수는 createScriptProcessor() 메서드의
numberOfOutputChannels파라미터와 동일합니다. Script 코드에서audioprocess이벤트 핸들러 함수 내에서 이 AudioBuffer의 채널 데이터를 나타내는Float32Array배열을 수정해야 합니다. 이 범위 밖에서는 AudioBuffer를 수정해도 소리가 나지 않습니다. playbackTime, 타입 double, 읽기 전용-
해당 오디오가
AudioContext의currentTime과 동일한 시간 좌표계에서 재생되는 시점입니다.
1.12.2. AudioProcessingEventInit
dictionary AudioProcessingEventInit :EventInit {required double playbackTime ;required AudioBuffer inputBuffer ;required AudioBuffer outputBuffer ; };
1.12.2.1. 딕셔너리 AudioProcessingEventInit
멤버
inputBuffer, 타입 AudioBuffer-
이벤트의
inputBuffer속성에 할당할 값입니다. outputBuffer, 타입 AudioBuffer-
이벤트의
outputBuffer속성에 할당할 값입니다. playbackTime, 타입 double-
이벤트의
playbackTime속성에 할당할 값입니다.
1.13.
BiquadFilterNode
인터페이스
BiquadFilterNode
는 아주 일반적인 저차 필터를 구현하는 AudioNode
프로세서입니다.
저차 필터는 기본 톤 컨트롤(베이스, 미드, 트레블), 그래픽 이퀄라이저, 더 고급 필터의 기본 구성 요소입니다.
여러 BiquadFilterNode
필터를 조합하여 더 복잡한 필터를 만들 수 있습니다. frequency
등의 필터 파라미터는 필터 스윕 등 시간에 따라 변화시킬 수 있습니다. 각 BiquadFilterNode
는 아래 IDL에 나온 여러 일반적인 필터 타입 중 하나로 구성할 수 있습니다. 기본 필터 타입은 "lowpass"입니다.
frequency
와 detune
은 복합 파라미터를 이루며, 둘 다
a-rate입니다. 이 두 값은 함께 computedFrequency 값을
결정합니다:
computedFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
이 복합 파라미터의 명목 범위는 [0, 나이퀴스트 주파수]입니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 예 | 입력이 0이어도 무음이 아닌 오디오를 계속 출력합니다. IIR 필터이므로 원리적으로는 영원히 0이 아닌 출력을 생성하지만, 실제로는 출력이 충분히 0에 가까워지는 유한 시간 이후 제한할 수 있습니다. 실제 시간은 필터 계수에 따라 달라집니다. |
출력의 채널 수는 항상 입력의 채널 수와 같습니다.
enum {BiquadFilterType "lowpass" ,"highpass" ,"bandpass" ,"lowshelf" ,"highshelf" ,"peaking" ,"notch" ,"allpass" };
| 열거 값 | 설명 |
|---|---|
"lowpass"
|
로우패스 필터는 컷오프 주파수 이하의 주파수를 통과시키고,
컷오프 이상의 주파수를 감쇠시킵니다. 12dB/octave 롤오프를 가진 표준 2차 공진 로우패스 필터입니다.
|
"highpass"
|
하이패스 필터는 로우패스 필터의 반대입니다. 컷오프
주파수 이상의 주파수가 통과되고, 컷오프 이하의 주파수는 감쇠됩니다. 12dB/octave 롤오프를 가진 표준 2차 공진 하이패스 필터입니다.
|
"bandpass"
|
밴드패스 필터는 특정 주파수 대역만 통과시키고, 그
아래와 위의 주파수는 감쇠합니다. 2차 밴드패스 필터입니다.
|
"lowshelf"
|
로우셀프 필터는 모든 주파수를 통과시키지만, 저주파수에 부스트(또는 감쇠)를 적용합니다. 2차 로우셀프 필터입니다.
|
"highshelf"
|
하이셀프 필터는 로우셀프의 반대로, 모든 주파수를 통과시키지만 고주파수에 부스트를 적용합니다. 2차 하이셀프 필터입니다.
|
"peaking"
|
피킹 필터는 모든 주파수를 통과시키지만, 특정 주파수 범위에 부스트(또는 감쇠)를 적용합니다.
|
"notch"
|
노치 필터(밴드스톱 또는 밴드리젝션 필터라고도 함)는 밴드패스 필터의 반대입니다. 모든 주파수를 통과시키지만, 특정 주파수 대역은 감쇠됩니다.
|
"allpass"
|
올패스 필터는
모든 주파수를 통과시키지만, 각 주파수의 위상 관계를 변화시킵니다. 2차 올패스 필터입니다.
|
BiquadFilterNode
의 모든 속성은 a-rate AudioParam입니다.
[Exposed =Window ]interface BiquadFilterNode :AudioNode {(constructor BaseAudioContext ,context optional BiquadFilterOptions = {});options attribute BiquadFilterType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;readonly attribute AudioParam Q ;readonly attribute AudioParam gain ;undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.13.1. 생성자
BiquadFilterNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.BiquadFilterNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 BiquadFilterNode가 연결될BaseAudioContext입니다.optionsBiquadFilterOptions✘ ✔ 이 BiquadFilterNode의 초기 파라미터 값(선택 사항).
1.13.2. 속성
Q, 타입 AudioParam, 읽기 전용-
필터의 Q 값입니다.
lowpass및highpass필터에서는Q값이 dB 단위로 해석됩니다. 이 필터들의 명목 범위는 \([-Q_{lim}, Q_{lim}]\)이고, \(Q_{lim}\)은 \(10^{Q/20}\)이 오버플로우하지 않는 최대값입니다. 이 값은 약 \(770.63678\)입니다.bandpass,notch,allpass,peaking필터에서는 이 값이 선형 값입니다. 필터의 대역폭과 관련이 있으므로 양수여야 합니다. 명목 범위는 \([0, 3.4028235e38]\)이고, 상한은 최대 단정도 float입니다.lowshelf및highshelf필터에서는 사용되지 않습니다.파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38, 실제 필터별 제한은 위 설명 참조 maxValue최대 단정도 float 약 3.4028235e38, 실제 필터별 제한은 위 설명 참조 automationRate" a-rate" detune, 타입 AudioParam, 읽기 전용-
frequency에 대해 센트 단위로 조율(detune)하는 값입니다.
frequency와 함께 복합 파라미터를 이루어 computedFrequency를 만듭니다.파라미터 값 비고 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) 이 값은 \(1200\ \log_2 \mathrm{FLT\_MAX}\) (FLT_MAX는 최대 float값)과 동일합니다.automationRate" a-rate" frequency, 타입 AudioParam, 읽기 전용-
이
BiquadFilterNode가 동작할 주파수(Hz 단위).detune과 함께 복합 파라미터를 이루어 computedFrequency를 만듭니다.파라미터 값 비고 defaultValue350 minValue0 maxValue나이퀴스트 주파수 automationRate" a-rate" gain, 타입 AudioParam, 읽기 전용-
필터의 게인 값(dB 단위).
lowshelf,highshelf,peaking필터에서만 사용됩니다.파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue\(\approx 1541\) 이 값은 \(40\ \log_{10} \mathrm{FLT\_MAX}\) (FLT_MAX는 최대 float값)과 거의 같습니다.automationRate" a-rate" type, 타입 BiquadFilterType-
이
BiquadFilterNode의 필터 타입입니다. 기본값은 "lowpass"입니다. 다른 파라미터의 정확한 의미는type속성 값에 따라 달라집니다.
1.13.3. 메서드
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
[[current value]]를 각 필터 파라미터에서 얻어, 지정된 주파수에 대한 주파수 응답을 동기적으로 계산합니다. 세 파라미터는 반드시 동일한 길이의Float32Array여야 하며, 그렇지 않으면InvalidAccessError가 반드시 발생해야 합니다.반환되는 주파수 응답은
AudioParam이 현재 처리 블록에서 샘플링된 값을 사용해 계산되어야 합니다.BiquadFilterNode.getFrequencyResponse() 메서드 인자. 파라미터 타입 Nullable Optional 설명 frequencyHzFloat32Array✘ ✘ 응답값을 계산할 Hz 단위의 주파수 배열입니다. magResponseFloat32Array✘ ✘ 각 frequencyHz값에 대한 선형 크기 응답값을 받는 출력 배열입니다.frequencyHz값이 [0, sampleRate/2] 범위를 벗어나면, 해당 인덱스의magResponse값은NaN이어야 합니다. sampleRate는sampleRate속성 값입니다.phaseResponseFloat32Array✘ ✘ 각 frequencyHz값에 대한 라디안 단위의 위상 응답값을 받는 출력 배열입니다.frequencyHz값이 [0, sampleRate/2] 범위를 벗어나면, 해당 인덱스의phaseResponse값은NaN이어야 합니다. sampleRate는sampleRate속성 값입니다.반환 타입:undefined
1.13.4. BiquadFilterOptions
이 객체는 BiquadFilterNode를
생성할 때 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary BiquadFilterOptions :AudioNodeOptions {BiquadFilterType type = "lowpass";float Q = 1;float detune = 0;float frequency = 350;float gain = 0; };
1.13.4.1. 딕셔너리 BiquadFilterOptions
멤버
Q, 타입 float, 기본값1-
Q의 초기값입니다. detune, 타입 float, 기본값0-
detune의 초기값입니다. frequency, 타입 float, 기본값350-
frequency의 초기값입니다. gain, 타입 float, 기본값0-
gain의 초기값입니다. type, 타입 BiquadFilterType, 기본값"lowpass"-
필터의 초기 타입입니다.
1.13.5. 필터 특성
BiquadFilterNode로
사용할 수 있는 여러 유형의 필터는 구현 방식에 따라 특성이 크게 다릅니다. 이 섹션의 공식들은 현행 표준 구현이 반드시 구현해야 하는 필터 특성을 설명합니다. 공식들은 Audio EQ Cookbook에서 가져온
것입니다.
BiquadFilterNode
는 다음 전달 함수로 오디오를 처리합니다:
$$
H(z) = \frac{\frac{b_0}{a_0} + \frac{b_1}{a_0}z^{-1} + \frac{b_2}{a_0}z^{-2}}
{1+\frac{a_1}{a_0}z^{-1}+\frac{a_2}{a_0}z^{-2}}
$$
이는 시간 영역에서 다음 식과 같습니다:
$$
a_0 y(n) + a_1 y(n-1) + a_2 y(n-2) =
b_0 x(n) + b_1 x(n-1) + b_2 x(n-2)
$$
필터의 초기 상태는 0입니다.
참고: 고정 필터는 안정적이지만, AudioParam
오토메이션을 사용하면 불안정한 biquad 필터를 만들 수도 있습니다. 개발자가 직접 관리해야 합니다.
참고: UA는 필터 상태에 NaN 값이 발생하면 경고를 표시할 수 있습니다. 이는 일반적으로 불안정한 필터의 신호입니다.
위 전달 함수의 계수는 노드 타입별로 다릅니다. 각 계수를 구하려면 BiquadFilterNode의
AudioParam의
computedValue를 기반으로 아래 중간 변수들이
필요합니다:
-
\(F_s\):
sampleRate속성 값 -
\(f_0\): computedFrequency 값
-
\(G\):
gainAudioParam값 -
\(Q\):
QAudioParam값 -
마지막으로 아래와 같이 정의합니다:
$$ \begin{align*} A &= 10^{\frac{G}{40}} \\ \omega_0 &= 2\pi\frac{f_0}{F_s} \\ \alpha_Q &= \frac{\sin\omega_0}{2Q} \\ \alpha_{Q_{dB}} &= \frac{\sin\omega_0}{2 \cdot 10^{Q/20}} \\ S &= 1 \\ \alpha_S &= \frac{\sin\omega_0}{2}\sqrt{\left(A+\frac{1}{A}\right)\left(\frac{1}{S}-1\right)+2} \end{align*} $$
각 필터 타입별 6개 계수(\(b_0, b_1, b_2, a_0, a_1, a_2\))는 다음과 같습니다:
- "
lowpass" -
$$ \begin{align*} b_0 &= \frac{1 - \cos\omega_0}{2} \\ b_1 &= 1 - \cos\omega_0 \\ b_2 &= \frac{1 - \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
highpass" -
$$ \begin{align*} b_0 &= \frac{1 + \cos\omega_0}{2} \\ b_1 &= -(1 + \cos\omega_0) \\ b_2 &= \frac{1 + \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
bandpass" -
$$ \begin{align*} b_0 &= \alpha_Q \\ b_1 &= 0 \\ b_2 &= -\alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
notch" -
$$ \begin{align*} b_0 &= 1 \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
allpass" -
$$ \begin{align*} b_0 &= 1 - \alpha_Q \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 + \alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
peaking" -
$$ \begin{align*} b_0 &= 1 + \alpha_Q\, A \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 - \alpha_Q\,A \\ a_0 &= 1 + \frac{\alpha_Q}{A} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \frac{\alpha_Q}{A} \end{align*} $$ - "
lowshelf" -
$$ \begin{align*} b_0 &= A \left[ (A+1) - (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A})\right] \\ b_1 &= 2 A \left[ (A-1) - (A+1) \cos\omega_0 )\right] \\ b_2 &= A \left[ (A+1) - (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \right] \\ a_0 &= (A+1) + (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A} \\ a_1 &= -2 \left[ (A-1) + (A+1) \cos\omega_0\right] \\ a_2 &= (A+1) + (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \end{align*} $$ - "
highshelf" -
$$ \begin{align*} b_0 &= A\left[ (A+1) + (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} )\right] \\ b_1 &= -2A\left[ (A-1) + (A+1)\cos\omega_0 )\right] \\ b_2 &= A\left[ (A+1) + (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} )\right] \\ a_0 &= (A+1) - (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} \\ a_1 &= 2\left[ (A-1) - (A+1)\cos\omega_0\right] \\ a_2 &= (A+1) - (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} \end{align*} $$
1.14.
ChannelMergerNode
인터페이스
ChannelMergerNode
는 고급 응용에 사용되며 종종 ChannelSplitterNode
와 함께 사용됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 비고 참조 | 기본값은 6이며, ChannelMergerOptions,
numberOfInputs
또는 createChannelMerger
에 지정된 값에 따라 결정됩니다.
|
numberOfOutputs
| 1 | |
channelCount
| 1 | channelCount 제약 있음 |
channelCountMode
| "explicit"
| channelCountMode 제약 있음 |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
이 인터페이스는 여러 오디오 스트림의 채널을 하나의 오디오 스트림으로 합치는 AudioNode
를 나타냅니다. 입력 수는 가변(기본값 6)이며, 모두 연결할 필요는 없습니다. 출력은 단일 스트림이며, 입력 중 하나라도 실시간 처리 중이면 출력 오디오 스트림의 채널 수가 입력 수와
동일합니다. 입력이 모두 실시간
처리되지 않으면 출력은 단일 채널 무음이 됩니다.
여러 입력을 하나의 스트림으로 병합할 때, 각 입력은 지정된 믹싱 규칙에 따라 한 채널(모노)로 다운믹스됩니다. 연결되지 않은 입력도 출력에서 무음 채널 하나로 취급됩니다. 입력 스트림 변경은 출력 채널 순서에 영향을 주지 않습니다.
ChannelMergerNode
에 두 개의 스테레오 입력이 연결되면, 각 입력은 병합 전에 각각 모노로 다운믹스됩니다. 출력은 6채널 스트림이 되며, 처음 두 채널은 첫 번째와 두 번째(다운믹스된) 입력으로 채워지고 나머지
채널은 무음입니다.
또한 ChannelMergerNode
를 사용하면 5.1 서라운드와 같은 다채널 스피커 배열에 여러 오디오 스트림을 특정 순서로 배치할 수 있습니다. merger는 채널의 정체성(좌, 우 등)을 해석하지 않고, 입력되는
순서대로 단순히 채널을 합칩니다.

[Exposed =Window ]interface ChannelMergerNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelMergerOptions = {}); };options
1.14.1. 생성자
ChannelMergerNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.ChannelMergerNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 ChannelMergerNode가 연결될BaseAudioContext입니다.optionsChannelMergerOptions✘ ✔ 이 ChannelMergerNode의 초기 파라미터 값(선택 사항).
1.14.2. ChannelMergerOptions
dictionary ChannelMergerOptions :AudioNodeOptions {unsigned long numberOfInputs = 6; };
1.14.2.1. 딕셔너리 ChannelMergerOptions
멤버
numberOfInputs, 타입 unsigned long, 기본값6-
ChannelMergerNode의 입력 수입니다. 이 값에 대한 제약은createChannelMerger()를 참조하세요.
1.15. ChannelSplitterNode
인터페이스
ChannelSplitterNode
는 고급 응용에 사용되며, 종종 ChannelMergerNode
와 함께 사용됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 비고 참조 | 기본값은 6이며, ChannelSplitterOptions.numberOfOutputs
또는 createChannelSplitter
또는 numberOfOutputs
멤버의 ChannelSplitterOptions
딕셔너리, 생성자에
의해 결정됩니다.
|
channelCount
| numberOfOutputs
| channelCount 제약 있음 |
channelCountMode
| "explicit"
| channelCountMode 제약 있음 |
channelInterpretation
| "discrete"
| channelInterpretation 제약 있음 |
| tail-time | 없음 |
이 인터페이스는 라우팅 그래프에서 오디오 스트림의 개별 채널에 접근할 수 있는 AudioNode
를 나타냅니다. 입력은 하나이고, "활성" 출력의 수는 입력 오디오 스트림의 채널 수와 같습니다. 예를 들어, 스테레오 입력이 ChannelSplitterNode
에 연결되면 활성 출력은 두 개(좌, 우 채널 각각)입니다. 항상 총 N개의 출력이 있는데(N은 numberOfOutputs 파라미터로 결정), AudioContext의
createChannelSplitter()
메서드의
파라미터로 결정됩니다. 값을 명시하지 않으면 기본값은 6입니다. "활성"이 아닌 출력은 무음을 출력하며, 보통 아무 것도 연결하지 않습니다.
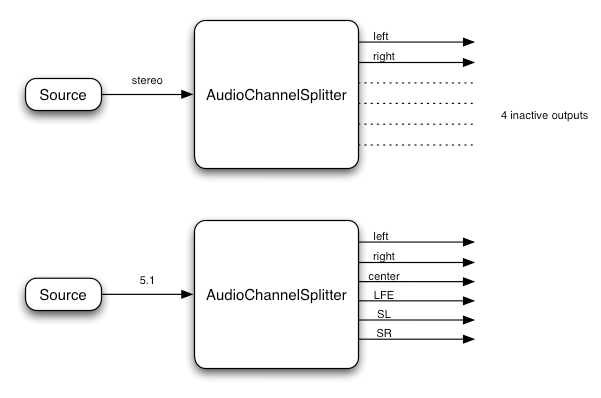
ChannelSplitterNode
의 한 가지 용도는 각 채널의 개별 게인을 제어하는 "매트릭스 믹싱"에 있습니다.
[Exposed =Window ]interface ChannelSplitterNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelSplitterOptions = {}); };options
1.15.1. 생성자
ChannelSplitterNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.ChannelSplitterNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 ChannelSplitterNode가 연결될BaseAudioContext입니다.optionsChannelSplitterOptions✘ ✔ 이 ChannelSplitterNode의 초기 파라미터 값(선택 사항).
1.15.2. ChannelSplitterOptions
dictionary ChannelSplitterOptions :AudioNodeOptions {unsigned long numberOfOutputs = 6; };
1.15.2.1. 딕셔너리 ChannelSplitterOptions
멤버
numberOfOutputs, 타입 unsigned long, 기본값6-
ChannelSplitterNode의 출력 수입니다. 이 값에 대한 제약은createChannelSplitter()를 참조하세요.
1.16.
ConstantSourceNode
인터페이스
이 인터페이스는 출력이 명목상 일정한 값을 가지는 상수 오디오 소스를 나타냅니다. 일반적으로 상수 소스 노드로 유용하며, AudioParam처럼
사용할 수 있고, offset을
자동화하거나 다른 노드를 연결할 수 있습니다.
이 노드의 단일 출력은 하나의 채널(모노)로 구성됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
[Exposed =Window ]interface ConstantSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional ConstantSourceOptions = {});options readonly attribute AudioParam offset ; };
1.16.1. 생성자
ConstantSourceNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.ConstantSourceNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 ConstantSourceNode가 연결될BaseAudioContext입니다.optionsConstantSourceOptions✘ ✔ 이 ConstantSourceNode의 초기 파라미터 값(선택 사항).
1.16.2. 속성
offset, 타입 AudioParam, 읽기 전용-
소스의 상수값입니다.
파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"
1.16.3. ConstantSourceOptions
이 객체는 ConstantSourceNode
생성에 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary ConstantSourceOptions {float offset = 1; };
1.16.3.1. 딕셔너리 ConstantSourceOptions
멤버
offset, 타입 float, 기본값1-
이 노드의
offsetAudioParam의 초기값입니다.
1.17. ConvolverNode
인터페이스
이 인터페이스는 임펄스 응답을 받아 선형 컨벌루션 효과를 적용하는 처리 노드를 나타냅니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 제약 있음 |
channelCountMode
| "clamped-max"
| channelCountMode 제약 있음 |
channelInterpretation
| "speakers"
| |
| tail-time | 예 | 입력이 0이어도 buffer
길이만큼 무음이 아닌 오디오를 계속 출력함
|
이 노드의 입력은 모노(1채널) 또는 스테레오(2채널)만 가능하며, 더 늘릴 수 없습니다. 더 많은 채널을 가진 노드에서 연결되면 적절하게 다운믹스됩니다.
이 노드에는 channelCount 제약과 channelCountMode 제약이 있습니다. 이 제약은 입력이 모노 또는 스테레오가 되도록 보장합니다.
[Exposed =Window ]interface ConvolverNode :AudioNode {constructor (BaseAudioContext ,context optional ConvolverOptions = {});options attribute AudioBuffer ?buffer ;attribute boolean normalize ; };
1.17.1. 생성자
ConvolverNode(context, options)-
생성자가
BaseAudioContextcontext와 옵션 객체 options로 호출되면 다음 절차를 수행합니다:-
normalize속성을disableNormalization값의 반대로 설정합니다. -
buffer존재하면buffer속성을 해당 값으로 설정합니다.참고: buffer는
normalize속성 값에 따라 정규화됩니다. -
o를 새
AudioNodeOptions딕셔너리로 만듭니다. -
channelCount가 options에 존재하면,channelCount를 o에 같은 값으로 설정합니다. -
channelCountMode가 options에 존재하면,channelCountMode를 o에 같은 값으로 설정합니다. -
channelInterpretation가 options에 존재하면,channelInterpretation을 o에 같은 값으로 설정합니다. -
AudioNode를 초기화 this, c와 o를 인자로 사용합니다.
ConvolverNode.constructor() 메서드 인자 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 ConvolverNode가 연결될BaseAudioContext입니다.optionsConvolverOptions✘ ✔ 이 ConvolverNode의 초기 파라미터 값(선택 사항). -
1.17.2. 속성
buffer, 타입 AudioBuffer, nullable-
이 속성을 설정할 때
buffer와normalize속성 상태에 따라 이 임펄스 응답의 정규화가 적용된ConvolverNode가 구성됩니다. 이 속성의 초기값은 null입니다.buffer attribute를 설정할 때 다음 절차를 동기적으로 수행합니다:-
buffer
number of channels가 1, 2, 4가 아니거나 buffer의sample-rate가 연결된BaseAudioContext의sample-rate와 다르면NotSupportedError를 반드시 발생시킵니다.
참고:
buffer를 새 buffer로 설정하면 오디오가 순간적으로 끊길 수 있습니다. 이를 피하려면 새ConvolverNode를 생성해 교체하거나 크로스페이드하는 것이 좋습니다.참고:
ConvolverNode는 입력이 한 채널이고buffer도 한 채널인 경우에만 모노 출력을 생성합니다. 그 외에는 모두 스테레오 출력입니다. 특히buffer가 4채널이고 입력이 2채널이면ConvolverNode가 매트릭스 "진정한" 스테레오 컨벌루션을 수행합니다. 자세한 규범적 정보는 채널 구성 다이어그램을 참조하세요. -
normalize, 타입 boolean-
buffer에서 임펄스 응답을 가져올 때 equal-power 정규화를 적용할지 제어합니다. 기본값은
true로, 다양한 임펄스 응답을 사용할 때 보다 일정한 출력 레벨을 얻기 위해 설정되어 있습니다.normalize가false면 임펄스 응답에 대해 사전 처리/스케일링 없이 컨벌루션이 렌더링됩니다. 이 값 변경은 buffer 속성이 다음에 설정될 때까지 적용되지 않습니다.normalize가 false일 때 buffer 속성을 설정하면ConvolverNode는 buffer에 포함된 임펄스 응답 그대로 선형 컨벌루션을 수행합니다.반대로
normalize가 true일 때 buffer 속성을 설정하면ConvolverNode가 buffer의 오디오 데이터를 이용해 다음 알고리즘으로 normalizationScale을 계산합니다:function calculateNormalizationScale( buffer) { const GainCalibration= 0.00125 ; const GainCalibrationSampleRate= 44100 ; const MinPower= 0.000125 ; // RMS 파워로 정규화 const numberOfChannels= buffer. numberOfChannels; const length= buffer. length; let power= 0 ; for ( let i= 0 ; i< numberOfChannels; i++ ) { let channelPower= 0 ; const channelData= buffer. getChannelData( i); for ( let j= 0 ; j< length; j++ ) { const sample= channelData[ j]; channelPower+= sample* sample; } power+= channelPower; } power= Math. sqrt( power/ ( numberOfChannels* length)); // 과부하 방지 if ( ! isFinite( power) || isNaN( power) || power< MinPower) power= MinPower; let scale= 1 / power; // 원본과 인지 볼륨 같게 보정 scale*= GainCalibration; // 샘플레이트에 따라 스케일 적용 if ( buffer. sampleRate) scale*= GainCalibrationSampleRate/ buffer. sampleRate; // true-stereo 보정 if ( numberOfChannels== 4 ) scale*= 0.5 ; return scale; } 처리 중 ConvolverNode는 계산된 normalizationScale을 선형 컨벌루션 결과에 곱하여 최종 출력을 만듭니다. 또는 입력이나 임펄스 응답에 사전 곱셈하는 등 수학적으로 동등한 방법을 사용할 수 있습니다.
1.17.3.
ConvolverOptions
이 객체는 ConvolverNode를
생성할 때 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값으로 노드가 생성됩니다.
dictionary ConvolverOptions :AudioNodeOptions {AudioBuffer ?buffer ;boolean disableNormalization =false ; };
1.17.3.1. 딕셔너리 ConvolverOptions
멤버
buffer, 타입 AudioBuffer, nullable-
ConvolverNode에 사용할 buffer입니다. 이 buffer는disableNormalization값에 따라 정규화됩니다. disableNormalization, 타입 boolean, 기본값false-
ConvolverNode의normalize속성의 초기값과 반대되는 값입니다.
1.17.4. 입력, 임펄스 응답, 출력의 채널 구성
구현체는 ConvolverNode에서
임펄스 응답 채널의 다음 허용 구성을 지원해야 하며,
1 또는 2 채널 입력으로 다양한 리버브 효과를 얻을 수 있습니다.
아래 다이어그램에서 단일 채널 컨벌루션은 모노 오디오 입력, 모노 임펄스 응답, 모노 출력을 사용합니다. 다이어그램의 나머지 이미지는 입력 채널 수가 1 또는 2이고 buffer
채널 수가 1, 2, 4인 경우의
모노 및 스테레오 재생에 대한 지원 케이스를 보여줍니다.
더 복잡하고 임의의 매트릭스를 원하는 개발자는 ChannelSplitterNode,
여러 단일 채널 ConvolverNode,
ChannelMergerNode를
사용할 수 있습니다.
이 노드가 실시간 처리 중이 아니면 출력은 단일 채널 무음입니다.
참고: 아래 다이어그램은 실시간 처리 중일 때의 출력을 보여줍니다.
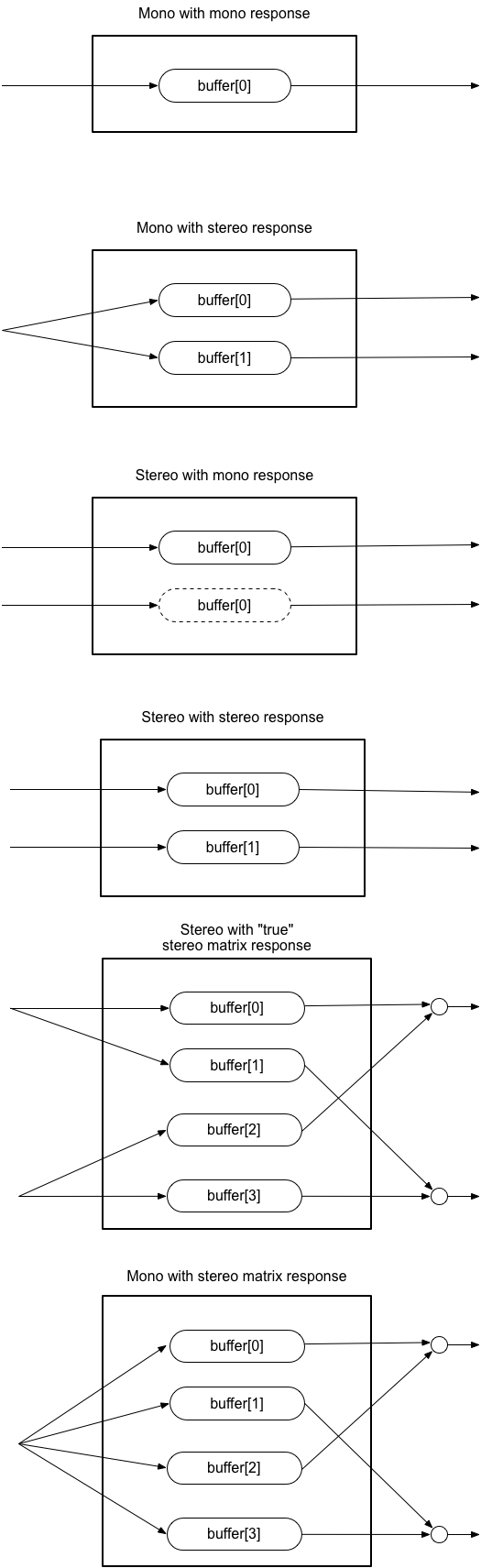
ConvolverNode
사용 시 지원되는 입력 및 출력 채널 수의 그래픽 표현
1.18. DelayNode
인터페이스
딜레이 라인은 오디오 응용에서 근본적인 구성 요소입니다.
이 인터페이스는 입력과 출력이 각각 하나씩 있는 AudioNode입니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 예 | 입력이 0이어도 노드의 maxDelayTime만큼
무음이 아닌 오디오를 계속 출력함
|
출력 채널 수는 항상 입력 채널 수와 같습니다.
입력 오디오 신호를 일정 시간만큼 지연시킵니다.
구체적으로, 각 시점 t에서 입력 신호 input(t), 지연 시간 delayTime(t), 출력 신호 output(t)에 대해,
출력은 output(t) = input(t -
delayTime(t))이 됩니다. 기본 delayTime은 0초(지연 없음)입니다.
DelayNode 입력의
채널 수가 변경되면(출력 채널 수도 변경됨), 아직 노드에서 출력되지 않은 지연 오디오 샘플이 내부 상태에 남아 있을 수 있습니다. 이 샘플들이 이전에 다른 채널 수로 받아졌다면, 새로 받은
입력과 결합하기 전에 반드시 업믹스 또는 다운믹스되어야 하며, 모든 내부 딜레이 라인 믹싱은 단일 현재 채널 레이아웃으로 진행되어야 합니다.
참고: DelayNode는 정의상
지연만큼 오디오 처리 레이턴시를 유발합니다.
[Exposed =Window ]interface DelayNode :AudioNode {constructor (BaseAudioContext ,context optional DelayOptions = {});options readonly attribute AudioParam delayTime ; };
1.18.1. 생성자
DelayNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.DelayNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 DelayNode가 연결될BaseAudioContext입니다.optionsDelayOptions✘ ✔ 이 DelayNode의 초기 파라미터 값(선택 사항).
1.18.2. 속성
delayTime, 타입 AudioParam, 읽기 전용-
지연(초 단위)을 나타내는
AudioParam객체입니다. 기본value는 0(지연 없음)입니다. 최소값은 0이고, 최대값은maxDelayTime인자(AudioContext의createDelay()) 또는maxDelayTime(DelayOptions딕셔너리,생성자)로 결정됩니다.DelayNode가 순환의 일부인 경우,delayTime속성 값은 최소 한 렌더 퀀텀으로 클램핑됩니다.파라미터 값 비고 defaultValue0 minValue0 maxValuemaxDelayTimeautomationRate" a-rate"
1.18.3. DelayOptions
이 객체는 DelayNode 생성에
사용할 옵션을 지정합니다. 모든 멤버는 선택 사항이며,
주어지지 않으면 노드는 기본값으로 생성됩니다.
dictionary DelayOptions :AudioNodeOptions {double maxDelayTime = 1;double delayTime = 0; };
1.18.3.1. 딕셔너리 DelayOptions
멤버
delayTime, 타입 double, 기본값0-
노드의 초기 지연 시간입니다.
maxDelayTime, 타입 double, 기본값1-
노드의 최대 지연 시간입니다. 제약에 대한 자세한 내용은
createDelay(maxDelayTime)를 참조하세요.
1.18.4. 처리
DelayNode
는 delayTime
초의 오디오를 저장하는 내부 버퍼를 가집니다.
DelayNode의 처리
과정은 지연 라인에 쓰기와 읽기 두 부분으로 나뉩니다. 이는 두 개의 내부 AudioNode를 통해
이루어지며, 이들은 작성자에게 노출되지 않으며 노드 내부 동작을 설명하기 위해서만 존재합니다. 두 노드는 모두 DelayNode에서
생성됩니다.
DelayWriter를 DelayNode에 대해
생성한다는 것은 AudioNode와
동일한 인터페이스를 가진 객체를 생성하며, 입력 오디오를 DelayNode의 내부
버퍼에 기록합니다. 입력 연결도 생성된 DelayNode와
동일합니다.
DelayReader를 DelayNode에 대해
생성한다는 것은 AudioNode와
동일한 인터페이스를 가진 객체를 생성하며, DelayNode의 내부
버퍼에서 오디오 데이터를 읽을 수 있습니다. 출력 연결도 생성된 DelayNode와
동일하게 연결됩니다. DelayReader는 source node 입니다.
입력 버퍼를 처리할 때 DelayWriter는 오디오를 DelayNode의 내부
버퍼에 반드시 기록해야 합니다.
출력 버퍼를 생성할 때 DelayReader는 DelayWriter가 정확히 delayTime초 전에
기록한 오디오를 반드시 반환해야 합니다.
참고: 즉, 채널 수 변경은 지연 시간이 지난 후 반영됩니다.
1.19. DynamicsCompressorNode
인터페이스
DynamicsCompressorNode
는 다이나믹스 컴프레션 효과를 구현하는 AudioNode
프로세서입니다.
다이나믹스 컴프레션은 음악 제작과 게임 오디오에서 매우 흔하게 사용됩니다. 신호에서 가장 소리가 큰 부분의 볼륨을 낮추고, 가장 작은 부분의 볼륨을 높입니다. 전체적으로 더 크고 풍부하며 꽉 찬 사운드를 얻을 수 있습니다. 특히 음악이나 게임처럼 동시에 여러 개의 소리가 재생되는 환경에서 전체 신호 레벨을 제어하고 오디오 출력의 클리핑(왜곡)을 방지하는 데 중요합니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 제약 있음 |
channelCountMode
| "clamped-max"
| channelCountMode 제약 있음 |
channelInterpretation
| "speakers"
| |
| tail-time | 예 | 이 노드는 look-ahead 딜레이로 인해 입력이 0이어도 tail-time 동안 무음이 아닌 오디오를 계속 출력합니다. |
[Exposed =Window ]interface DynamicsCompressorNode :AudioNode {constructor (BaseAudioContext ,context optional DynamicsCompressorOptions = {});options readonly attribute AudioParam threshold ;readonly attribute AudioParam knee ;readonly attribute AudioParam ratio ;readonly attribute float reduction ;readonly attribute AudioParam attack ;readonly attribute AudioParam release ; };
1.19.1. 생성자
DynamicsCompressorNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.[[internal reduction]]은 this에 비공개 슬롯으로 부여되는 부동 소수점(데시벨 단위) 값입니다.[[internal reduction]]을 0.0으로 설정합니다.DynamicsCompressorNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 DynamicsCompressorNode가 연결될BaseAudioContext입니다.optionsDynamicsCompressorOptions✘ ✔ 이 DynamicsCompressorNode의 초기 파라미터 값(선택 사항).
1.19.2. 속성
attack, 타입 AudioParam, 읽기 전용-
이 파라미터는 10dB만큼 게인을 줄이는 데 걸리는 시간(초)입니다.
파라미터 값 비고 defaultValue.003 minValue0 maxValue1 automationRate" k-rate"automation rate 제약 knee, 타입 AudioParam, 읽기 전용-
임계값 위에서 곡선이 "ratio" 부분으로 부드럽게 전이되는 범위를 나타내는 데시벨 값입니다.
파라미터 값 비고 defaultValue30 minValue0 maxValue40 automationRate" k-rate"automation rate 제약 ratio, 타입 AudioParam, 읽기 전용-
출력 1dB 변화에 대해 입력이 변해야 하는 dB 양입니다.
파라미터 값 비고 defaultValue12 minValue1 maxValue20 automationRate" k-rate"automation rate 제약 reduction, 타입 float, 읽기 전용-
미터링 용도의 읽기 전용 데시벨 값으로, 컴프레서가 신호에 적용하는 현재 게인 감소량을 나타냅니다. 신호가 없으면 값은 0(게인 감소 없음)입니다. 이 속성이 읽히면 비공개 슬롯
[[internal reduction]]값을 반환합니다. release, 타입 AudioParam, 읽기 전용-
이 파라미터는 10dB만큼 게인을 증가시키는 데 걸리는 시간(초)입니다.
파라미터 값 비고 defaultValue.25 minValue0 maxValue1 automationRate" k-rate"automation rate 제약 threshold, 타입 AudioParam, 읽기 전용-
컴프레션이 적용되기 시작하는 임계값(데시벨)입니다.
파라미터 값 비고 defaultValue-24 minValue-100 maxValue0 automationRate" k-rate"automation rate 제약
1.19.3. DynamicsCompressorOptions
이 객체는 DynamicsCompressorNode
생성 시 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary DynamicsCompressorOptions :AudioNodeOptions {float attack = 0.003;float knee = 30;float ratio = 12;float release = 0.25;float threshold = -24; };
1.19.3.1. 딕셔너리 DynamicsCompressorOptions
멤버
attack, 타입 float, 기본값0.003-
attackAudioParam의 초기값입니다. knee, 타입 float, 기본값30-
kneeAudioParam의 초기값입니다. ratio, 타입 float, 기본값12-
ratioAudioParam의 초기값입니다. release, 타입 float, 기본값0.25-
releaseAudioParam의 초기값입니다. threshold, 타입 float, 기본값-24-
thresholdAudioParam의 초기값입니다.
1.19.4. 처리
다이나믹스 컴프레션은 다양한 방법으로 구현할 수 있습니다. DynamicsCompressorNode
는 다음과 같은 특성을 가진 다이나믹스 프로세서를 구현합니다:
-
고정된 look-ahead(즉,
DynamicsCompressorNode는 신호 체인에 고정된 레이턴시를 추가합니다). -
공격 속도, 릴리즈 속도, 임계값, knee 경도, ratio를 설정할 수 있습니다.
-
사이드체이닝은 지원되지 않습니다.
-
게인 감소량은
reduction속성을 통해DynamicsCompressorNode에서 확인할 수 있습니다. -
컴프레션 곡선은 세 부분으로 구성됩니다:
-
첫 번째 부분은 항등함수: \(f(x) = x\)
-
두 번째 부분은 soft-knee로, 반드시 단조 증가 함수여야 합니다.
-
세 번째 부분은 선형 함수: \(f(x) = \frac{1}{ratio} \cdot x \)
이 곡선은 반드시 연속적이고 구간별로 미분 가능해야 하며, 입력 레벨에 따라 타겟 출력 레벨을 결정합니다.
-
그래프 형태는 다음과 같습니다:

내부적으로 DynamicsCompressorNode
는 기타 AudioNode와
특별한 알고리즘을 조합하여 게인 감소값을 계산합니다.
내부적으로 다음 AudioNode
그래프가 사용되며, input과 output은 각각 입력/출력 AudioNode,
context는 BaseAudioContext,
그리고 아래 설명된 EnvelopeFollower라는 특수 객체가 사용됩니다:
const delay = new DelayNode(context, {delayTime: 0.006});
const gain = new GainNode(context);
const compression = new EnvelopeFollower();
input.connect(delay).connect(gain).connect(output);
input.connect(compression).connect(gain.gain);

DynamicsCompressorNode
처리 알고리즘에 사용되는 내부 AudioNode
그래프 참고: 이 그래프는 pre-delay와 리덕션 게인 적용을 구현합니다.
다음 알고리즘은 EnvelopeFollower 객체가 입력 신호에 대해 게인 감소값을 산출하는 과정을 설명합니다. EnvelopeFollower는 float 값을 저장하는 두 슬롯을 가지며, 이 값은 알고리즘 실행 간 유지됩니다.
-
[[detector average]]는 float 값이며, 0.0으로 초기화됩니다. -
[[compressor gain]]는 float 값이며, 1.0으로 초기화됩니다.
-
attack과 release는
attack및release값이며, 처리 시점에서 샘플링되고(k-rate 파라미터),BaseAudioContext의 샘플레이트로 곱해집니다. -
detector average는
[[detector average]]슬롯의 값입니다. -
compressor gain는
[[compressor gain]]슬롯의 값입니다. -
처리 대상 렌더 퀀텀의 각 input 샘플에 대해 다음을 실행합니다:
-
input의 절대값이 0.0001 미만이면 attenuation을 1.0으로 설정. 아니면 절대값에 compression curve를 적용한 값을 shaped input으로 하고, attenuation을 shaped input을 input의 절대값으로 나눈 값으로 설정.
-
attenuation이 compressor gain보다 크면 releasing을
true로, 아니면false로 설정. -
detector rate는 attenuation에 detector curve를 적용한 값.
-
detector average에서 attenuation을 빼고, detector rate를 곱함. 결과를 detector average에 더함.
-
detector average를 최대 1.0으로 클램핑.
-
envelope rate는 envelope rate 계산을 통해 attack과 release 값으로 구함.
-
releasing이
true면 compressor gain에 envelope rate를 곱하고, 최대 1.0으로 클램핑. -
아니면 gain increment를 detector average에서 compressor gain을 뺀 값으로 하고, envelope rate를 곱한 뒤 compressor gain에 더함.
-
reduction gain을 compressor gain에 makeup gain 계산의 반환값을 곱한 값으로 계산.
-
metering gain을 reduction gain을 데시벨 변환한 값으로 계산.
-
-
[[compressor gain]]에 compressor gain을 설정. -
[[detector average]]에 detector average를 설정. -
원자적으로 내부 슬롯
[[internal reduction]]에 metering gain 값을 설정.참고: 이 단계에서 미터링 게인은 블록 처리 종료 시점에 한 번 갱신됩니다.
makeup gain은 ratio, knee, threshold만 의존하는 고정 게인 스테이지로, 입력 신호와는 무관합니다. 목적은 컴프레서 출력 레벨을 입력 레벨과 비슷하게 높이는 것입니다.
-
full range gain을 compression curve에 1.0을 적용한 값으로 설정.
-
full range makeup gain을 full range gain의 역수로 설정.
-
full range makeup gain의 0.6제곱을 반환.
-
envelope rate는 compressor gain과 detector average의 비율에서 계산되어야 합니다.
참고: attack 중에는 이 값이 1 이하, release 중에는 1보다 큽니다.
-
attack 곡선은 \([0, 1]\) 구간에서 연속적이고 단조 증가 함수여야 하며, 곡선 형태는
attack으로 조절할 수 있습니다. -
release 곡선은 항상 1보다 크고, 연속적이며 단조 감소 함수여야 하며, 곡선 형태는
release로 조절할 수 있습니다.
이 연산은 compressor gain과 detector average의 비율에 이 함수를 적용한 값을 반환합니다.
detector curve를 변화율에 적용하여 어택 또는 릴리스 시 적응형 릴리스를 구현할 수 있습니다. 이 기능은 다음 제약 조건을 반드시 준수해야 합니다:
-
함수 출력은 \([0,1]\) 범위여야 합니다.
-
함수는 단조 증가, 연속적이어야 합니다.
참고: 예를 들어 adaptive release(압축이 강할수록 더 빨리 release)나 attack/release 곡선의 형태가 다를 수 있습니다.
-
threshold와 knee는 각각
threshold및knee값이고, 선형 유닛 변환 후 처리 시점에 샘플링(k-rate 파라미터)됩니다. -
knee end threshold는 그 합을 선형 유닛 변환한 값입니다.
-
이 함수는 선형 threshold까지는 항등함수(\(f(x) = x\))입니다.
-
threshold에서 knee end threshold까지는 User-Agent가 곡선 형태를 선택할 수 있으며, 전체 함수는 단조 증가, 연속이어야 합니다.
참고: knee가 0이면
DynamicsCompressorNode는 hard-knee 컴프레서입니다. -
이 함수는 soft knee 이후에는 ratio에 따라 선형(\(f(x) = \frac{1}{ratio} \cdot x\))입니다.
-
\(v\)가 0이면 -1000을 반환.
-
그 외에는 \( 20 \, \log_{10}{v} \) 값을 반환.
1.20. GainNode
인터페이스
오디오 신호의 게인(gain)을 변경하는 것은 오디오 응용에서 기본적인 동작입니다. 이
인터페이스는 입력과 출력이 하나씩 있는 AudioNode입니다:
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
GainNode의 입력 데이터
각 채널의 각 샘플은 반드시 gain
AudioParam의
computedValue로 곱해져야 합니다.
[Exposed =Window ]interface GainNode :AudioNode {constructor (BaseAudioContext ,context optional GainOptions = {});options readonly attribute AudioParam gain ; };
1.20.1. 생성자
GainNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.GainNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 GainNode가 연결될BaseAudioContext입니다.optionsGainOptions✘ ✔ 이 GainNode의 초기 파라미터 값(선택 사항).
1.20.2. 속성
gain, 타입 AudioParam, 읽기 전용-
적용할 게인(gain) 값입니다.
파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"
1.20.3. GainOptions
이 객체는 GainNode
생성에 사용할 옵션을 지정합니다. 모든 멤버는 선택 사항이며,
지정하지 않으면 기본값이 사용됩니다.
dictionary GainOptions :AudioNodeOptions {float gain = 1.0; };
1.20.3.1. 딕셔너리 GainOptions
멤버
gain, 타입 float, 기본값1.0-
이
gainAudioParam의 초기값입니다.
1.21. IIRFilterNode
인터페이스
IIRFilterNode
는 AudioNode
프로세서로, 일반적인 IIR 필터를 구현합니다. 일반적으로는 다음과 같은 이유로 BiquadFilterNode를
사용해 고차 필터를 구현하는 것이 더 좋습니다:
-
일반적으로 수치적 이슈에 덜 민감함
-
필터 파라미터 자동화 가능
-
모든 짝수 차수의 IIR 필터 구현 가능
하지만 홀수 차수 필터는 만들 수 없으므로, 그런 필터가 필요하거나 자동화가 필요하지 않을 때는 IIR 필터가 적합할 수 있습니다.
한 번 생성되면 IIR 필터의 계수는 변경할 수 없습니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 예 | 입력이 0이어도 무음이 아닌 오디오가 계속 출력됨. IIR 필터 특성상 필터는 영원히 0이 아닌 출력을 만드지만, 실제로는 일정 시간이 지나면 출력이 충분히 0에 가까워집니다. 실제 시간은 계수에 따라 다릅니다. |
출력 채널 수는 항상 입력 채널 수와 같습니다.
[Exposed =Window ]interface IIRFilterNode :AudioNode {constructor (BaseAudioContext ,context IIRFilterOptions );options undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.21.1. 생성자
IIRFilterNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.IIRFilterNode.constructor() 메서드 인자 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 IIRFilterNode가 연결될BaseAudioContext입니다.optionsIIRFilterOptions✘ ✘ 이 IIRFilterNode의 초기 파라미터 값
1.21.2. 메서드
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
현재 필터 파라미터 설정값을 기준으로, 지정된 주파수에 대한 주파수 응답을 동기적으로 계산합니다. 세 파라미터는 반드시 동일한 길이의
Float32Array여야 하며, 그렇지 않으면InvalidAccessError가 반드시 발생해야 합니다.IIRFilterNode.getFrequencyResponse() 메서드 인자. 파라미터 타입 Nullable Optional 설명 frequencyHzFloat32Array✘ ✘ 응답값을 계산할 Hz 단위의 주파수 배열입니다. magResponseFloat32Array✘ ✘ 각 frequencyHz값에 대한 선형 크기 응답값을 받는 출력 배열입니다.frequencyHz값이 [0, sampleRate/2] 범위를 벗어나면 해당 인덱스의magResponse값은NaN이어야 합니다. sampleRate는sampleRate속성 값입니다.phaseResponseFloat32Array✘ ✘ 각 frequencyHz값에 대한 라디안 단위의 위상 응답값을 받는 출력 배열입니다.frequencyHz값이 [0, sampleRate/2] 범위를 벗어나면 해당 인덱스의phaseResponse값은NaN이어야 합니다. sampleRate는sampleRate속성 값입니다.반환 타입:undefined
1.21.3.
IIRFilterOptions
IIRFilterOptions 딕셔너리는 IIRFilterNode의
필터 계수를 지정하는 데 사용됩니다.
dictionary IIRFilterOptions :AudioNodeOptions {required sequence <double >feedforward ;required sequence <double >feedback ; };
1.21.3.1. 딕셔너리 IIRFilterOptions
멤버
feedforward, 타입 sequence<double>-
IIRFilterNode의 feedforward 계수입니다. 필수 멤버입니다. 다른 제약사항은feedforward인자와createIIRFilter()를 참조하세요. feedback, 타입 sequence<double>-
IIRFilterNode의 feedback 계수입니다. 필수 멤버입니다. 다른 제약사항은feedback인자와createIIRFilter()를 참조하세요.
1.21.4. 필터 정의
\(b_m\)은 feedforward 계수이고
\(a_n\)은 feedback 계수입니다. createIIRFilter()
또는 IIRFilterOptions
딕셔너리에서 지정합니다.
일반적인 IIR 필터의 전달 함수는 다음과 같습니다:
$$
H(z) = \frac{\sum_{m=0}^{M} b_m z^{-m}}{\sum_{n=0}^{N} a_n z^{-n}}
$$
여기서 \(M + 1\)은 \(b\) 배열의 길이, \(N + 1\)은 \(a\) 배열의 길이입니다. \(a_0\)은 0이면 안 됩니다(feedback parameter와
createIIRFilter()
참조).
\(b_m\) 중 적어도 하나는 0이 아니어야 합니다(feedforward parameter와
createIIRFilter()
참조).
동일하게, 시간 영역에서는 다음과 같이 표현됩니다:
$$
\sum_{k=0}^{N} a_k y(n-k) = \sum_{k=0}^{M} b_k x(n-k)
$$
필터의 초기 상태는 모두 0입니다.
참고: UA는 필터 상태에 NaN 값이 발생하면 경고를 표시할 수 있습니다. 이는 보통 불안정한 필터의 신호입니다.
1.22.
MediaElementAudioSourceNode
인터페이스
이 인터페이스는
audio
또는
video
요소에서 오디오 소스를 나타냅니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time reference | 없음 |
출력 채널 수는 HTMLMediaElement가
참조하는 미디어의 채널 수와 같습니다.
따라서 미디어 요소의 src 속성이 변경되면 이 노드의 출력 채널 수도 변경될 수 있습니다.
HTMLMediaElement의
샘플레이트가 연결된 AudioContext의
샘플레이트와 다를 경우,
HTMLMediaElement의
출력은 컨텍스트의 샘플레이트에
맞게 리샘플링되어야 합니다.
MediaElementAudioSourceNode
는 HTMLMediaElement를
사용해 AudioContext의
createMediaElementSource()
메서드 또는 mediaElement
멤버(MediaElementAudioSourceOptions
딕셔너리, 생성자)로
생성됩니다.
단일 출력의 채널 수는 HTMLMediaElement를
createMediaElementSource()
인자로 전달할 때 참조하는 오디오의 채널 수와 같거나, HTMLMediaElement에
오디오가 없으면 1입니다.
HTMLMediaElement
는 MediaElementAudioSourceNode
생성 후에도 동작 방식이 동일하게 유지되어야 하며,
단 렌더링된 오디오는 더 이상 직접 들리지 않고, MediaElementAudioSourceNode가
라우팅 그래프에 연결됨에 따라 들리게 됩니다. 즉, 일시정지, 탐색, 볼륨, src 속성 변경 및 HTMLMediaElement
의 다른 동작은 MediaElementAudioSourceNode를
사용하지 않은 것과 동일하게 작동해야 합니다.
const mediaElement= document. getElementById( 'mediaElementID' ); const sourceNode= context. createMediaElementSource( mediaElement); sourceNode. connect( filterNode);
[Exposed =Window ]interface MediaElementAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaElementAudioSourceOptions ); [options SameObject ]readonly attribute HTMLMediaElement mediaElement ; };
1.22.1. 생성자
MediaElementAudioSourceNode(context, options)-
-
AudioNode를 초기화 this, context와 options를 인자로 사용합니다.
MediaElementAudioSourceNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextAudioContext✘ ✘ 이 새로운 MediaElementAudioSourceNode가 연결될AudioContext입니다.optionsMediaElementAudioSourceOptions✘ ✘ 이 MediaElementAudioSourceNode의 초기 파라미터 값 -
1.22.2. 속성
mediaElement, 타입 HTMLMediaElement, 읽기 전용-
이
MediaElementAudioSourceNode를 생성할 때 사용된HTMLMediaElement입니다.
1.22.3.
MediaElementAudioSourceOptions
이 객체는 MediaElementAudioSourceNode를
생성할 때 사용할 옵션을 지정합니다.
dictionary MediaElementAudioSourceOptions {required HTMLMediaElement mediaElement ; };
1.22.3.1. 딕셔너리 MediaElementAudioSourceOptions
멤버
mediaElement, 타입 HTMLMediaElement-
재라우팅할 미디어 요소입니다. 반드시 지정해야 합니다.
1.22.4. MediaElementAudioSourceNode와 크로스 오리진 리소스 보안
HTMLMediaElement
는 크로스 오리진 리소스 재생을 허용합니다. Web Audio에서는 MediaElementAudioSourceNode,
AudioWorkletNode,
ScriptProcessorNode
등으로 리소스의 샘플을 읽을 수 있으므로,
한 origin의 스크립트가 다른 origin의 리소스를 검사하면 정보 유출이 발생할 수
있습니다.
이를 방지하기 위해, MediaElementAudioSourceNode
는 HTMLMediaElement가
fetch 알고리즘에 의해 CORS-cross-origin으로 라벨링된 경우,
정상 출력 대신 무음을 출력해야 합니다.
1.23.
MediaStreamAudioDestinationNode
인터페이스
이 인터페이스는 MediaStream을
나타내는 오디오 도착지로,
MediaStreamTrack의
kind가 "audio"인 단일 트랙을 가집니다. 이 MediaStream은
노드가 생성될 때 만들어지며, stream
속성을 통해 접근할 수 있습니다. 이 스트림은 MediaStream을
getUserMedia()로
얻은 것과 비슷하게 사용할 수 있으며,
예를 들어 RTCPeerConnection([webrtc] 참고)의 addStream() 메서드로 원격
피어에게 보낼 수 있습니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 0 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
입력 채널 수는 기본값이 2(스테레오)입니다.
[Exposed =Window ]interface MediaStreamAudioDestinationNode :AudioNode {constructor (AudioContext ,context optional AudioNodeOptions = {});options readonly attribute MediaStream stream ; };
1.23.1. 생성자
MediaStreamAudioDestinationNode(context, options)-
-
AudioNode를 초기화 this, context와 options를 인자로 사용합니다.
MediaStreamAudioDestinationNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextAudioContext✘ ✘ 이 새로운 BaseAudioContext에MediaStreamAudioDestinationNode가 연결됩니다.optionsAudioNodeOptions✘ ✔ 이 MediaStreamAudioDestinationNode의 선택적 초기 파라미터 값입니다. -
1.23.2. 속성
stream, 타입 MediaStream, 읽기 전용-
이
MediaStream에는 노드와 동일한 채널 수를 가지며,MediaStreamTrack의kind속성이"audio"인 단일 트랙만 포함됩니다.
1.24. MediaStreamAudioSourceNode
인터페이스
이 인터페이스는 MediaStream에서
오디오 소스를 나타냅니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time reference | 없음 |
출력 채널 수는 MediaStreamTrack의
채널 수와 같습니다.
MediaStreamTrack이
종료되면, 이 AudioNode는
하나의 채널로 무음을 출력합니다.
MediaStreamTrack의
샘플레이트가 연결된 AudioContext의
샘플레이트와 다를 경우,
MediaStreamTrack의
출력은 컨텍스트의 샘플레이트에
맞게 리샘플링됩니다.
[Exposed =Window ]interface MediaStreamAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamAudioSourceOptions ); [options SameObject ]readonly attribute MediaStream mediaStream ; };
1.24.1. 생성자
MediaStreamAudioSourceNode(context, options)-
-
mediaStream멤버가options에 지정되지 않았거나,MediaStream에MediaStreamTrack중kind가"audio"인 트랙이 하나도 없으면,InvalidStateError를 발생시키고 절차를 중단합니다. 그렇지 않으면 이 스트림을 inputStream으로 지정합니다. -
tracks를 inputStream의 모든
MediaStreamTrack중kind가"audio"인 트랙의 목록으로 만듭니다. -
tracks의 각 요소를
id속성을 기준으로 코드 유닛 값의 시퀀스로 정렬합니다. -
AudioNode를 초기화 this, context와 options를 인자로 사용합니다.
-
이
MediaStreamAudioSourceNode에 내부 슬롯[[input track]]을 tracks의 첫 번째 요소로 설정합니다. 이 트랙이 해당MediaStreamAudioSourceNode의 입력 오디오로 사용됩니다.
생성 후, 생성자에 전달된
MediaStream의 변경은 이AudioNode의 출력에 영향을 주지 않습니다.[[input track]]슬롯은MediaStreamTrack을 참조하기 위해서만 사용됩니다.참고: 생성자에서 선택된 트랙을
MediaStreamAudioSourceNode에 전달된MediaStream에서 제거하더라도,MediaStreamAudioSourceNode는 여전히 같은 트랙에서 입력을 받습니다.참고: 출력 트랙 선택 방식은 레거시 이유로 임의적입니다.
MediaStreamTrackAudioSourceNode를 사용하면 입력 트랙을 명확히 지정할 수 있습니다.MediaStreamAudioSourceNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextAudioContext✘ ✘ 이 새로운 AudioContext에 연결됩니다.optionsMediaStreamAudioSourceOptions✘ ✘ 이 MediaStreamAudioSourceNode의 초기 파라미터 값 -
1.24.2. 속성
mediaStream, 타입 MediaStream, 읽기 전용-
이
MediaStreamAudioSourceNode를 생성할 때 사용된MediaStream입니다.
1.24.3.
MediaStreamAudioSourceOptions
이 객체는 MediaStreamAudioSourceNode를
생성할 때 사용할 옵션을 지정합니다.
dictionary MediaStreamAudioSourceOptions {required MediaStream mediaStream ; };
1.24.3.1. 딕셔너리 MediaStreamAudioSourceOptions
멤버
mediaStream, 타입 MediaStream-
소스 역할을 할 미디어 스트림입니다. 반드시 지정해야 합니다.
1.25.
MediaStreamTrackAudioSourceNode
인터페이스
이 인터페이스는 MediaStreamTrack에서
오디오 소스를 나타냅니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| tail-time reference | 없음 |
출력 채널 수는 mediaStreamTrack의
채널 수와 같습니다.
MediaStreamTrack의
샘플레이트가 연결된 AudioContext의
샘플레이트와 다를 경우,
mediaStreamTrack의
출력은 컨텍스트의 샘플레이트에
맞게 리샘플링됩니다.
[Exposed =Window ]interface MediaStreamTrackAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamTrackAudioSourceOptions ); };options
1.25.1. 생성자
MediaStreamTrackAudioSourceNode(context, options)-
-
mediaStreamTrack의kind속성이"audio"가 아니면InvalidStateError를 발생시키고 절차를 중단합니다. -
AudioNode를 초기화 this, context와 options를 인자로 사용합니다.
MediaStreamTrackAudioSourceNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextAudioContext✘ ✘ 이 새로운 AudioContext에 연결됩니다.optionsMediaStreamTrackAudioSourceOptions✘ ✘ 이 MediaStreamTrackAudioSourceNode의 초기 파라미터 값 -
1.25.2. MediaStreamTrackAudioSourceOptions
이 객체는 MediaStreamTrackAudioSourceNode를
생성할 때 사용할 옵션을 지정합니다.
필수입니다.
dictionary MediaStreamTrackAudioSourceOptions {required MediaStreamTrack mediaStreamTrack ; };
1.25.2.1. 딕셔너리 MediaStreamTrackAudioSourceOptions
멤버
mediaStreamTrack, 타입 MediaStreamTrack-
소스 역할을 할 미디어 스트림 트랙입니다.
MediaStreamTrack의kind속성이"audio"가 아니면InvalidStateError를 반드시 발생시켜야 합니다.
1.26. OscillatorNode
인터페이스
OscillatorNode
는 주기적인 파형을 생성하는 오디오 소스를 나타냅니다. 몇 가지 흔히 쓰이는 파형을 설정할 수 있으며, PeriodicWave
객체를 이용해 임의의 주기파도 설정할 수 있습니다.
오실레이터는 오디오 신디사이저의 기본적인 구성 요소입니다. OscillatorNode는 start()
메서드로 지정된 시간에 소리를 내기 시작합니다.
수학적으로 연속 시간 주기파형은 주파수 영역에서 매우 높은(혹은 무한히 높은) 주파수 정보를 가질 수 있습니다. 이 파형을 특정 샘플레이트로 샘플링된 디지털 오디오 신호로 변환할 때는, 나이퀴스트 주파수를 초과하는 고주파 정보를 반드시 버려야(필터링해야) 디지털로 변환할 수 있습니다. 그렇지 않으면 에일리어싱이 발생해 나이퀴스트 주파수 이하의 주파수로 고주파수가 접혀서 나타납니다. 이는 듣기에 불쾌한 인공음이 생길 수 있습니다. 오디오 DSP의 기본 원리입니다.
이런 에일리어싱을 방지하기 위해 구현에서는 여러 가지 실용적 접근법이 있습니다. 어떤 방법을 쓰더라도 이상적인 이산 시간 디지털 오디오 신호는 수학적으로 잘 정의되어 있습니다. 구현의 트레이드 오프는 CPU 사용량 등 구현 비용과 이 이상 실현 사이의 문제입니다.
구현체는 이 이상에 가깝게 하려고 노력하겠지만, 저가형 하드웨어에서는 품질이 낮고 비용이 적은 방법을 쓸 수도 있습니다.
frequency와
detune
모두 a-rate 파라미터이며 복합 파라미터를 이룹니다.
두 값은 함께 computedOscFrequency 값을 결정합니다:
computedOscFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
OscillatorNode의 순간 위상은 시작 시점에 위상이 0이라고 가정하고 computedOscFrequency의 시간적 적분으로 구합니다. 공칭 범위는 [-나이퀴스트 주파수, 나이퀴스트 주파수]입니다.
이 노드의 단일 출력은 한 채널(모노)로 구성됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
enum {OscillatorType "sine" ,"square" ,"sawtooth" ,"triangle" ,"custom" };
| 열거값 | 설명 |
|---|---|
"sine"
| 사인파 |
"square"
| 듀티 비율 0.5인 구형파 |
"sawtooth"
| 톱니파 |
"triangle"
| 삼각파 |
"custom"
| 사용자 정의 주기파 |
[Exposed =Window ]interface OscillatorNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional OscillatorOptions = {});options attribute OscillatorType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;undefined setPeriodicWave (PeriodicWave ); };periodicWave
1.26.1. 생성자
OscillatorNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.OscillatorNode.constructor() 메서드 인자 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 OscillatorNode가 연결될BaseAudioContext입니다.optionsOscillatorOptions✘ ✔ 이 OscillatorNode의 초기 파라미터 값(선택 사항)
1.26.2. 속성
detune, 타입 AudioParam, 읽기 전용-
주어진 값만큼
frequency를 오프셋하는 센트 단위의 디튠 값입니다. 기본value는 0입니다. 본 파라미터는 a-rate입니다.frequency와 함께 복합 파라미터를 구성하여 computedOscFrequency를 형성합니다. 아래 공칭 범위는frequency를 전체 주파수 범위로 디튠할 수 있게 합니다.파라미터 값 비고 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) 이 값은 \(1200\ \log_2 \mathrm{FLT\_MAX}\) (FLT_MAX: float형 최대값)의 근사치입니다. automationRate" a-rate" frequency, 타입 AudioParam, 읽기 전용-
주기파의 주파수(Hz)입니다. 기본
value는 440입니다. 본 파라미터는 a-rate입니다.detune와 함께 복합 파라미터를 구성하여 computedOscFrequency를 형성합니다. 공칭 범위는 [-나이퀴스트 주파수, 나이퀴스트 주파수]입니다.파라미터 값 비고 defaultValue440 minValue-나이퀴스트 주파수 maxValue나이퀴스트 주파수 automationRate" a-rate" type, 타입 OscillatorType-
주기파의 형태입니다. "
custom" 외의 타입 상수 값으로 직접 설정할 수 있습니다. 이 경우InvalidStateError예외를 반드시 발생시켜야 합니다.setPeriodicWave()메서드로 사용자 정의 파형을 설정하면 이 속성은 "custom"이 됩니다. 기본값은 "sine"입니다. 이 속성을 설정하면 오실레이터의 위상은 반드시 보존되어야 합니다.
1.26.3. 메서드
setPeriodicWave(periodicWave)-
PeriodicWave를 이용해 임의의 사용자 정의 주기파를 설정합니다.OscillatorNode.setPeriodicWave() 메서드 인자. 파라미터 타입 Nullable Optional 설명 periodicWavePeriodicWave✘ ✘ 오실레이터에 사용할 사용자 정의 파형 반환 타입:undefined
1.26.4.
OscillatorOptions
이 객체는 OscillatorNode
생성 시 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며,
지정하지 않으면 오실레이터 생성 시 기본값이 사용됩니다.
dictionary OscillatorOptions :AudioNodeOptions {OscillatorType type = "sine";float frequency = 440;float detune = 0;PeriodicWave periodicWave ; };
1.26.4.1. 딕셔너리 OscillatorOptions
멤버
detune, 타입 float, 기본값0-
OscillatorNode의 초기 디튠 값입니다. frequency, 타입 float, 기본값440-
OscillatorNode의 초기 주파수입니다. periodicWave, 타입 PeriodicWave-
OscillatorNode에 사용할PeriodicWave입니다. 이를 지정하면type값은 무시되고, "custom"으로 처리됩니다. type, 타입 OscillatorType, 기본값"sine"-
생성할 오실레이터의 타입입니다. "custom"으로 지정하면서
periodicWave를 지정하지 않으면InvalidStateError예외를 반드시 발생시켜야 합니다.periodicWave를 지정하면type값은 무시되고 "custom"으로 처리됩니다.
1.26.5. 기본 파형 위상
아래에서 여러 오실레이터 타입의 이상적 수학적 파형을 정의합니다. 요약하면, 모든 파형은 시간 0에서 양의 기울기를 가진 홀수 함수로 정의됩니다. 오실레이터가 실제로 생성하는 파형은 에일리어싱 방지로 인해 차이가 있을 수 있습니다.
오실레이터는 해당 푸리에 급수와 disableNormalization이
false로 설정된 PeriodicWave를
사용한 것과 동일한 결과를 반드시 내야 합니다.
- "
sine" -
사인 오실레이터의 파형은 다음과 같습니다:
$$ x(t) = \sin t $$ - "
square" -
구형파 오실레이터의 파형은 다음과 같습니다:
$$ x(t) = \begin{cases} 1 & \mbox{if } 0≤ t < \pi \\ -1 & \mbox{if } -\pi < t < 0. \end{cases} $$이는 파형이 \(2\pi\) 주기의 홀수 함수임을 이용해 모든 \(t\)에 확장됩니다.
- "
sawtooth" -
톱니파 오실레이터의 파형은 램프입니다:
$$ x(t) = \frac{t}{\pi} \mbox{ for } -\pi < t ≤ \pi; $$이는 파형이 \(2\pi\) 주기의 홀수 함수임을 이용해 모든 \(t\)에 확장됩니다.
- "
triangle" -
삼각파 오실레이터의 파형은 다음과 같습니다:
$$ x(t) = \begin{cases} \frac{2}{\pi} t & \mbox{if } 0 ≤ t ≤ \frac{\pi}{2} \\ 1-\frac{2}{\pi} \left(t-\frac{\pi}{2}\right) & \mbox{if } \frac{\pi}{2} < t ≤ \pi. \end{cases} $$이는 파형이 \(2\pi\) 주기의 홀수 함수임을 이용해 모든 \(t\)에 확장됩니다.
1.27. PannerNode
인터페이스
이 인터페이스는 입력 오디오 스트림을 3차원 공간에서 위치/공간화하는 처리 노드를 나타냅니다.
공간화는 BaseAudioContext의
AudioListener
(listener
속성)과의 관계에 따라 이루어집니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 제약 있음 |
channelCountMode
| "clamped-max"
| channelCountMode 제약 있음 |
channelInterpretation
| "speakers"
| |
| tail-time | Maybe | panningModel
이 "HRTF"로
설정된 경우,
헤드 응답 처리 때문에 무음 입력에도 비무음 출력을 생성합니다. 그렇지 않으면 tail-time은 0입니다.
|
이 노드의 입력은 모노(1채널) 또는 스테레오(2채널)이며, 채널 수를 늘릴 수 없습니다. 채널 수가 더 적거나 많은 노드에서 연결될 경우 적절히 업믹스 또는 다운믹스됩니다.
노드가 실행 중이라면 출력은 하드코딩된 스테레오(2채널)이며, 구성할 수 없습니다. 실행 중이 아니면 출력은 단일 채널 무음입니다.
PanningModelType
열거형은 오디오를 3D 공간에 배치할 때 사용할 공간화 알고리즘을 결정합니다. 기본값은 "equalpower"입니다.
enum {PanningModelType "equalpower" ,"HRTF" };
| 열거값 | 설명 |
|---|---|
"equalpower"
|
equal-power 패닝을 사용하는 간단하고 효율적인 공간화 알고리즘입니다.
참고: 이 패닝 모델이 사용될 때, 출력 계산에 사용되는 모든
|
"HRTF"
|
인간 대상에서 측정된 임펄스 응답을 사용한 컨볼루션 기반의 고품질 공간화 알고리즘입니다. 이 패닝 방식은 스테레오 출력을 생성합니다.
참고: 이 패닝 모델이 사용될 때, 출력 계산에 사용되는 모든
|
effective
automation rate는 AudioParam의
PannerNode에서
panningModel과
automationRate에
의해 결정됩니다.
panningModel이
"HRTF"인
경우, effective automation rate는 k-rate가
되며, automationRate
설정과는 무관합니다.
그렇지 않은 경우 effective automation rate는 automationRate의
값입니다.
DistanceModelType
열거형은 오디오 소스가 리스너로부터 멀어질 때 볼륨 감쇠에 사용할 알고리즘을 결정합니다. 기본값은 "inverse"입니다.
각 거리 모델 설명에서, \(d\)는 리스너와 패너 사이의 거리, \(d_{ref}\)는 refDistance
속성 값,
\(d_{max}\)는 maxDistance
속성 값,
\(f\)는 rolloffFactor
속성 값입니다.
enum {DistanceModelType "linear" ,"inverse" ,"exponential" };
| 열거값 | 설명 |
|---|---|
"linear"
|
선형 거리 모델로, distanceGain을 다음과 같이 계산합니다:
$$
1 - f\ \frac{\max\left[\min\left(d, d’_{max}\right), d’_{ref}\right] - d’_{ref}}{d’_{max} - d’_{ref}}
$$
여기서 \(d’_{ref} = \min\left(d_{ref}, d_{max}\right)\), \(d’_{max} = \max\left(d_{ref}, d_{max}\right)\)입니다. \(d’_{ref} = d’_{max}\)인 경우 선형 모델의 값은 \(1-f\)로 합니다. \(d\)는 구간 \(\left[d’_{ref},\, d’_{max}\right]\)으로 클램핑됩니다. |
"inverse"
|
역수 거리 모델로, distanceGain을 다음과 같이 계산합니다:
$$
\frac{d_{ref}}{d_{ref} + f\ \left[\max\left(d, d_{ref}\right) - d_{ref}\right]}
$$
즉, \(d\)는 구간 \(\left[d_{ref},\, \infty\right)\)으로 클램핑됩니다. \(d_{ref} = 0\)이면 역수 모델의 값은 \(d, f\)와 무관하게 0입니다. |
"exponential"
|
지수 거리 모델로, distanceGain을 다음과 같이 계산합니다:
$$
\left[\frac{\max\left(d, d_{ref}\right)}{d_{ref}}\right]^{-f}
$$
즉, \(d\)는 구간 \(\left[d_{ref},\, \infty\right)\)으로 클램핑됩니다. \(d_{ref} = 0\)이면 지수 모델의 값은 \(d, f\)와 무관하게 0입니다. |
[Exposed =Window ]interface PannerNode :AudioNode {constructor (BaseAudioContext ,context optional PannerOptions = {});options attribute PanningModelType panningModel ;readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam orientationX ;readonly attribute AudioParam orientationY ;readonly attribute AudioParam orientationZ ;attribute DistanceModelType distanceModel ;attribute double refDistance ;attribute double maxDistance ;attribute double rolloffFactor ;attribute double coneInnerAngle ;attribute double coneOuterAngle ;attribute double coneOuterGain ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ); };z
1.27.1. 생성자
PannerNode(context, options)-
이 생성자는
BaseAudioContextc와 옵션 객체 option으로 호출될 때, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.PannerNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 PannerNode가 연결될BaseAudioContext입니다.optionsPannerOptions✘ ✔ 이 PannerNode의 초기 파라미터 값(선택 사항).
1.27.2. 속성
coneInnerAngle, 타입 double-
방향성 오디오 소스용 파라미터로, 이 각도(도 단위) 이내에서는 볼륨 감소가 없습니다. 기본값은 360입니다. 각도가 [0, 360] 범위를 벗어나면 동작은 정의되지 않습니다.
coneOuterAngle, 타입 double-
방향성 오디오 소스용 파라미터로, 이 각도(도 단위) 외부에서는 볼륨이
coneOuterGain값으로 감소합니다. 기본값은 360입니다. 각도가 [0, 360] 범위를 벗어나면 동작은 정의되지 않습니다. coneOuterGain, 타입 double-
방향성 오디오 소스용 파라미터로,
coneOuterAngle외부의 게인 값입니다. 기본값은 0입니다. [0, 1] 범위의 선형 값(데시벨 아님)입니다. 이 값이 범위를 벗어나면InvalidStateError가 반드시 발생해야 합니다. distanceModel, 타입 DistanceModelType-
이
PannerNode에서 사용하는 거리 모델을 지정합니다. 기본값은 "inverse"입니다. maxDistance, 타입 double-
소스와 리스너 사이의 최대 거리입니다. 이 거리를 넘어서면 볼륨이 더 이상 감소하지 않습니다. 기본값은 10000입니다.
RangeError가 반드시 발생해야 하며, 0 이하로 설정할 수 없습니다. orientationX, 타입 AudioParam, 읽기 전용-
오디오 소스가 3D 카르테시안 좌표계에서 향하는 방향의 \(x\) 성분을 나타냅니다.
파라미터 값 비고 defaultValue1 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 orientationY, 타입 AudioParam, 읽기 전용-
오디오 소스가 3D 카르테시안 좌표계에서 향하는 방향의 \(y\) 성분을 나타냅니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 orientationZ, 타입 AudioParam, 읽기 전용-
오디오 소스가 3D 카르테시안 좌표계에서 향하는 방향의 \(z\) 성분을 나타냅니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 panningModel, 타입 PanningModelType-
이
PannerNode에서 사용하는 패닝 모델을 지정합니다. 기본값은 "equalpower"입니다. positionX, 타입 AudioParam, 읽기 전용-
오디오 소스의 3D 카르테시안 좌표계 \(x\) 위치를 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 positionY, 타입 AudioParam, 읽기 전용-
오디오 소스의 3D 카르테시안 좌표계 \(y\) 위치를 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 positionZ, 타입 AudioParam, 읽기 전용-
오디오 소스의 3D 카르테시안 좌표계 \(z\) 위치를 설정합니다.
파라미터 값 비고 defaultValue0 minValue최소 단정도 float 약 -3.4028235e38 maxValue최대 단정도 float 약 3.4028235e38 automationRate" a-rate"자동화 속도 제약 있음 refDistance, 타입 double-
볼륨 감소 기준 거리입니다. 이 거리보다 가까우면 볼륨이 감소하지 않습니다. 기본값은 1입니다.
RangeError가 반드시 발생해야 하며, 음수로 설정할 수 없습니다. rolloffFactor, 타입 double-
소스가 리스너에게서 멀어질 때 볼륨이 얼마나 빨리 감소할지 나타냅니다. 기본값은 1입니다.
RangeError가 반드시 발생해야 하며, 음수로 설정할 수 없습니다.rolloffFactor의 공칭 범위는rolloffFactor가 가질 수 있는 최소/최대값을 지정합니다. 범위를 벗어난 값은 자동으로 범위 내로 클램핑됩니다. 공칭 범위는distanceModel에 따라 다릅니다:- "
linear" -
공칭 범위는 \([0, 1]\)입니다.
- "
inverse" -
공칭 범위는 \([0, \infty)\)입니다.
- "
exponential" -
공칭 범위는 \([0, \infty)\)입니다.
클램핑은 거리 계산 처리 과정에서 이루어집니다. 속성 값 자체는 설정된 값을 그대로 반영하며, 수정되지 않습니다.
- "
1.27.3. 메서드
setOrientation(x, y, z)-
이 메서드는 더 이상 사용되지 않습니다(DEPRECATED).
orientationX.value,orientationY.value,orientationZ.value속성에 각각x,y,z파라미터 값을 직접 설정하는 것과 동일합니다.따라서
orientationX,orientationY,orientationZAudioParam에 대해setValueCurveAtTime()로 자동화 곡선이 설정되어 있을 때 이 메서드를 호출하면NotSupportedError가 반드시 발생해야 합니다.오디오 소스가 3D 카르테시안 좌표계에서 어느 방향을 향하는지 설명합니다. cone 속성으로 조절되는 방향성에 따라 리스너와 반대 방향을 향하면 소리가 매우 작거나 완전히 무음이 될 수 있습니다.
x, y, z파라미터는 3D 공간에서 방향 벡터를 나타냅니다.기본값은 (1,0,0)입니다.
PannerNode.setOrientation() 메서드 인자. 파라미터 타입 Nullable Optional 설명 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 반환 타입:undefined setPosition(x, y, z)-
이 메서드는 더 이상 사용되지 않습니다(DEPRECATED).
positionX.value,positionY.value,positionZ.value속성에 각각x,y,z파라미터 값을 직접 설정하는 것과 동일합니다.따라서
positionX,positionY,positionZAudioParam에 대해setValueCurveAtTime()로 자동화 곡선이 설정되어 있을 때 이 메서드를 호출하면NotSupportedError가 반드시 발생해야 합니다.오디오 소스의 위치를
listener속성 기준으로 설정합니다. 3D 카르테시안 좌표계를 사용합니다.x, y, z파라미터는 3D 공간에서 좌표를 나타냅니다.기본값은 (0,0,0)입니다.
PannerNode.setPosition() 메서드 인자. 파라미터 타입 Nullable Optional 설명 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 반환 타입:undefined
1.27.4. PannerOptions
이 객체는 PannerNode
생성 시 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며, 지정하지 않으면 생성 시 기본값이 사용됩니다.
dictionary PannerOptions :AudioNodeOptions {PanningModelType panningModel = "equalpower";DistanceModelType distanceModel = "inverse";float positionX = 0;float positionY = 0;float positionZ = 0;float orientationX = 1;float orientationY = 0;float orientationZ = 0;double refDistance = 1;double maxDistance = 10000;double rolloffFactor = 1;double coneInnerAngle = 360;double coneOuterAngle = 360;double coneOuterGain = 0; };
1.27.4.1. 딕셔너리 PannerOptions
멤버
coneInnerAngle, 타입 double, 기본값360-
노드의
coneInnerAngle속성의 초기값입니다. coneOuterAngle, 타입 double, 기본값360-
노드의
coneOuterAngle속성의 초기값입니다. coneOuterGain, 타입 double, 기본값0-
노드의
coneOuterGain속성의 초기값입니다. distanceModel, 타입 DistanceModelType, 기본값"inverse"-
노드에서 사용할 거리 모델입니다.
maxDistance, 타입 double, 기본값10000-
노드의
maxDistance속성의 초기값입니다. orientationX, 타입 float, 기본값1-
orientationXAudioParam의 초기 \(x\) 성분 값입니다. orientationY, 타입 float, 기본값0-
orientationYAudioParam의 초기 \(y\) 성분 값입니다. orientationZ, 타입 float, 기본값0-
orientationZAudioParam의 초기 \(z\) 성분 값입니다. panningModel, 타입 PanningModelType, 기본값"equalpower"-
노드에서 사용할 패닝 모델입니다.
positionX, 타입 float, 기본값0-
positionXAudioParam의 초기 \(x\) 좌표 값입니다. positionY, 타입 float, 기본값0-
positionYAudioParam의 초기 \(y\) 좌표 값입니다. positionZ, 타입 float, 기본값0-
positionZAudioParam의 초기 \(z\) 좌표 값입니다. refDistance, 타입 double, 기본값1-
노드의
refDistance속성의 초기값입니다. rolloffFactor, 타입 double, 기본값1-
노드의
rolloffFactor속성의 초기값입니다.
1.27.5. 채널 제한
StereoPannerNode
에 대한 채널 제한 집합은
PannerNode
에도 적용됩니다.
1.28. PeriodicWave
인터페이스
PeriodicWave
는 OscillatorNode
와 함께 사용할 임의의 주기파형을 나타냅니다.
호환 구현은 PeriodicWave
를 최소 8192 요소까지 지원해야 합니다.
[Exposed =Window ]interface PeriodicWave {constructor (BaseAudioContext ,context optional PeriodicWaveOptions = {}); };options
1.28.1. 생성자
PeriodicWave(context, options)-
-
p를 새로운
PeriodicWave객체로 지정한다.[[real]]과[[imag]]을Float32Array타입의 내부 슬롯으로 지정하고,[[normalize]]도 내부 슬롯으로 지정한다. -
options를 다음 경우 중 하나에 따라 처리한다:-
options.real과options.imag모두 존재할 경우-
options.real과options.imag의 길이가 다르거나, 둘 중 하나라도 길이가 2 미만이면IndexSizeError를 발생시키고 알고리즘을 중단한다. -
[[real]]과[[imag]]를options.real과 같은 길이의 새 배열로 설정한다. -
options.real의 모든 요소를[[real]]에 복사하고,options.imag의 모든 요소를[[imag]]에 복사한다.
-
-
options.real만 존재할 경우-
options.real길이가 2 미만이면IndexSizeError를 발생시키고 알고리즘을 중단한다. -
[[real]]과[[imag]]를options.real과 같은 길이의 배열로 설정한다. -
options.real을[[real]]에 복사하고,[[imag]]는 모두 0으로 설정한다.
-
-
options.imag만 존재할 경우-
options.imag길이가 2 미만이면IndexSizeError를 발생시키고 알고리즘을 중단한다. -
[[real]]과[[imag]]를options.imag과 같은 길이의 배열로 설정한다. -
options.imag을[[imag]]에 복사하고,[[real]]은 모두 0으로 설정한다.
-
-
그 외의 경우
참고: 이
PeriodicWave를OscillatorNode에 설정하면, 내장 타입 "sine"을 사용하는 것과 같습니다.
-
-
[[normalize]]를PeriodicWaveConstraints의disableNormalization속성의 반값으로 초기화한다. (즉, disableNormalization이 false면 normalize는 true) -
p를 반환한다.
PeriodicWave.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 PeriodicWave가 연결될BaseAudioContext입니다.AudioBuffer와 달리,PeriodicWave는AudioContext나OfflineAudioContext간에 공유할 수 없습니다. 특정BaseAudioContext에 연결됩니다.optionsPeriodicWaveOptions✘ ✔ 이 PeriodicWave의 초기 파라미터 값(선택 사항). -
1.28.2. PeriodicWaveConstraints
PeriodicWaveConstraints
딕셔너리는 파형이 정규화되는 방식을 지정하는 데 사용됩니다.
dictionary PeriodicWaveConstraints {boolean disableNormalization =false ; };
1.28.2.1. 딕셔너리 PeriodicWaveConstraints
멤버
disableNormalization, 타입 boolean, 기본값false-
주기파가 정규화될지 여부를 제어합니다.
true면 정규화하지 않고,false면 정규화합니다.
1.28.3. PeriodicWaveOptions
PeriodicWaveOptions
딕셔너리는 파형이 어떻게 생성될지 지정합니다. real
또는 imag
중 하나만 지정하면, 다른 하나는 동일 길이의 0 배열로 처리됩니다(아래 딕셔너리 멤버 설명
참고).
둘 다 없으면 PeriodicWave
는 OscillatorNode의
type이
"sine"일
때와 동등하게 생성됩니다.
둘 다 지정하면 시퀀스 길이가 같아야 하며, 아니면 NotSupportedError
오류를 반드시 발생시켜야 합니다.
dictionary PeriodicWaveOptions :PeriodicWaveConstraints {sequence <float >real ;sequence <float >imag ; };
1.28.3.1. 딕셔너리 PeriodicWaveOptions
멤버
imag, 타입 sequence<float>-
imag파라미터는sine항 배열을 나타냅니다. 첫 번째 요소(인덱스 0)는 푸리에 급수에 존재하지 않습니다. 두 번째 요소(인덱스 1)는 기본 주파수, 세 번째는 첫 번째 배음 등입니다. real, 타입 sequence<float>-
real파라미터는cosine항 배열을 나타냅니다. 첫 번째 요소(인덱스 0)는 주기파의 DC 오프셋입니다. 두 번째 요소(인덱스 1)는 기본 주파수, 세 번째는 첫 번째 배음 등입니다.
1.28.4. 파형 생성
createPeriodicWave()
메서드는 PeriodicWave의
푸리에 계수를 명시하기 위해 두 배열을 받습니다.
\(a\)와 \(b\)를 각각 길이 \(L\)의 [[real]]과
[[imag]]
배열이라 할 때,
기본 시간영역 파형 \(x(t)\)는 다음과 같이 계산할 수 있습니다:
$$
x(t) = \sum_{k=1}^{L-1} \left[a[k]\cos2\pi k t + b[k]\sin2\pi k t\right]
$$
이것이 기본(정규화되지 않은) 파형입니다.
1.28.5. 파형 정규화
이 PeriodicWave의
내부 슬롯 [[normalize]]가
true라면(기본값), 위에서 정의한 파형을 최대값이 1이 되도록 정규화합니다. 정규화는 다음과 같이 수행됩니다.
다음과 같이 정의합니다:
$$
\tilde{x}(n) = \sum_{k=1}^{L-1} \left(a[k]\cos\frac{2\pi k n}{N} + b[k]\sin\frac{2\pi k n}{N}\right)
$$
여기서 \(N\)은 2의 거듭제곱입니다. (\(\tilde{x}(n)\)은 역 FFT로 쉽게 계산할 수 있습니다.) 고정 정규화 인자 \(f\)는 다음과 같이 계산됩니다.
$$
f = \max_{n = 0, \ldots, N - 1} |\tilde{x}(n)|
$$
따라서 실제 정규화된 파형 \(\hat{x}(n)\)은 다음과 같습니다:
$$
\hat{x}(n) = \frac{\tilde{x}(n)}{f}
$$
이 고정 정규화 인자는 모든 생성된 파형에 반드시 적용되어야 합니다.
1.28.6. 오실레이터 계수
내장 오실레이터 타입은 PeriodicWave
객체를 사용하여 생성됩니다. 참고로 각 내장 오실레이터 타입에 대한 PeriodicWave의
계수를 아래에 제공합니다. 내장 타입을 사용하되 기본 정규화를 원하지 않을 때 유용합니다.
이하 설명에서, \(a\)는 실수 계수 배열, \(b\)는 허수 계수 배열입니다. 모든 경우에 대해 \(a[n] = 0\) (파형이 홀수 함수임), \(b[0] = 0\)입니다. \(n \ge 1\)에 대해 \(b[n]\)만 아래에 명시합니다.
- "
sine" -
$$ b[n] = \begin{cases} 1 & \mbox{if } n = 1 \\ 0 & \mbox{otherwise} \end{cases} $$ - "
square" -
$$ b[n] = \frac{2}{n\pi}\left[1 - (-1)^n\right] $$ - "
sawtooth" -
$$ b[n] = (-1)^{n+1} \dfrac{2}{n\pi} $$ - "
triangle" -
$$ b[n] = \frac{8\sin\dfrac{n\pi}{2}}{(\pi n)^2} $$
1.29. ScriptProcessorNode
인터페이스 - 사용 중단됨(DEPRECATED)
이 인터페이스는 AudioNode
이며
스크립트를 통해 오디오를 직접 생성, 처리, 분석할 수 있습니다. 이 노드 타입은 사용 중단되었으며, AudioWorkletNode로
대체될 예정입니다.
이 텍스트는 구현에서 이 노드 타입을 제거하기 전까지 정보 제공용으로 남아 있습니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfInputChannels
| 이 값은 노드를 생성할 때 지정한 채널 수입니다. channelCount 제약이 있습니다. |
channelCountMode
| "explicit"
| channelCountMode 제약이 있습니다. |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
ScriptProcessorNode
는 bufferSize와
함께 생성되며, 다음 값 중 하나여야 합니다: 256,
512, 1024, 2048, 4096, 8192, 16384. 이 값은 audioprocess
이벤트가 얼마나 자주 발생하는지와
호출마다 처리해야 할 샘플 프레임 수를 결정합니다. audioprocess
이벤트는 ScriptProcessorNode
에 입력 또는 출력이 하나 이상 연결되어 있을 때만 발생합니다. bufferSize가
작을수록 지연시간이 낮아집니다(더 좋음).
값이 클수록 오디오 끊김 및 글리치를 방지하는 데 필요합니다. 이 값은 createScriptProcessor()
에 bufferSize 인자를 전달하지 않거나 0으로 설정하면 구현에서 선택합니다.
numberOfInputChannels
와 numberOfOutputChannels
는 입력/출력 채널 수를 결정합니다. 두 값 모두 0이면 유효하지 않습니다.
[Exposed =Window ]interface ScriptProcessorNode :AudioNode {attribute EventHandler onaudioprocess ;readonly attribute long bufferSize ; };
1.29.1. 속성
bufferSize, 타입 long, 읽기 전용-
audioprocess가 발생할 때마다 처리해야 할 버퍼 크기(샘플 프레임 단위)입니다. 허용 값은 (256, 512, 1024, 2048, 4096, 8192, 16384)입니다. onaudioprocess, 타입 EventHandler-
audioprocess이벤트 타입에 대한 이벤트 핸들러를 설정하는 데 사용되는 속성입니다. 이 이벤트는ScriptProcessorNode노드에 디스패치됩니다. 이벤트 핸들러에 전달되는 이벤트는AudioProcessingEvent인터페이스를 사용합니다.
1.30.
StereoPannerNode
인터페이스
이 인터페이스는 저비용 패닝 알고리즘을 사용하여 들어오는 오디오 스트림을 스테레오 이미지에서 위치시키는 처리 노드를 나타냅니다. 이 패닝 효과는 스테레오 스트림에서 오디오 구성 요소를 위치시킬 때 일반적으로 사용됩니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | channelCount 제약 있음 |
channelCountMode
| "clamped-max"
| channelCountMode 제약 있음 |
channelInterpretation
| "speakers"
| |
| tail-time | 없음 |
이 노드의 입력은 스테레오(2채널)이며, 채널 수를 늘릴 수 없습니다. 채널 수가 더 적거나 많은 노드에서 연결될 경우 적절히 업믹스 또는 다운믹스됩니다.
이 노드의 출력은 하드코딩된 스테레오(2채널)이며, 구성할 수 없습니다.
[Exposed =Window ]interface StereoPannerNode :AudioNode {constructor (BaseAudioContext ,context optional StereoPannerOptions = {});options readonly attribute AudioParam pan ; };
1.30.1. 생성자
StereoPannerNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.StereoPannerNode.constructor() 메서드 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 StereoPannerNode가 연결될BaseAudioContext입니다.optionsStereoPannerOptions✘ ✔ 이 StereoPannerNode의 초기 파라미터 값(선택 사항).
1.30.2. 속성
pan, 타입 AudioParam, 읽기 전용-
입력이 출력의 스테레오 이미지에서 어느 위치에 있는지 나타냅니다. -1은 완전히 왼쪽, +1은 완전히 오른쪽을 의미합니다.
파라미터 값 비고 defaultValue0 minValue-1 maxValue1 automationRate" a-rate"
1.30.3. StereoPannerOptions
이 객체는 StereoPannerNode
생성 시 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며, 지정하지 않으면 생성 시 기본값이 사용됩니다.
dictionary StereoPannerOptions :AudioNodeOptions {float pan = 0; };
1.30.3.1. 딕셔너리 StereoPannerOptions
멤버
pan, 타입 float, 기본값0-
panAudioParam의 초기값입니다.
1.30.4. 채널 제한
위 정의에 따라 처리 방식이 제한되므로, StereoPannerNode
는 오디오를 최대 2채널만 믹스할 수 있으며, 정확히 2채널을 출력합니다. ChannelSplitterNode,
중간 처리용 GainNode 또는 기타
노드, ChannelMergerNode를
활용해 임의의 패닝/믹싱을 구현할 수 있습니다.
1.31. WaveShaperNode
인터페이스
WaveShaperNode
는 AudioNode
프로세서로서 비선형 디스토션 효과를 구현합니다.
비선형 waveshaping 디스토션은 미묘한 비선형 워밍 효과부터 뚜렷한 디스토션 효과까지 다양하게 사용됩니다. 임의의 비선형 셰이핑 커브를 지정할 수 있습니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | Maybe | oversample
속성이 "2x"
또는 "4x"일
때만 tail-time이 있습니다.
실제 tail-time 지속시간은 구현에 따라 다릅니다.
|
출력 채널 수는 항상 입력 채널 수와 같습니다.
enum {OverSampleType "none" ,"2x" ,"4x" };
| 열거값 | 설명 |
|---|---|
"none"
| 오버샘플링 없음 |
"2x"
| 두 배로 오버샘플링 |
"4x"
| 네 배로 오버샘플링 |
[Exposed =Window ]interface WaveShaperNode :AudioNode {constructor (BaseAudioContext ,context optional WaveShaperOptions = {});options attribute Float32Array ?curve ;attribute OverSampleType oversample ; };
1.31.1. 생성자
WaveShaperNode(context, options)-
생성자가
BaseAudioContextc와 옵션 객체 option으로 호출되면, UA는 context와 options를 인자로 하여 AudioNode를 초기화해야 합니다.또한
[[curve set]]을 이WaveShaperNode의 내부 슬롯으로 지정합니다. 이 슬롯을false로 초기화합니다.options가 주어지고curve가 지정되어 있으면[[curve set]]을true로 설정합니다.WaveShaperNode.constructor() 메서드 인자 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 WaveShaperNode가 연결될BaseAudioContext입니다.optionsWaveShaperOptions✘ ✔ 이 WaveShaperNode의 초기 파라미터 값(선택 사항).
1.31.2. 속성
curve, 타입 Float32Array, nullable-
waveshaping 효과에 사용되는 셰이핑 커브입니다. 입력 신호는 명목상 [-1, 1] 범위 내에 있습니다. 이 범위 내의 각 입력 샘플은 셰이핑 커브에 인덱싱되며, 신호 레벨 0은 커브 배열 길이가 홀수일 때 중앙 값에, 짝수일 때는 중앙 두 값 사이 보간 값에 해당합니다. -1보다 작은 값은 커브 배열의 첫 번째 값에, +1보다 큰 값은 마지막 값에 대응됩니다.
구현체는 커브의 인접 포인트 사이를 반드시 선형 보간해야 합니다. 초기에 curve 속성은 null로, 이 경우 WaveShaperNode는 입력을 그대로 출력합니다.
커브 값들은 [-1; 1] 범위에 동일한 간격으로 분포합니다. 즉, 커브 값이 짝수 개면 신호 0에 해당하는 값이 없고, 홀수 개면 신호 0에 해당하는 값이 있습니다. 출력은 다음 알고리즘에 따라 결정됩니다.
-
입력 샘플을 \(x\), 대응 출력값을 \(y\),
curve의 \(k\)번째 요소를 \(c_k\),curve의 길이를 \(N\)이라 한다. -
다음과 같이 계산한다:
$$ \begin{align*} v &= \frac{N-1}{2}(x + 1) \\ k &= \lfloor v \rfloor \\ f &= v - k \end{align*} $$ -
그리고:
$$ \begin{align*} y &= \begin{cases} c_0 & v \lt 0 \\ c_{N-1} & v \ge N - 1 \\ (1-f)\,c_k + fc_{k+1} & \mathrm{otherwise} \end{cases} \end{align*} $$
이 속성에
Float32Array를 길이 2 미만으로 설정하면InvalidStateError를 반드시 발생시켜야 합니다.이 속성을 설정하면 WaveShaperNode에서 커브의 내부 복사본을 생성합니다. 이후 해당 배열의 내용 변경은 효과가 없습니다.
curve 속성을 설정하는 단계:-
new curve를
Float32Array또는null로 지정한다. -
new curve가
null이 아니고,[[curve set]]이 true면InvalidStateError를 발생시키고 중단한다. -
new curve가
null이 아니면[[curve set]]을 true로 설정한다. -
new curve를
curve속성에 할당한다.
참고: 입력값이 0일 때 출력값이 0이 아닌 커브를 사용할 경우, 입력이 연결되어 있지 않아도 이 노드는 DC 신호를 출력합니다. 이는 노드가 다운스트림 노드에서 분리될 때까지 지속됩니다.
-
oversample, 타입 OverSampleType-
셰이핑 커브를 적용할 때 사용할 오버샘플링 유형을 지정합니다. 기본값은 "
none"로, 커브가 입력 샘플에 직접 적용됩니다. "2x" 또는 "4x"를 사용하면 일부 에일리어싱 방지로 품질이 향상될 수 있으며, "4x"가 가장 높은 품질입니다. 일부 용도에선 오버샘플링 없이 더 정밀한 셰이핑 커브 얻는 것이 좋습니다."2x" 또는 "4x"를 지정하면 다음 단계가 반드시 수행되어야 합니다:-
입력 샘플을
AudioContext샘플레이트의 2배 또는 4배로 업샘플링합니다. 즉, 각 렌더 퀀텀마다 두 배(2x) 또는 네 배(4x) 샘플을 생성합니다. -
셰이핑 커브를 적용합니다.
-
결과를
AudioContext샘플레이트로 다운샘플링합니다. 즉, 이전 처리된 샘플을 기준으로 최종 렌더 퀀텀 샘플만큼 생성합니다.
업샘플링/다운샘플링 필터의 구체적 방식은 명시되지 않으며, 음질(에일리어싱 최소화), 저지연, 성능 등을 고려해 조정될 수 있습니다.
참고: 오버샘플링을 사용하면 업샘플링/다운샘플링 필터로 인해 오디오 처리 지연시간이 증가할 수 있습니다. 이 지연량은 구현에 따라 다를 수 있습니다.
-
1.31.3.
WaveShaperOptions
이 객체는 WaveShaperNode
생성 시 사용할 옵션을 지정합니다.
모든 멤버는 선택 사항이며, 지정하지 않으면 생성 시 기본값이 사용됩니다.
dictionary WaveShaperOptions :AudioNodeOptions {sequence <float >curve ;OverSampleType oversample = "none"; };
1.31.3.1. 딕셔너리 WaveShaperOptions
멤버
curve, 타입 sequence<float>-
waveshaping 효과용 셰이핑 커브입니다.
oversample, 타입 OverSampleType, 기본값"none"-
셰이핑 커브에 사용할 오버샘플링 유형입니다.
1.32. AudioWorklet
인터페이스
[Exposed =Window ,SecureContext ]interface AudioWorklet :Worklet {readonly attribute MessagePort port ; };
1.32.1. 속성
port, 타입 MessagePort, 읽기 전용-
MessagePort가AudioWorkletGlobalScope의 포트에 연결되어 있습니다.참고: 이
port의"message"이벤트에 이벤트 리스너를 등록하는 저자는close를MessageChannel의 어느 쪽(즉,AudioWorklet또는AudioWorkletGlobalScope측)에서든 호출해야 리소스가 수집될 수 있습니다.
1.32.2. 개념
AudioWorklet
객체는 개발자가 렌더링 스레드에서 오디오를
처리할 수 있도록 스크립트(예: JavaScript 또는 WebAssembly 코드)를 제공하며, 커스텀 AudioNode를
지원합니다. 이 처리 메커니즘은 오디오 그래프 내의 다른 내장 AudioNode들과
스크립트 코드가 동기적으로 실행되도록 보장합니다.
이 메커니즘을 구현하기 위해 반드시 두 개의 연관된 객체가 정의되어야 합니다: AudioWorkletNode와
AudioWorkletProcessor.
전자는 메인 글로벌 스코프에서 다른 AudioNode
객체들과 유사한 인터페이스를 제공하며, 후자는 AudioWorkletGlobalScope라는
특수 스코프 내에서 내부 오디오 처리를 구현합니다.

AudioWorkletNode
및 AudioWorkletProcessor
각 BaseAudioContext는
정확히 하나의 AudioWorklet를
가집니다.
AudioWorklet의
워크릿 글로벌 스코프 타입은 AudioWorkletGlobalScope입니다.
AudioWorklet의
워크릿 대상 타입은 "audioworklet"입니다.
addModule(moduleUrl)
메서드를 통해 스크립트를 임포트하면 AudioWorkletProcessor
클래스 정의가 AudioWorkletGlobalScope
하에서 등록됩니다. 임포트된 클래스 생성자와 해당 생성자로부터 생성된 활성 인스턴스를 위한 두 개의 내부 저장소가 있습니다.
AudioWorklet는
하나의 내부 슬롯을 가집니다:
-
노드 이름에서 파라미터 디스크립터 맵은 노드 이름에서 프로세서 생성자 맵의 문자열 키와 동일한 집합을 포함하는 맵으로, 해당 parameterDescriptors 값과 연결됩니다. 이 내부 저장소는
registerProcessor()메서드를 렌더링 스레드에서 호출한 결과로 채워지며, 해당 컨텍스트의addModule()가 반환한 프로미스가 resolve되기 전에 반드시 완전히 채워집니다.
// bypass-processor.js 스크립트 파일, AudioWorkletGlobalScope에서 실행됨 class BypassProcessorextends AudioWorkletProcessor{ process( inputs, outputs) { // 단일 입력, 단일 채널. const input= inputs[ 0 ]; const output= outputs[ 0 ]; output[ 0 ]. set( input[ 0 ]); // 활성 입력이 있을 때만 처리합니다. return false ; } }; registerProcessor( 'bypass-processor' , BypassProcessor);
// 메인 글로벌 스코프 const context= new AudioContext(); context. audioWorklet. addModule( 'bypass-processor.js' ). then(() => { const bypassNode= new AudioWorkletNode( context, 'bypass-processor' ); });
메인 글로벌 스코프에서 AudioWorkletNode
인스턴스가 생성될 때, 대응되는 AudioWorkletProcessor도
AudioWorkletGlobalScope에서
생성됩니다. 이 두 객체는 § 2 처리 모델에서 설명된 비동기 메시지 전달 방식으로 통신합니다.
1.32.3. AudioWorkletGlobalScope
인터페이스
이 특수 실행 컨텍스트는 오디오 렌더링
스레드에서 직접 스크립트를 이용하여 오디오 데이터를 생성, 처리 및 분석할 수 있도록 설계되었습니다. 사용자가 제공한 스크립트 코드는 이 스코프에서 평가되어 하나 이상의 AudioWorkletProcessor
서브클래스를 정의하며, 이는 AudioWorkletNode와
1:1로 연결되어 인스턴스화됩니다.
각 AudioContext마다
하나의 AudioWorkletGlobalScope가
존재하며, AudioWorkletNode가
하나 이상 포함될 수 있습니다. 임포트된 스크립트의 실행은 [HTML]에 정의된 대로 UA에 의해 수행됩니다. [HTML]에서 지정된 기본 동작을 오버라이드하여, AudioWorkletGlobalScope는
사용자 에이전트에 의해 임의로 종료되어서는 안 됩니다.
AudioWorkletGlobalScope는
다음과 같은 내부 슬롯을 가집니다:
-
노드 이름에서 프로세서 생성자 맵은 프로세서 이름 →
AudioWorkletProcessorConstructor인스턴스의 키-값 쌍을 저장하는 맵입니다. 초기에는 이 맵이 비어 있으며registerProcessor()메서드가 호출될 때 채워집니다. -
대기 중인 프로세서 생성 데이터는
AudioWorkletNode생성자가 대응되는AudioWorkletProcessor인스턴스를 만들기 위해 생성한 임시 데이터를 저장합니다. 대기 중인 프로세서 생성 데이터에는 다음 항목이 포함됩니다:-
노드 참조는 초기에는 비어 있습니다. 이 저장소는
AudioWorkletNode생성자에서 전달된AudioWorkletNode참조를 위한 공간입니다. -
전송된 포트는 초기에는 비어 있습니다. 이 저장소는
MessagePort의 역직렬화된 값으로,AudioWorkletNode생성자에서 전달됩니다.
-
참고: AudioWorkletGlobalScope에는
인스턴스 간에 공유할 수 있는 데이터와 코드가 추가로 포함될 수 있습니다. 예를 들어, 여러 프로세서가 웨이브테이블 또는 임펄스 응답을 정의하는 ArrayBuffer를 공유할 수 있습니다.
참고: AudioWorkletGlobalScope는
하나의 BaseAudioContext
및 해당 컨텍스트의 하나의 오디오 렌더링 스레드와 연결됩니다. 이는 동시 스레드에서 실행되는 글로벌 스코프 코드의 데이터 레이스를 방지합니다.
callback =AudioWorkletProcessorConstructor AudioWorkletProcessor (object ); [options Global =(Worklet ,AudioWorklet ),Exposed =AudioWorklet ]interface AudioWorkletGlobalScope :WorkletGlobalScope {undefined registerProcessor (DOMString name ,AudioWorkletProcessorConstructor processorCtor );readonly attribute unsigned long long currentFrame ;readonly attribute double currentTime ;readonly attribute float sampleRate ;readonly attribute unsigned long renderQuantumSize ;readonly attribute MessagePort port ; };
1.32.3.1. 속성
currentFrame, 타입 unsigned long long, 읽기 전용-
현재 처리 중인 오디오 블록의 프레임입니다. 이 값은
[[current frame]]내부 슬롯과 동일해야 합니다. 해당BaseAudioContext의 값입니다. currentTime, 타입 double, 읽기 전용-
현재 처리 중인 오디오 블록의 컨텍스트 시간입니다. 정의상 컨트롤 스레드에서 가장 최근에 관측 가능한
BaseAudioContext의currentTime속성과 동일합니다. sampleRate, 타입 float, 읽기 전용-
연결된
BaseAudioContext의 샘플 레이트입니다. renderQuantumSize, 타입 unsigned long, 읽기 전용-
연결된
BaseAudioContext의 비공개 슬롯 [[render quantum size]]의 값입니다. port, 타입 MessagePort, 읽기 전용-
MessagePort가AudioWorklet의 포트에 연결되어 있습니다.참고: 이
port의"message"이벤트에 이벤트 리스너를 등록하는 저자는close를MessageChannel의 어느 쪽(즉,AudioWorklet또는AudioWorkletGlobalScope측)에서든 호출해야 리소스가 수집될 수 있습니다.
1.32.3.2. 메서드
registerProcessor(name, processorCtor)-
AudioWorkletProcessor에서 파생된 클래스 생성자를 등록합니다.registerProcessor(name, processorCtor)메서드가 호출되면 다음 절차를 수행합니다. 어느 단계에서든 예외가 발생하면 남은 절차를 중단합니다.-
name이 빈 문자열이면
NotSupportedError를 발생시킵니다. -
name이 이미 node name to processor constructor map에 키로 존재하면
NotSupportedError를 발생시킵니다. -
IsConstructor(argument=processorCtor)결과가false이면TypeError를 발생시킵니다. -
prototype을Get(O=processorCtor, P="prototype")의 결과로 설정합니다. -
parameterDescriptorsValue를
Get(O=processorCtor, P="parameterDescriptors")의 결과로 설정합니다. -
parameterDescriptorsValue가
undefined가 아니면 다음 절차를 실행합니다:-
parameterDescriptorSequence를 변환 결과로 parameterDescriptorsValue를 IDL 타입
sequence<AudioParamDescriptor>로 변환합니다. -
paramNames를 빈 배열로 설정합니다.
-
parameterDescriptorSequence의 각 descriptor에 대해:
-
paramName을 descriptor의
name멤버의 값으로 설정합니다.NotSupportedError를 발생시킵니다. 만약 paramNames에 이미 paramName 값이 포함되어 있으면 -
paramName을 paramNames 배열에 추가합니다.
-
defaultValue를 descriptor의
defaultValue멤버의 값으로 설정합니다. -
minValue를 descriptor의
minValue멤버의 값으로 설정합니다. -
maxValue를 descriptor의
maxValue멤버의 값으로 설정합니다. -
만약 minValue <= defaultValue <= maxValue 식이 거짓이면
InvalidStateError를 발생시킵니다.
-
-
-
node name to processor constructor map에 name → processorCtor 키-값 쌍을 추가합니다. 해당
AudioWorkletGlobalScope에 추가합니다. -
미디어 요소 태스크를 큐에 추가하여 name → parameterDescriptorSequence 키-값 쌍을 node name to parameter descriptor map에 추가합니다. 해당
BaseAudioContext에 연결됩니다.
참고: 클래스 생성자는 한 번만 조회해야 하며, 등록 이후에는 동적으로 변경할 수 없습니다.
AudioWorkletGlobalScope.registerProcessor(name, processorCtor) 메서드의 인자. 파라미터 타입 Nullable Optional 설명 nameDOMString✘ ✘ 등록할 클래스 생성자를 나타내는 문자열 키입니다. 이 키는 AudioWorkletProcessor의 생성자를AudioWorkletNode생성 시 조회하는 데 사용됩니다.processorCtorAudioWorkletProcessorConstructor✘ ✘ AudioWorkletProcessor에서 확장된 클래스 생성자입니다.반환 타입:undefined -
1.32.3.3. AudioWorkletProcessor
인스턴스화
AudioWorkletNode
생성이 끝나면,
스레드 간 전송을 위해 struct인 프로세서 생성 데이터가 준비됩니다. 이 struct는 다음 항목을 포함합니다:
-
name은
DOMString이며, 노드 이름에서 프로세서 생성자 맵에서 조회됩니다. -
node는 생성된
AudioWorkletNode의 참조입니다. -
options는
AudioWorkletNodeOptions를 직렬화한 값으로,AudioWorkletNode의constructor에 전달됩니다. -
port는
MessagePort를 직렬화한 값이며,AudioWorkletNode의port에 연결됩니다.
전송된 데이터가 AudioWorkletGlobalScope에
도달하면,
렌더링 스레드가 아래 알고리즘을
실행합니다:
-
constructionData를 프로세서 생성 데이터로 설정합니다. 이 데이터는 컨트롤 스레드에서 전송됩니다.
-
processorName, nodeReference, serializedPort를 각각 constructionData의 name, node, port로 설정합니다.
-
serializedOptions를 constructionData의 options로 설정합니다.
-
deserializedPort를 StructuredDeserialize(serializedPort, 현재 Realm) 결과로 설정합니다.
-
deserializedOptions를 StructuredDeserialize(serializedOptions, 현재 Realm) 결과로 설정합니다.
-
processorCtor를
AudioWorkletGlobalScope의 노드 이름에서 프로세서 생성자 맵에서 processorName으로 조회한 값으로 설정합니다. -
nodeReference와 deserializedPort를 각각 이
AudioWorkletGlobalScope의 노드 참조와 전송된 포트에 저장합니다. -
콜백 함수 생성을 processorCtor로부터 deserializedOptions 인자를 사용하여 수행합니다. 콜백에서 예외가 발생하면, 태스크를 큐에 추가하여 컨트롤 스레드에서
processorerror이벤트를 nodeReference에ErrorEvent로 발생시킵니다. -
대기 중인 프로세서 생성 데이터 슬롯을 비웁니다.
1.32.4.
AudioWorkletNode
인터페이스
이 인터페이스는 컨트롤 스레드에서 동작하는 사용자
정의 AudioNode를
나타냅니다.
사용자는 BaseAudioContext에서
AudioWorkletNode를
생성할 수 있으며,
이러한 노드는 다른 내장 AudioNode들과
연결되어 오디오 그래프를 형성할 수 있습니다.
| 속성 | 값 | 비고 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 비고 참조 | tail-time은 노드 자체에서 처리됨 |
모든 AudioWorkletProcessor는
활성 소스(active source)
플래그를 가지며, 초기값은 true입니다. 이 플래그로 인해 입력이 연결되지 않은 경우에도 노드가 메모리에 유지되고 오디오 처리를 수행합니다.
모든 AudioWorkletNode에서
게시된 태스크는
해당 BaseAudioContext의
태스크 큐에 게시됩니다.
[Exposed =Window ]interface {AudioParamMap readonly maplike <DOMString ,AudioParam >; };
이 인터페이스는 readonly maplike로 인해 "entries", "forEach", "get", "has", "keys", "values", @@iterator
메서드 및 "size" getter를 가집니다.
[Exposed =Window ,SecureContext ]interface AudioWorkletNode :AudioNode {constructor (BaseAudioContext ,context DOMString ,name optional AudioWorkletNodeOptions = {});options readonly attribute AudioParamMap parameters ;readonly attribute MessagePort port ;attribute EventHandler onprocessorerror ; };
1.32.4.1. 생성자
AudioWorkletNode(context, name, options)-
AudioWorkletNode.constructor() 메서드의 인자. 파라미터 타입 Nullable Optional 설명 contextBaseAudioContext✘ ✘ 이 새로운 BaseAudioContext에AudioWorkletNode가 연결됩니다.nameDOMString✘ ✘ 이 문자열은 BaseAudioContext의 노드 이름에서 파라미터 디스크립터 맵의 키입니다.optionsAudioWorkletNodeOptions✘ ✔ 이 AudioWorkletNode의 선택적 초기 파라미터 값입니다.생성자가 호출되면, 사용자 에이전트는 컨트롤 스레드에서 다음 절차를 수행해야 합니다:
AudioWorkletNode생성자가 context, nodeName, options 인자로 호출되면:-
nodeName이
BaseAudioContext의 노드 이름에서 파라미터 디스크립터 맵에 키로 존재하지 않으면,InvalidStateError예외를 발생시키고 절차를 중단합니다. -
node를 this 값으로 설정합니다.
-
AudioNode를 초기화하여 node에 context와 options를 인자로 전달합니다.
-
입력, 출력 및 출력 채널 구성을 node에 options로 합니다. 예외가 발생하면 남은 절차를 중단합니다.
-
messageChannel을 새
MessageChannel로 설정합니다. -
nodePort를 messageChannel의
port1속성 값으로 설정합니다. -
processorPortOnThisSide를 messageChannel의
port2속성 값으로 설정합니다. -
serializedProcessorPort를 StructuredSerializeWithTransfer(processorPortOnThisSide, « processorPortOnThisSide ») 결과로 설정합니다.
-
Convert options 딕셔너리를 optionsObject로 변환합니다.
-
serializedOptions를 StructuredSerialize(optionsObject) 결과로 설정합니다.
-
node의
port를 nodePort로 설정합니다. -
parameterDescriptors를 nodeName을 노드 이름에서 파라미터 디스크립터 맵에서 조회한 결과로 설정합니다:
-
audioParamMap을 새
AudioParamMap객체로 설정합니다. -
parameterDescriptors의 각 descriptor에 대해:
-
paramName을 descriptor의
name멤버 값으로 설정합니다. -
audioParam을
AudioParam인스턴스로 생성하며automationRate,defaultValue,minValue,maxValue의 값은 descriptor의 해당 멤버 값과 동일하게 설정합니다. -
paramName → audioParam 키-값 쌍을 audioParamMap에 추가합니다.
-
-
parameterData가 options에 있으면, 다음 절차를 실행합니다:-
parameterData를
parameterData값으로 설정합니다. -
parameterData의 각 paramName → paramValue에 대해:
-
audioParamMap에 paramName 키가 있으면, audioParamInMap을 해당 항목으로 설정합니다.
-
audioParamInMap의
value속성을 paramValue로 설정합니다.
-
-
-
node의
parameters를 audioParamMap으로 설정합니다.
-
-
제어 메시지 큐에 추가(Queue a control message)하여 호출합니다. 해당
생성자(constructor)를 해당AudioWorkletProcessor에 nodeName, node, serializedOptions, serializedProcessorPort로 구성된 프로세서 생성 데이터(processor construction data)를 인자로 호출합니다.
-
1.32.4.2. 속성
onprocessorerror, 타입 EventHandler-
프로세서의
constructor,process메서드, 또는 사용자 정의 클래스 메서드에서 처리되지 않은 예외가 발생하면, 프로세서는 미디어 요소 태스크를 큐에 추가하여 processorerror라는 이벤트를processorerror이름으로 연결된AudioWorkletNode에서ErrorEvent를 사용하여 발생시킵니다.ErrorEvent는message,filename,lineno,colno속성값과 함께 컨트롤 스레드에서 적절히 생성 및 초기화됩니다.처리되지 않은 예외가 발생하면 프로세서는 평생 동안 무음 출력을 하게 됩니다.
parameters, 타입 AudioParamMap, 읽기 전용-
parameters속성은 이름과 연결된AudioParam객체의 컬렉션입니다. 이 maplike 객체는AudioWorkletProcessor클래스 생성자에서AudioParamDescriptor목록을 기반으로 인스턴스화 시점에 채워집니다. port, 타입 MessagePort, 읽기 전용-
모든
AudioWorkletNode에는port가 연결되어 있으며, 이는MessagePort입니다. 해당AudioWorkletProcessor객체의 포트에 연결되어AudioWorkletNode와AudioWorkletProcessor간의 양방향 통신이 가능합니다.참고: 이
port의"message"이벤트에 이벤트 리스너를 등록하는 저자는close를MessageChannel의 어느 쪽(즉,AudioWorkletProcessor또는AudioWorkletNode측)에서든 호출해야 리소스가 수집될 수 있습니다.
1.32.4.3. AudioWorkletNodeOptions
AudioWorkletNodeOptions
딕셔너리는 AudioWorkletNode
인스턴스의 속성을 초기화하는 데 사용할 수 있습니다.
dictionary AudioWorkletNodeOptions :AudioNodeOptions {unsigned long numberOfInputs = 1;unsigned long numberOfOutputs = 1;sequence <unsigned long >outputChannelCount ;record <DOMString ,double >parameterData ;object processorOptions ; };
1.32.4.3.1. Dictionary AudioWorkletNodeOptions
멤버
numberOfInputs, 타입 unsigned long, 기본값1-
이 값은
AudioNode의numberOfInputs속성을 초기화하는 데 사용됩니다. numberOfOutputs, 타입 unsigned long, 기본값1-
이 값은
AudioNode의numberOfOutputs속성을 초기화하는 데 사용됩니다. outputChannelCount, 타입sequence<unsigned long>-
이 배열은 각 출력의 채널 수를 설정하는 데 사용됩니다.
parameterData, 타입 record<DOMString, double>-
이 값은 사용자 정의 키-값 쌍 목록이며,
AudioWorkletNode내에서 이름이 일치하는AudioParam의 초기value를 설정하는 데 사용됩니다. processorOptions, 타입 object-
이 값은
AudioWorkletNode에 연결된AudioWorkletProcessor인스턴스에서 커스텀 속성을 초기화하는 데 사용할 수 있는 모든 사용자 정의 데이터를 포함합니다.
1.32.4.3.2. AudioWorkletNodeOptions로
채널 구성하기
아래 알고리즘은 AudioWorkletNodeOptions를
사용하여 다양한 채널 구성을 설정하는 방법을 설명합니다.
-
node를 이 알고리즘에 전달된
AudioWorkletNode인스턴스로 설정합니다. -
numberOfInputs와numberOfOutputs가 모두 0이면,NotSupportedError를 발생시키고 남은 절차를 중단합니다. -
outputChannelCount가 존재하면,-
outputChannelCount의 값 중 하나라도 0이거나 구현체의 최대 채널 수보다 크면,NotSupportedError를 발생시키고 남은 절차를 중단합니다. -
outputChannelCount의 길이가numberOfOutputs와 같지 않으면,IndexSizeError를 발생시키고 남은 절차를 중단합니다. -
numberOfInputs와numberOfOutputs가 모두 1이면, node의 출력 채널 수를outputChannelCount의 단일 값으로 설정합니다. -
그 외의 경우, node의 각 k번째 출력 채널 수를
outputChannelCount시퀀스의 k번째 요소로 설정하고 반환합니다.
-
-
-
numberOfInputs와numberOfOutputs가 모두 1이면, node의 출력 채널 수를 1로 설정하고 반환합니다.참고: 이 경우, 출력 채널 수는 런타임에서 입력과
channelCountMode에 따라 동적으로 computedNumberOfChannels로 변경됩니다. -
그 외의 경우, node의 각 출력 채널 수를 1로 설정하고 반환합니다.
-
1.32.5. AudioWorkletProcessor
인터페이스
이 인터페이스는 오디오 렌더링 스레드에서
실행되는 오디오 처리 코드를 나타냅니다.
AudioWorkletGlobalScope
내에서 동작하며, 클래스 정의가 실제 오디오 처리를 구현합니다.
AudioWorkletProcessor
인스턴스화는 AudioWorkletNode
생성에 의해서만 발생할 수 있습니다.
[Exposed =AudioWorklet ]interface AudioWorkletProcessor {constructor ();readonly attribute MessagePort port ; };callback AudioWorkletProcessCallback =boolean (FrozenArray <FrozenArray <Float32Array >>,inputs FrozenArray <FrozenArray <Float32Array >>,outputs object );parameters
AudioWorkletProcessor
는 두 개의 내부 슬롯을 가집니다:
[[node reference]]-
연결된
AudioWorkletNode의 참조입니다. [[callable process]]-
process()가 호출 가능한 유효한 함수인지를 나타내는 불리언 플래그입니다.
1.32.5.1. 생성자
AudioWorkletProcessor()-
AudioWorkletProcessor생성자가 호출되면, 렌더링 스레드에서 다음 절차가 수행됩니다.-
nodeReference를 현재
AudioWorkletGlobalScope의 노드 참조 슬롯에서 조회된 값으로 설정합니다. 슬롯이 비어 있으면TypeError예외를 발생시킵니다. -
processor를 this 값으로 설정합니다.
-
processor의
[[node reference]]를 nodeReference로 설정합니다. -
processor의
[[callable process]]를true로 설정합니다. -
deserializedPort를 전송된 포트 슬롯에서 조회된 값으로 설정합니다.
-
processor의
port를 deserializedPort로 설정합니다. -
대기 중인 프로세서 생성 데이터 슬롯을 비웁니다.
-
1.32.5.2. 속성
port, 타입 MessagePort, 읽기 전용-
모든
AudioWorkletProcessor에는port가 연결되어 있으며, 이는MessagePort입니다. 해당AudioWorkletNode객체의 포트에 연결되어AudioWorkletNode와AudioWorkletProcessor간의 양방향 통신이 가능합니다.참고: 이
port의"message"이벤트에 이벤트 리스너를 등록하는 저자는close를MessageChannel의 어느 쪽(즉,AudioWorkletProcessor또는AudioWorkletNode측)에서든 호출해야 리소스가 수집될 수 있습니다.
1.32.5.3. 콜백 AudioWorkletProcessCallback
사용자는 AudioWorkletProcessor를
확장하여 커스텀 오디오 프로세서를 정의할 수 있습니다.
서브클래스는 AudioWorkletProcessCallback인
process()
콜백을 반드시 정의해야 하며, 오디오 처리 알고리즘을 구현해야 합니다. 그리고
parameterDescriptors라는
정적 속성을 가질 수 있으며,
이는 AudioParamDescriptor의
반복자입니다.
process() 콜백 함수는 그래프 렌더링 시 지정된 대로 동작합니다.
AudioWorkletProcessor의
연결된 AudioWorkletNode의
생명주기를 제어합니다.
이 생명주기 정책은 내장 노드에서 볼 수 있는 다양한 접근 방식을 지원하며, 다음을 포함할 수 있습니다:
-
입력을 변환하고, 연결된 입력 또는 스크립트 참조가 존재할 때만 활성화되는 노드. 이런 노드는 process()에서
false를 반환해야 하며, 입력이 연결되어 있는지 여부에 따라AudioWorkletNode가 실제로 처리 중(active)인지 결정합니다. -
입력을 변환하지만, 입력이 끊어진 후에도 tail-time 동안 활성 상태를 유지하는 노드. 이 경우 process()는 입력(
inputs)의 채널 수가 0이 된 후 일정 시간 동안true를 반환해야 합니다. 현재 시간은 글로벌 스코프의currentTime에서 얻을 수 있으며, tail-time 구간의 시작과 끝을 측정하거나 프로세서의 내부 상태에 따라 동적으로 계산될 수 있습니다. -
출력 소스 역할을 하며, 일반적으로 수명이 존재하는 노드. 이런 노드는 process()에서 출력이 더 이상 생성되지 않을 때까지
true를 반환해야 합니다.
위 정의는 process() 구현에서 반환값이 없으면
false를 반환하는 것과 동일한 효과(즉, undefined라는
falsy 값)임을 의미합니다.
이는 활성 입력이 있을 때만 활성화되는 AudioWorkletProcessor에
합리적인 동작입니다.
아래 예시는 AudioParam을
AudioWorkletProcessor에서
정의하고 사용하는 방법을 보여줍니다.
class MyProcessorextends AudioWorkletProcessor{ static get parameterDescriptors() { return [{ name: 'myParam' , defaultValue: 0.5 , minValue: 0 , maxValue: 1 , automationRate: "k-rate" }]; } process( inputs, outputs, parameters) { // 첫 번째 입력과 출력을 가져옵니다. const input= inputs[ 0 ]; const output= outputs[ 0 ]; const myParam= parameters. myParam; // 단일 입력과 출력용 간단한 증폭기. automationRate가 "k-rate"이므로 각 render quantum마다 인덱스 [0]에 단일 값이 있습니다. for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { output[ channel][ i] = input[ channel][ i] * myParam[ 0 ]; } } } }
1.32.5.3.1.
콜백 AudioWorkletProcessCallback
파라미터
아래는 AudioWorkletProcessCallback
함수의 파라미터에 대해 설명합니다.
일반적으로 inputs
및 outputs
배열은 호출 사이에 재사용되어 메모리 할당이 발생하지 않습니다. 하지만 예를 들어 입력이나 출력의 채널 수가 변경되어 토폴로지가 바뀌면 새로운 배열이 재할당됩니다. inputs
또는 outputs
배열의 일부가 전송될 경우에도 새로운 배열이 재할당됩니다.
inputs, 타입FrozenArray<FrozenArray<Float32Array>>-
사용자 에이전트가 제공하는 들어오는 연결의 입력 오디오 버퍼입니다.
inputs[n][m]은Float32Array타입으로, \(n\)번째 입력의 \(m\)번째 채널의 오디오 샘플을 담고 있습니다. 입력 개수는 생성 시 고정되지만, 채널 개수는 computedNumberOfChannels에 따라 동적으로 변경될 수 있습니다.현행 표준에 따라
AudioWorkletNode의 \(n\)번째 입력에 actively processingAudioNode가 연결되어 있지 않으면, 해당 render quantum 동안inputs[n]의 내용은 빈 배열이 됩니다. 이는 입력 채널 수가 0임을 나타냅니다. 이 경우만inputs[n]의 요소 수가 0이 될 수 있습니다. outputs, 타입FrozenArray<FrozenArray<Float32Array>>-
사용자 에이전트가 소비할 출력 오디오 버퍼입니다.
outputs[n][m]은Float32Array객체로, \(n\)번째 출력의 \(m\)번째 채널의 오디오 샘플을 담고 있습니다. 각Float32Array는 0으로 채워집니다. 출력 채널 수는 노드가 단일 출력을 가질 때만 computedNumberOfChannels와 일치합니다. parameters, 타입object-
ordered map 형태의 name → parameterValues 쌍.
parameters["name"]는 parameterValues를 반환하며, 이는FrozenArray<Float32Array>로, 해당 nameAudioParam의 오토메이션 값(automation values)을 담고 있습니다.각 배열에는 해당 파라미터의 computedValue가 렌더 퀀텀(render quantum) 내 모든 프레임에 대해 포함됩니다. 단, 해당 렌더 퀀텀 동안 오토메이션이 예약되지 않았다면, 배열 길이가 1일 수 있으며, 배열의 원소는 AudioParam의 렌더 퀀텀 내 상수 값이 됩니다.
이 객체는 다음 단계에 따라 frozen 처리됩니다.
-
parameter를 name과 값의 순서 있는 맵으로 설정합니다.
-
SetIntegrityLevel(parameter, frozen)
이렇게 freeze된 순서 있는 맵이
parameters인자로 전달됩니다.참고: 이 객체는 수정할 수 없으므로, 배열의 길이가 바뀌지 않는 한 동일 객체를 다음 호출에도 사용할 수 있습니다.
-
1.32.5.4. AudioParamDescriptor
AudioParamDescriptor
딕셔너리는 AudioParam
객체의 속성을 지정하는 데 사용되며,
이 객체는 AudioWorkletNode에서
사용됩니다.
dictionary AudioParamDescriptor {required DOMString name ;float defaultValue = 0;float minValue = -3.4028235e38;float maxValue = 3.4028235e38;AutomationRate automationRate = "a-rate"; };
1.32.5.4.1. Dictionary AudioParamDescriptor
멤버
이 멤버 값에는 제약이 있습니다. AudioParamDescriptor 처리 알고리즘에서 제약 조건을 참조하세요.
automationRate, 타입 AutomationRate, 기본값"a-rate"-
기본 오토메이션 속도를 나타냅니다.
defaultValue, 타입 float, 기본값0-
파라미터의 기본값을 나타냅니다.
maxValue, 타입 float, 기본값3.4028235e38-
최대값을 나타냅니다.
minValue, 타입 float, 기본값-3.4028235e38-
최소값을 나타냅니다.
name, 타입 DOMString-
파라미터의 이름을 나타냅니다.
1.32.6. AudioWorklet 이벤트 시퀀스
아래 그림은 AudioWorklet과
관련하여 발생하는 이상적인 이벤트 시퀀스를 보여줍니다.
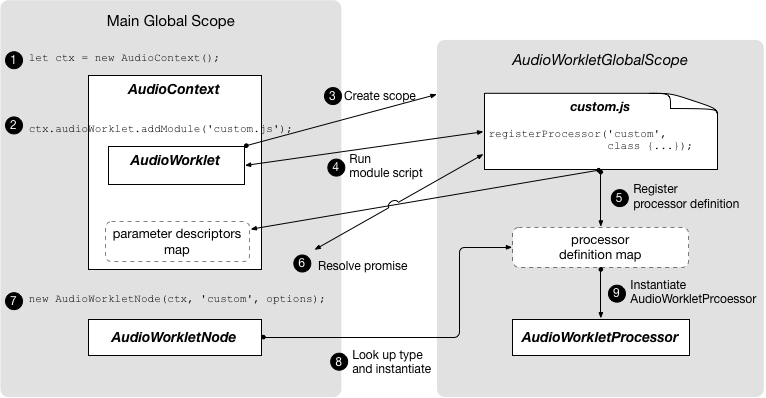
AudioWorklet
시퀀스 도식에 나타난 단계는 AudioContext
및 관련 AudioWorkletGlobalScope의
생성, 그 후 AudioWorkletNode와
관련 AudioWorkletProcessor
생성에 관한 한 가지 가능한 이벤트 시퀀스입니다.
-
AudioContext가 생성됩니다. -
메인 스코프에서
context.audioWorklet에 스크립트 모듈 추가가 요청됩니다. -
아직 존재하지 않으므로, 해당 context와 연결된 새로운
AudioWorkletGlobalScope가 생성됩니다. 이 글로벌 스코프에서AudioWorkletProcessor클래스 정의가 평가됩니다. (이후 호출에서는 이전에 생성된 스코프가 재사용됩니다.) -
임포트된 스크립트가 새로 생성된 글로벌 스코프에서 실행됩니다.
-
임포트된 스크립트 실행 과정에서
AudioWorkletProcessor가AudioWorkletGlobalScope내 키("custom"등)로 등록됩니다. 이 작업으로 글로벌 스코프와AudioContext의 맵이 채워집니다. -
addModule()호출에 대한 프로미스가 resolve됩니다. -
메인 스코프에서 사용자 지정 키와 옵션 딕셔너리를 사용해
AudioWorkletNode가 생성됩니다. -
노드 생성 과정에서 이 키를 사용하여 인스턴스화할 올바른
AudioWorkletProcessor서브클래스를 조회합니다. -
AudioWorkletProcessor서브클래스의 인스턴스가 같은 옵션 딕셔너리의 구조화 복제를 받아 인스턴스화됩니다. 이 인스턴스는 이전에 생성된AudioWorkletNode와 페어링됩니다.
1.32.7. AudioWorklet 예시
1.32.7.1. BitCrusher 노드
비트크러싱(bitcrushing)은 오디오 스트림의 품질을 샘플 값을 양자화(비트 깊이 감소 시뮬레이션)하고, 시간 해상도를 양자화(샘플 레이트 감소 시뮬레이션)함으로써 낮추는 방식입니다. 이
예제는 AudioParam을(여기서는
a-rate로 처리) AudioWorkletProcessor
내부에서 사용하는 방법을 보여줍니다.
const context= new AudioContext(); context. audioWorklet. addModule( 'bitcrusher.js' ). then(() => { const osc= new OscillatorNode( context); const amp= new GainNode( context); // 워크릿 노드 생성. 'BitCrusher'는 // bitcrusher.js 임포트 시 미리 등록된 AudioWorkletProcessor를 식별합니다. // 옵션은 대응되는 이름의 AudioParam을 자동으로 초기화합니다. const bitcrusher= new AudioWorkletNode( context, 'bitcrusher' , { parameterData: { bitDepth: 8 } }); osc. connect( bitcrusher). connect( amp). connect( context. destination); osc. start(); });
class Bitcrusherextends AudioWorkletProcessor{ static get parameterDescriptors() { return [{ name: 'bitDepth' , defaultValue: 12 , minValue: 1 , maxValue: 16 }, { name: 'frequencyReduction' , defaultValue: 0.5 , minValue: 0 , maxValue: 1 }]; } constructor () { super (); this . _phase= 0 ; this . _lastSampleValue= 0 ; } process( inputs, outputs, parameters) { const input= inputs[ 0 ]; const output= outputs[ 0 ]; const bitDepth= parameters. bitDepth; const frequencyReduction= parameters. frequencyReduction; if ( bitDepth. length> 1 ) { for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { let step= Math. pow( 0.5 , bitDepth[ i]); // frequencyReduction 배열 길이가 1인 경우 인덱싱을 위한 모듈로 연산 this . _phase+= frequencyReduction[ i% frequencyReduction. length]; if ( this . _phase>= 1.0 ) { this . _phase-= 1.0 ; this . _lastSampleValue= step* Math. floor( input[ channel][ i] / step+ 0.5 ); } output[ channel][ i] = this . _lastSampleValue; } } } else { // bitDepth가 이 호출에서 상수임을 알기 때문에, // step 계산을 루프 밖으로 뺄 수 있어 연산을 절약함. const step= Math. pow( 0.5 , bitDepth[ 0 ]); for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { this . _phase+= frequencyReduction[ i% frequencyReduction. length]; if ( this . _phase>= 1.0 ) { this . _phase-= 1.0 ; this . _lastSampleValue= step* Math. floor( input[ channel][ i] / step+ 0.5 ); } output[ channel][ i] = this . _lastSampleValue; } } } // 반환값 필요 없음; 이 노드의 생명주기는 입력 연결에만 의존함. } }; registerProcessor( 'bitcrusher' , Bitcrusher);
참고: AudioWorkletProcessor
클래스 정의에서, 저자가 제공한 생성자가 명시적으로 this가 아닌 값을 반환하거나 super()를 적절히 호출하지 않으면 InvalidStateError가
발생합니다.
1.32.7.2. VU 미터 노드
이 예제는 간단한 사운드 레벨 미터로, AudioWorkletNode
서브클래스를 생성하는 방법을 보여줍니다.
이 노드는 네이티브 AudioNode처럼
동작하며, 생성자 옵션을 받아 AudioWorkletNode와
AudioWorkletProcessor
간의 비동기 스레드 간 통신을 캡슐화합니다.
이 노드는 출력을 사용하지 않습니다.
/* vumeter-node.js: 메인 글로벌 스코프 */ export default class VUMeterNodeextends AudioWorkletNode{ constructor ( context, updateIntervalInMS) { super ( context, 'vumeter' , { numberOfInputs: 1 , numberOfOutputs: 0 , channelCount: 1 , processorOptions: { updateIntervalInMS: updateIntervalInMS|| 16.67 } }); // AudioWorkletNode 내 상태 this . _updateIntervalInMS= updateIntervalInMS; this . _volume= 0 ; // AudioWorkletProcessor로부터 갱신된 값을 처리 this . port. onmessage= event=> { if ( event. data. volume) this . _volume= event. data. volume; } this . port. start(); } get updateInterval() { return this . _updateIntervalInMS; } set updateInterval( updateIntervalInMS) { this . _updateIntervalInMS= updateIntervalInMS; this . port. postMessage({ updateIntervalInMS: updateIntervalInMS}); } draw() { // VU 미터를 |this._updateIntervalInMS| 밀리초마다 volume 값으로 그림 } };
/* vumeter-processor.js: AudioWorkletGlobalScope */ const SMOOTHING_FACTOR= 0.9 ; const MINIMUM_VALUE= 0.00001 ; registerProcessor( 'vumeter' , class extends AudioWorkletProcessor{ constructor ( options) { super (); this . _volume= 0 ; this . _updateIntervalInMS= options. processorOptions. updateIntervalInMS; this . _nextUpdateFrame= this . _updateIntervalInMS; this . port. onmessage= event=> { if ( event. data. updateIntervalInMS) this . _updateIntervalInMS= event. data. updateIntervalInMS; } } get intervalInFrames() { return this . _updateIntervalInMS/ 1000 * sampleRate; } process( inputs, outputs, parameters) { const input= inputs[ 0 ]; // 입력은 모노로 다운믹스됨; 연결된 입력이 없으면 0채널이 넘어옴. if ( input. length> 0 ) { const samples= input[ 0 ]; let sum= 0 ; let rms= 0 ; // 제곱합 계산 for ( let i= 0 ; i< samples. length; ++ i) sum+= samples[ i] * samples[ i]; // RMS 레벨 계산 및 volume 갱신 rms= Math. sqrt( sum/ samples. length); this . _volume= Math. max( rms, this . _volume* SMOOTHING_FACTOR); // volume 프로퍼티를 메인 스레드와 동기화 this . _nextUpdateFrame-= samples. length; if ( this . _nextUpdateFrame< 0 ) { this . _nextUpdateFrame+= this . intervalInFrames; this . port. postMessage({ volume: this . _volume}); } } // volume이 임계값 이상일 때 계속 처리. 입력이 끊겨도 미터가 즉시 멈추지 않게 함. return this . _volume>= MINIMUM_VALUE; } });
/* index.js: 메인 글로벌 스코프, 엔트리 포인트 */ import VUMeterNodefrom './vumeter-node.js' ; const context= new AudioContext(); context. audioWorklet. addModule( 'vumeter-processor.js' ). then(() => { const oscillator= new OscillatorNode( context); const vuMeterNode= new VUMeterNode( context, 25 ); oscillator. connect( vuMeterNode); oscillator. start(); function drawMeter() { vuMeterNode. draw(); requestAnimationFrame( drawMeter); } drawMeter(); });
2. 처리 모델
2.1. 배경
이 섹션은 비규범적입니다.
저지연(real-time) 오디오 시스템은 종종 콜백 함수를 사용하여 구현됩니다. 여기서 운영체제가 재생이 끊기지 않도록 추가 오디오를 계산해야 할 때 프로그램을 다시 호출합니다. 이러한 콜백은 이상적으로는 높은 우선순위의 스레드(종종 시스템에서 가장 높은 우선순위)에서 호출됩니다. 이는 오디오를 다루는 프로그램이 오로지 해당 콜백에서만 코드를 실행한다는 의미입니다. 스레드 경계를 넘거나 렌더링 스레드와 콜백 사이에 버퍼링을 추가하면 자연스럽게 지연이 늘어나거나 시스템이 글리치에 덜 견고해질 수 있습니다.
이런 이유로 웹 플랫폼에서 비동기 작업을 실행하는 전통적인 방식인 이벤트 루프는 이곳에서 동작하지 않습니다. 왜냐하면 해당 스레드는 지속적으로 실행되는 것이 아니기 때문입니다. 또한 전통적인 실행 컨텍스트(Windows 및 Worker)에서는 필요 없고 잠재적으로 블로킹되는 많은 작업이 제공되는데, 이는 수용 가능한 성능 수준을 달성하는 데 바람직하지 않습니다.
게다가 Worker 모델은 스크립트 실행 컨텍스트마다 전용 스레드를 생성해야 하지만, 모든 AudioNode는 보통
동일한 실행 컨텍스트를 공유합니다.
참고: 이 섹션은 최종 결과가 어떻게 보여야 하는지를 지정하며, 구현 방법에 대해 규정하지 않습니다. 특히, 메시지 큐 대신, 구현자는 메모리 연산이 재정렬되지 않는 한 스레드 간에 공유되는 메모리를 사용할 수 있습니다.
2.2. 제어 스레드와 렌더링 스레드
Web Audio API는 제어 스레드와 렌더링 스레드를 사용하여 반드시 구현되어야 합니다.
제어 스레드는 AudioContext가
인스턴스화되는 스레드이며, 저자가 오디오 그래프를 조작하는 곳입니다. 즉, BaseAudioContext에서
작업을 호출하는 곳입니다. 렌더링
스레드는 실제 오디오 출력을 계산하는 스레드로, 제어 스레드의 호출에 반응합니다. 만약 AudioContext의
오디오를 계산한다면 실시간 콜백 기반 오디오 스레드가 될 수 있고, OfflineAudioContext의
오디오를 계산한다면 일반 스레드가 될 수 있습니다.
제어 스레드는 [HTML]에 설명된 전통적인 이벤트 루프를 사용합니다.
렌더링 스레드는 오디오 그래프 렌더링 섹션에서 설명된 특수 렌더링 루프를 사용합니다.
제어 스레드에서 렌더링 스레드로의 통신은 제어 메시지 전달을 통해 이루어집니다. 반대 방향의 통신은 일반적인 이벤트 루프 태스크를 사용합니다.
각 AudioContext는
하나의 제어 메시지 큐를 가지며, 이는 제어 메시지 목록입니다. 이들은 렌더링 스레드에서 실행되는 작업입니다.
제어
메시지 큐에 추가하기란, BaseAudioContext의
제어 메시지 큐 마지막에
메시지를 추가하는 것을 의미합니다.
참고: 예를 들어, source라는 AudioBufferSourceNode에서
start()를 성공적으로 호출하면, 연결된 BaseAudioContext의
제어 메시지가 제어 메시지 큐에 추가됩니다.
제어 메시지는 제어 메시지 큐에 삽입된 시간 순서대로 정렬됩니다. 가장 오래된 메시지는 제어 메시지 큐의 맨 앞에 있는 것입니다.
2.3. 비동기 작업
AudioNode의
메서드를 호출하는 것은 사실상 비동기적이며, 반드시 두 단계로 실행되어야 합니다: 동기 부분과 비동기 부분. 각 메서드마다 일부는 제어 스레드에서 실행되고(예: 잘못된 파라미터의 경우 예외 발생), 일부는 렌더링 스레드에서 실행됩니다(예:
AudioParam
값 변경).
AudioNode 및
BaseAudioContext의
각 작업 설명에서, 동기 섹션은 ⌛로 표시됩니다. 나머지 작업은 병렬로 실행됩니다. 이는 [HTML]에 설명되어 있습니다.
동기 섹션은 제어 스레드에서 즉시 실행됩니다. 실패하면 메서드 실행이 중단되고 예외를 발생시킬 수 있습니다. 성공하면, 제어 메시지를 생성하여 렌더링 스레드에서 실행할 작업을 인코딩하고, 해당 제어 메시지 큐에 추가합니다.
동기 및 비동기 섹션의 이벤트 순서는 반드시 동일해야 합니다: 작업 A와 B가 각각 동기 및 비동기 섹션 ASync, AAsync, BSync, BAsync를 갖는다고 할 때, A가 B보다 먼저 발생하면 ASync가 BSync보다 먼저 실행되고, AAsync가 BAsync보다 먼저 실행되어야 합니다. 즉, 동기 및 비동기 섹션은 재정렬될 수 없습니다.
2.4. 오디오 그래프 렌더링
오디오 그래프 렌더링은 샘플 프레임 블록 단위로 수행되며, 각 블록의 크기는 BaseAudioContext
수명 동안 변하지 않습니다.
블록의 샘플 프레임 수를 렌더 퀀텀
크기(render quantum size)라 하며, 블록 자체를 렌더 퀀텀(render quantum)이라 합니다. 기본값은 128이며, renderSizeHint로
설정할 수 있습니다.
특정 스레드에서 원자적으로(atomically) 발생하는 연산은 다른 스레드에서 원자적 연산이 실행 중이 아닐 때만 실행할 수 있습니다.
BaseAudioContext
G에서 제어 메시지 큐 Q를
사용해 오디오 블록을 렌더링하는 알고리즘은 여러 단계로 구성되어 있으며, 그래프 렌더링 알고리즘에서 더 자세히 설명됩니다.
AudioContext의
렌더링 스레드는 주기적으로 호출되는
시스템 레벨 오디오
콜백(system-level audio callback)에 의해 동작합니다. 각 호출마다 시스템 레벨 오디오 콜백 버퍼 크기(system-level audio callback buffer
size)가 있는데, 이는 다음 시스템 레벨 오디오 콜백이 도착하기 전에 시간 내에 계산되어야 하는 샘플 프레임 수입니다.
각 시스템
레벨 오디오 콜백마다 부하 값(load
value)이 계산되는데, 이는 실행 소요 시간 / (시스템
레벨 오디오 콜백 버퍼 크기 / sampleRate)로
산출합니다.
이상적으로는 부하 값이 1.0 미만이어야 하며, 이는 오디오를 렌더링하는 데 소요된 시간이 실제 재생 시간보다 짧았다는 뜻입니다. 오디오 버퍼 언더런(audio buffer underrun)은 부하 값이 1.0을 초과할 때 발생하며, 시스템이 실시간으로 오디오를 충분히 빠르게 렌더링하지 못한 경우입니다.
시스템 레벨
오디오 콜백 및 부하 값 개념은 OfflineAudioContext에는
적용되지 않습니다.
오디오 콜백은 제어 메시지 큐에도 태스크로 큐잉됩니다. UA는
렌더 퀀텀을 처리하여 요청된 버퍼 크기를 채우기 위해 다음 알고리즘을 반드시 수행해야 합니다. 제어 메시지 큐와 함께, 각 AudioContext에는
태스크 큐가 있으며, 이를 연결된 태스크 큐(associated task queue)라 하며, 이는 제어 스레드에서 렌더링
스레드로 게시된 태스크를 저장합니다. process 메서드 실행 중 큐잉된 마이크로태스크를 실행하기 위해 렌더 퀀텀 처리 후 마이크로태스크 체크포인트도 추가로 수행됩니다.
모든 AudioWorkletNode에서
게시된 태스크는 연결된 BaseAudioContext의
연결된 태스크 큐에 게시됩니다.
-
BaseAudioContext의 내부 슬롯[[current frame]]을 0으로 설정합니다. 또한currentTime도 0으로 설정합니다.
-
render result를
false로 설정합니다. -
제어 메시지 큐를 처리합니다.
-
Qrendering을 빈 제어 메시지 큐로 설정합니다. 원자적으로 스왑 Qrendering과 현재 제어 메시지 큐를 교환합니다.
-
Qrendering에 메시지가 있는 동안, 다음 단계를 반복합니다:
-
Qrendering의 가장 오래된 메시지의 비동기 섹션을 실행합니다.
-
Qrendering의 가장 오래된 메시지를 제거합니다.
-
-
-
BaseAudioContext의 연결된 태스크 큐를 처리합니다.-
task queue를
BaseAudioContext의 연결된 태스크 큐로 설정합니다. -
task count를 task queue 내 태스크 개수로 설정합니다.
-
task count가 0이 아니면, 다음 단계를 반복합니다:
-
oldest task를 task queue 내 첫 번째 실행 가능한 태스크로 설정하고, task queue에서 제거합니다.
-
렌더링 루프의 현재 실행 중인 태스크를 oldest task로 설정합니다.
-
oldest task의 단계를 실행합니다.
-
렌더링 루프의 현재 실행 중인 태스크를 다시
null로 설정합니다. -
task count를 감소시킵니다.
-
마이크로태스크 체크포인트를 수행합니다.
-
-
-
렌더 퀀텀을 처리합니다.
-
[[rendering thread state]]가running이 아니면false를 반환합니다. -
AudioNode들을BaseAudioContext에 대해 처리될 순서로 정렬합니다.-
ordered node list를
AudioNode와AudioListener의 빈 리스트로 초기화합니다. 이 알고리즘이 종료되면 ordered node list에는 정렬된AudioNode들과AudioListener가 담깁니다. -
nodes를 이
BaseAudioContext에서 생성되어 아직 살아있는 모든 노드 집합으로 설정합니다. -
AudioListener를 nodes에 추가합니다. -
cycle breakers를
DelayNode의 빈 집합으로 초기화합니다. 사이클에 포함된 모든DelayNode를 담게 됩니다. -
nodes의 각
AudioNodenode에 대해:-
node가 사이클에 포함된
DelayNode라면 cycle breakers에 추가하고 nodes에서 제거합니다.
-
-
cycle breakers의 각
DelayNodedelay에 대해:-
delayWriter와 delayReader를 각각 delay에 대한 DelayWriter와 DelayReader로 설정합니다. delayWriter와 delayReader를 nodes에 추가합니다. delay의 모든 입력과 출력을 끊습니다.
참고: 이로써 사이클이 끊어집니다:
DelayNode가 사이클에 있으면 두 끝을 별도로 간주할 수 있습니다. 사이클 내의 delay line은 최소 한 렌더 퀀텀보다 작을 수 없습니다.
-
-
nodes에 사이클이 있으면 이 사이클에 포함된 모든
AudioNode를 뮤트하고 nodes에서 제거합니다. -
nodes의 모든 요소를 표시하지 않은 상태로 간주합니다. nodes에 표시되지 않은 요소가 있는 동안:
-
nodes에서 node를 하나 선택합니다.
-
Visit node를 실행합니다.
-
-
ordered node list의 순서를 반대로 뒤집습니다.
-
-
AudioListener의AudioParam의 값을 이 블록에 대해 계산합니다. -
ordered node list의 각
AudioNode에 대해:-
이
AudioNode의 각AudioParam에 대해 다음을 실행합니다:-
이
AudioParam에AudioNode가 연결되어 있다면, 모든 연결된AudioNode가 읽기 가능하게 만든 버퍼를 합산(sum)하고, 결과 버퍼를 모노 채널로 다운 믹스하여 input AudioParam buffer로 칭합니다. -
이
AudioParam의 값을 이 블록에 대해 계산합니다. -
제어 메시지 큐에 추가하여 이
[[current value]]슬롯을 § 1.6.3 Computation of Value에 따라 설정합니다.
-
-
이
AudioNode에 입력에 연결된AudioNode가 있으면, 모든 연결된AudioNode가 읽기 가능하게 만든 버퍼를 합산(sum)합니다. 결과 버퍼를 input buffer라 하며, 입력 채널 수에 맞게 업/다운 믹스합니다. -
이
AudioNode가 source node라면 오디오 블록을 계산하고 읽기 가능하게 만듭니다. -
이
AudioNode가AudioWorkletNode라면, 다음 하위 단계를 실행합니다:-
processor를
AudioWorkletProcessor인스턴스로 설정합니다. -
O를 processor에 해당하는 ECMAScript 객체로 설정합니다.
-
processCallback과 completion을 초기화되지 않은 변수로 설정합니다.
-
스크립트 실행 준비를 현재 설정 객체로 실행합니다.
-
getResult를 Get(O, "process")로 설정합니다.
-
getResult가 abrupt completion이면 completion을 getResult로 설정하고 return 단계로 이동합니다.
-
processCallback을 getResult.[[Value]]로 설정합니다.
-
! IsCallable(processCallback)이
false라면:-
completion을 새 Completion {[[Type]]: throw, [[Value]]: 새 TypeError 객체, [[Target]]: empty}로 설정합니다.
-
return 단계로 이동합니다.
-
-
[[callable process]]를true로 설정합니다. -
다음 하위 단계를 수행합니다:
-
args를
inputs,outputs,parameters로 이루어진 Web IDL arguments list로 설정합니다. -
esArgs를 변환(args를 ECMAScript arguments list로) 결과로 설정합니다.
-
callResult를 Call(processCallback, O, esArgs)로 설정합니다. 이 연산은 오디오 블록을 계산하며, 성공 시
outputs로 전달된Float32Array의 요소 복사본을 담은 버퍼가 읽기 가능하게 됨. 이 호출 내에서 resolve된Promise는AudioWorkletGlobalScope의 마이크로태스크 큐에 큐잉됨. -
callResult가 abrupt completion이면 completion을 callResult로 설정하고 return 단계로 이동합니다.
-
processor의 active source 플래그를 ToBoolean(callResult.[[Value]])로 설정합니다.
-
-
Return: 이 시점에서 completion은 ECMAScript completion 값으로 설정됩니다.
-
콜백 실행 후 정리를 현재 설정 객체로 수행합니다.
-
스크립트 실행 후 정리를 현재 설정 객체로 수행합니다.
-
completion이 abrupt completion이면:
-
[[callable process]]를false로 설정합니다. -
processor의 active source 플래그를
false로 설정합니다. -
태스크 큐에 추가하여 제어 스레드에서
processorerror이벤트를AudioWorkletNode에ErrorEvent로 발생시킵니다.
-
-
-
-
이
AudioNode가 destination node라면, 이AudioNode의 입력을 레코딩합니다. -
그 외의 경우, 입력 버퍼 처리를 하고, 결과 버퍼를 읽기 가능하게 만듭니다.
-
-
원자적으로 다음 단계를 수행합니다:
-
[[current frame]]을 렌더 퀀텀 크기만큼 증가시킵니다. -
currentTime을[[current frame]]을sampleRate로 나눈 값으로 설정합니다.
-
-
render result를
true로 설정합니다.
-
-
render result를 반환합니다.
뮤트(Muting)란 AudioNode의
출력을 해당 오디오 블록 렌더링 시 반드시 무음으로 만드는 것을 의미합니다.
버퍼를 읽기 가능하게 만들기란,
AudioNode에서
이 AudioNode에
연결된 다른 AudioNode들이
안전하게 읽을 수 있는 상태로 만드는 것을 의미합니다.
참고: 예를 들어, 구현체는 새 버퍼를 할당하거나, 기존에 사용되지 않는 버퍼를 재사용하는 등 더 정교한 메커니즘을 선택할 수 있습니다.
입력 레코딩(Recording the
input)이란,
AudioNode의
입력 데이터를
미래의 사용을 위해 복사하는 것을 의미합니다.
오디오 블록
계산(Computing a block of audio)이란,
해당 AudioNode의
알고리즘을 실행하여
[[render quantum size]]만큼
샘플 프레임을 생성하는 것을 의미합니다.
입력 버퍼
처리(Processing an input buffer)란,
AudioNode에
대해
input buffer와 해당 AudioParam
값들을
알고리즘의 입력으로 사용하여 알고리즘을 실행하는 것을 의미합니다.
2.5. 시스템 오디오 리소스 오류 처리 - AudioContext
AudioContext
audioContext가 오디오 시스템 리소스 오류 발생 시 렌더링 스레드에서 다음 단계를 수행합니다.
-
audioContext의
[[rendering thread state]]가running이라면:-
시스템 리소스 해제를 시도합니다.
-
audioContext의
[[rendering thread state]]를suspended로 설정합니다. -
미디어 요소 태스크 큐에 추가하여 다음 단계를 실행합니다:
-
audioContext의
[[suspended by user]]를false로 설정합니다. -
audioContext의
[[control thread state]]를suspended로 설정합니다. -
이벤트 발생 -
statechange이벤트를 audioContext에 발생시킵니다.
-
이 단계를 중단합니다.
-
-
audioContext의
[[rendering thread state]]가suspended라면:-
미디어 요소 태스크 큐에 추가하여 다음 단계를 실행합니다:
-
참고: 시스템 오디오 리소스 오류의 예로는 AudioContext가
활성 렌더링 중에 외부 또는 무선 오디오 장치가 연결 해제되는 경우가 있습니다.
2.6. 문서 언로드(Unloading a document)
문서 언로드 정리 단계가BaseAudioContext를
사용하는 문서에 대해 추가로 정의됩니다:
-
문서의 연결된 Window와 동일한 글로벌 객체를 갖는
AudioContext및OfflineAudioContext각각에 대해[[pending promises]]의 모든 프로미스를InvalidStateError로 reject합니다. -
모든
decoding thread를 중지합니다. -
제어 메시지 큐에 추가하여
close()를AudioContext또는OfflineAudioContext에 수행합니다.
3. 동적 수명(Dynamic Lifetime)
3.1. 배경(Background)
참고: AudioContext
및 AudioNode의 수명
특성에 대한 현행 표준 설명은 AudioContext 수명과 AudioNode 수명에 나와 있습니다.
이 섹션은 비규범적입니다.
정적 라우팅 구성을 생성하는 것 외에도, 제한된 수명을 가진 동적으로 할당된 보이스에 대해 커스텀 이펙트 라우팅을 하는 것도 가능해야 합니다. 여기에서는 이러한 단명 보이스를 "노트"라 부르겠습니다. 많은 오디오 응용프로그램에서는 노트 개념을 포함하고 있는데, 예로는 드럼머신, 시퀀서, 그리고 게임플레이에 따라 많은 일회성(one-shot) 사운드가 트리거되는 3D 게임 등이 있습니다.
전통적인 소프트웨어 신시사이저에서는 노트가 보유 리소스 풀에서 동적으로 할당되고 해제됩니다. MIDI note-on 메시지를 받을 때 노트가 할당되고, 샘플 데이터가 끝에 도달했거나(루프 아님), envelope의 sustain 단계가 0이거나, MIDI note-off 메시지로 envelope의 release 단계에 들어간 경우에 노트가 해제됩니다. MIDI note-off의 경우 즉시 해제되지 않고 release envelope 단계가 끝날 때까지 남아 있습니다. 언제든지 많은 노트가 연주 중일 수 있지만 새로운 노트가 라우팅 그래프에 추가되고, 오래된 노트가 해제되면서 노트 집합은 계속 바뀝니다.
오디오 시스템은 개별 "노트" 이벤트에 대한 라우팅 그래프 부분을 자동으로 해제합니다. "노트"는 AudioBufferSourceNode로
표현되며, 다른 처리 노드에 직접 연결될 수 있습니다. 노트가 재생을 마치면, context는 AudioBufferSourceNode에
대한 참조를 자동으로 해제하며, 그에 따라 연결된 노드에 대한 참조도 해제됩니다. 이 노드들은 더 이상 참조가 없으면 그래프에서 자동으로 분리되고 삭제됩니다. 그래프 내에서 장기적으로 공유되는
노드는 명시적으로 관리할 수 있습니다. 복잡해 보이지만, 이 모든 것은 별도의 처리 없이 자동으로 이루어집니다.
3.2. 예시(Example)
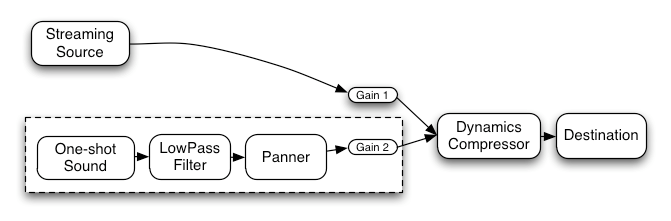
로우패스 필터, 패너, 두 번째 게인 노드는 일회성(one-shot) 사운드에서 직접 연결됩니다. 이 사운드가 재생을 마치면 context가(점선 내부의 모든 것을) 자동으로 해제합니다. 일회성 사운드 및 연결된 노드에 더 이상 참조가 없으면, 즉시 그래프에서 제거되고 삭제됩니다. 스트리밍 소스는 글로벌 참조를 가지므로 명시적으로 분리할 때까지 연결된 상태로 남습니다. 아래는 JavaScript 예시입니다:
let context= 0 ; let compressor= 0 ; let gainNode1= 0 ; let streamingAudioSource= 0 ; // "장기" 라우팅 그래프 초기 설정 function setupAudioContext() { context= new AudioContext(); compressor= context. createDynamicsCompressor(); gainNode1= context. createGain(); // 스트리밍 오디오 소스 생성 const audioElement= document. getElementById( 'audioTagID' ); streamingAudioSource= context. createMediaElementSource( audioElement); streamingAudioSource. connect( gainNode1); gainNode1. connect( compressor); compressor. connect( context. destination); } // 이후 사용자의 액션(마우스/키 이벤트 등)에 반응하여 // 일회성 사운드를 재생할 수 있습니다. function playSound() { const oneShotSound= context. createBufferSource(); oneShotSound. buffer= dogBarkingBuffer; // 필터, 패너, 게인 노드 생성 const lowpass= context. createBiquadFilter(); const panner= context. createPanner(); const gainNode2= context. createGain(); // 연결 oneShotSound. connect( lowpass); lowpass. connect( panner); panner. connect( gainNode2); gainNode2. connect( compressor); // 현재 시간 + 0.75초에 재생(즉시 재생하려면 0 전달) oneShotSound. start( context. currentTime+ 0.75 ); }
4. 채널 업믹싱/다운믹싱(Channel Up-Mixing and Down-Mixing)
이 섹션은 규범적입니다.
AudioNode 입력에는 연결된 모든 채널을 조합하는 믹싱 규칙(mixing rules)이 있습니다. 예를 들어 한 입력이 모노 출력과 스테레오 출력에서 연결된 경우, 일반적으로 모노 연결이
스테레오로 업믹싱되고 스테레오 연결과 합산됩니다. 하지만 모든 AudioNode의 각
입력에 대해 정확한 믹싱 규칙을 정의하는 것이 중요합니다.
모든 입력에 대한 기본 믹싱 규칙은, 특히 모노와 스테레오 스트림에 대해 세부 사항을 크게 신경 쓰지 않아도 "그냥 동작"하도록 선택되었습니다. 물론, 고급 사용 사례(예: 멀티채널)에서는
규칙을 변경할 수 있습니다.
용어 정의를 위해 업믹싱(up-mixing)은 더 적은 채널의 스트림을 더 많은 채널의 스트림으로 변환하는 과정을 의미합니다. 다운믹싱(down-mixing)은 더 많은 채널의 스트림을 더 적은 채널의 스트림으로 변환하는 과정을 의미합니다.
AudioNode
입력은 연결된 모든 출력 채널을 믹스해야 하며, 이 과정에서 임의 시점의 실제 입력 채널 수를 나타내는 내부 값 computedNumberOfChannels를
계산합니다.
AudioNode의
각 입력에 대해, 구현체는 반드시 다음을 수행해야 합니다:
-
computedNumberOfChannels를 계산합니다.
-
입력에 대한 각 연결에 대해:
-
해당 연결을
ChannelInterpretation값(노드의channelInterpretation속성으로 지정)에 따라 업믹싱 또는 다운믹싱하여 computedNumberOfChannels에 맞춥니다. -
업믹싱/다운믹싱된 각 연결 스트림을 다른 연결의 믹스된 스트림과 합칩니다(각 연결에 대해 1번 단계에서 업믹싱 또는 다운믹싱된 대응 채널을 단순히 합산).
-
4.1. 스피커 채널 레이아웃(Speaker Channel Layouts)
channelInterpretation이
"speakers"일
때,
업믹싱과 다운믹싱은 특정 채널 레이아웃에 대해 정의됩니다.
모노(1채널), 스테레오(2채널), 쿼드(4채널), 5.1(6채널)은 반드시 지원되어야 합니다. 기타 채널 레이아웃은 현행 표준의 미래 버전에서 지원될 수 있습니다.
4.2. 채널 순서(Channel Ordering)
채널 순서는 다음 표에 의해 정의됩니다. 개별 멀티채널 포맷은 모든 중간 채널을 지원하지 않을 수 있습니다. 구현체는 아래에 정의된 순서대로 채널을 제공해야 하며, 없는 채널은 건너뛰어야 합니다.
| 순서(Order) | 라벨(Label) | 모노(Mono) | 스테레오(Stereo) | 쿼드(Quad) | 5.1 |
|---|---|---|---|---|---|
| 0 | SPEAKER_FRONT_LEFT | 0 | 0 | 0 | 0 |
| 1 | SPEAKER_FRONT_RIGHT | 1 | 1 | 1 | |
| 2 | SPEAKER_FRONT_CENTER | 2 | |||
| 3 | SPEAKER_LOW_FREQUENCY | 3 | |||
| 4 | SPEAKER_BACK_LEFT | 2 | 4 | ||
| 5 | SPEAKER_BACK_RIGHT | 3 | 5 | ||
| 6 | SPEAKER_FRONT_LEFT_OF_CENTER | ||||
| 7 | SPEAKER_FRONT_RIGHT_OF_CENTER | ||||
| 8 | SPEAKER_BACK_CENTER | ||||
| 9 | SPEAKER_SIDE_LEFT | ||||
| 10 | SPEAKER_SIDE_RIGHT | ||||
| 11 | SPEAKER_TOP_CENTER | ||||
| 12 | SPEAKER_TOP_FRONT_LEFT | ||||
| 13 | SPEAKER_TOP_FRONT_CENTER | ||||
| 14 | SPEAKER_TOP_FRONT_RIGHT | ||||
| 15 | SPEAKER_TOP_BACK_LEFT | ||||
| 16 | SPEAKER_TOP_BACK_CENTER | ||||
| 17 | SPEAKER_TOP_BACK_RIGHT |
4.3. 입력/출력 채널 수에 tail-time이 미치는 영향(Implication of tail-time on input and output channel count)
AudioNode에
0이 아닌 tail-time이 있고 출력 채널 수가 입력 채널 수에
따라 달라지는 경우,
입력 채널 수가 변경될 때 AudioNode의 tail-time을 반드시 고려해야 합니다.
입력 채널 수가 감소할 때, 출력 채널 수의 변화는 더 많은 채널 수를 가졌던 입력이 더 이상 출력에 영향을 주지 않을 때 반드시 발생해야 합니다.
입력 채널 수가 증가할 때, 동작은 AudioNode 유형에
따라 달라집니다:
-
DelayNode나DynamicsCompressorNode의 경우, 더 많은 채널 수의 입력이 출력에 영향을 주기 시작할 때 출력 채널 수가 반드시 증가해야 합니다. -
tail-time이 있는 그 외
AudioNode에서는 출력 채널 수가 즉시 증가해야 합니다.참고:
ConvolverNode의 경우, 이는 임펄스 응답이 모노일 때만 적용됩니다. 그렇지 않으면ConvolverNode는 입력 채널 수와 상관없이 항상 스테레오 신호를 출력합니다.
참고: 직관적으로, 이는 처리 과정에서 스테레오 정보를 잃지 않도록 해줍니다. 즉, 여러 입력 렌더 퀀텀에 서로 다른 채널 수가 있을 때 출력 렌더 퀀텀의 채널 수는 입력 렌더 퀀텀들의 입력 채널 수의 합집합이 됩니다.
4.4. 스피커 레이아웃 업믹싱(Up Mixing Speaker Layouts)
모노 업믹싱:
1 -> 2 : 모노에서 스테레오로 업믹싱
output.L = input;
output.R = input;
1 -> 4 : 모노에서 쿼드로 업믹싱
output.L = input;
output.R = input;
output.SL = 0;
output.SR = 0;
1 -> 5.1 : 모노에서 5.1로 업믹싱
output.L = 0;
output.R = 0;
output.C = input; // 센터 채널에 배치
output.LFE = 0;
output.SL = 0;
output.SR = 0;
스테레오 업믹싱:
2 -> 4 : 스테레오에서 쿼드로 업믹싱
output.L = input.L;
output.R = input.R;
output.SL = 0;
output.SR = 0;
2 -> 5.1 : 스테레오에서 5.1로 업믹싱
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = 0;
output.SR = 0;
쿼드 업믹싱:
4 -> 5.1 : 쿼드에서 5.1로 업믹싱
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = input.SL;
output.SR = input.SR;
4.5. 스피커 레이아웃 다운믹싱(Down Mixing Speaker Layouts)
예를 들어 5.1 소스 소재를 처리하고 있지만 스테레오로 재생하는 경우 다운믹싱이 필요할 수 있습니다.
모노 다운믹싱:
2 -> 1 : 스테레오에서 모노로
output = 0.5 * (input.L + input.R);
4 -> 1 : 쿼드에서 모노로
output = 0.25 * (input.L + input.R + input.SL + input.SR);
5.1 -> 1 : 5.1에서 모노로
output = sqrt(0.5) * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
스테레오 다운믹싱:
4 -> 2 : 쿼드에서 스테레오로
output.L = 0.5 * (input.L + input.SL);
output.R = 0.5 * (input.R + input.SR);
5.1 -> 2 : 5.1에서 스테레오로
output.L = L + sqrt(0.5) * (input.C + input.SL)
output.R = R + sqrt(0.5) * (input.C + input.SR)
쿼드 다운믹싱:
5.1 -> 4 : 5.1에서 쿼드로
output.L = L + sqrt(0.5) * input.C
output.R = R + sqrt(0.5) * input.C
output.SL = input.SL
output.SR = input.SR
4.6. 채널 규칙 예시(Channel Rules Examples)
// Set gain node to explicit 2-channels (stereo). gain. channelCount= 2 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ; // Set "hardware output" to 4-channels for DJ-app with two stereo output busses. context. destination. channelCount= 4 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // Set "hardware output" to 8-channels for custom multi-channel speaker array // with custom matrix mixing. context. destination. channelCount= 8 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // Set "hardware output" to 5.1 to play an HTMLAudioElement. context. destination. channelCount= 6 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "speakers" ; // Explicitly down-mix to mono. gain. channelCount= 1 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ;
5. 오디오 신호 값(Audio Signal Values)
5.1. 오디오 샘플 포맷(Audio sample format)
선형 펄스 코드 변조(linear pulse code modulation)(linear PCM)은 오디오 값을 일정한 간격으로 샘플링하고, 연속하는 두 값 사이의 양자화 레벨이 선형적으로 동일한 포맷을 설명합니다.
현행 표준에서 신호 값이 스크립트에 노출될 때마다, 값은 선형 32비트 부동소수점 펄스 코드 변조 포맷(선형 32비트 float PCM)으로, 주로 Float32Array
객체 형태로 제공됩니다.
5.2. 렌더링(Rendering)
오디오 그래프의 목적지 노드에서 모든 오디오 신호의 범위는 일반적으로 [-1, 1]입니다. 이 범위를 벗어난 신호 값, 또는 NaN·양의 무한대·음의 무한대 값의 오디오
렌더링은 현행 표준에서 정의되지 않습니다.
6. 공간화/팬닝(Spatialization/Panning)
6.1. 배경(Background)
현대 3D 게임에서 흔히 요구되는 기능은 여러 오디오 소스를 3D 공간 내에서 동적으로 공간화 및 이동시키는 능력입니다. 예를 들어 OpenAL은 이런 기능을 제공합니다.
PannerNode를
사용하면 오디오 스트림을 AudioListener에
상대적으로 공간화하거나 위치시킬 수 있습니다.
BaseAudioContext에는
하나의 AudioListener가
포함됩니다.
팬너와 리스너 모두 오른손 좌표계(cartesian coordinate system)를 사용하여 3D 공간에서 위치를 지정합니다. 좌표계에서 사용하는 단위는 정의되지 않으며, 미터나 피트 등
특정 단위와 무관하게 효과가 계산됩니다.
PannerNode
객체(소스 스트림)는 소리가 투영되는 방향을 나타내는 orientation 벡터를 가집니다. 또한 sound cone(사운드 콘)도 가지며, 이는 소리의 방향성을
나타냅니다. 예를 들어 소리가 전방위(omnidirectional)일 경우 방향에 상관없이 들리지만, 더 방향성이 강하면 리스너를 향할 때만 들립니다. AudioListener
객체(사람의 귀)는 forward와 up 벡터를 가져, 사람이 바라보는 방향을 나타냅니다.
공간화 좌표계는 아래 그림에 나타나며, 기본값이 표시되어 있습니다. AudioListener와
PannerNode의
위치를 기본 위치에서 옮겨 더 잘 보이도록 했습니다.

렌더링 중에는 PannerNode가
azimuth(방위각)와 elevation(고도각)을 계산합니다. 이 값은 공간화 효과를 렌더링하기 위해 구현체 내부에서 사용됩니다. 이 값이 어떻게 사용되는지에
대한 자세한 내용은 팬닝 알고리즘(Panning Algorithm) 섹션을 참고하세요.
6.2. 방위각과 고도각(Azimuth and Elevation)
아래 알고리즘은 PannerNode의
azimuth와 elevation을 계산할 때 반드시 사용되어야 합니다. 아래 AudioParam들이
"a-rate"인지
"k-rate"인지
구현체가 적절히 고려해야 합니다.
// |context|는 BaseAudioContext, |panner|는 context에서 생성된 PannerNode라고 가정 // 소스-리스너 벡터 계산 // 소스-리스너 벡터 계산 const listener= context. listener; const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceListener= sourcePosition. diff( listenerPosition). normalize(); if ( sourceListener. magnitude== 0 ) { // 소스와 리스너가 동일한 위치일 때 처리 azimuth= 0 ; elevation= 0 ; return ; } // 축 정렬 const listenerForward= new Vec3( listener. forwardX. value, listener. forwardY. value, listener. forwardZ. value); const listenerUp= new Vec3( listener. upX. value, listener. upY. value, listener. upZ. value); const listenerRight= listenerForward. cross( listenerUp); if ( listenerRight. magnitude== 0 ) { // 리스너의 'up'과 'forward' 벡터가 선형적으로 종속적일 때 'right'를 구할 수 없음 azimuth= 0 ; elevation= 0 ; return ; } // 리스너의 right, forward에 수직인 단위 벡터 결정 const listenerRightNorm= listenerRight. normalize(); const listenerForwardNorm= listenerForward. normalize(); const up= listenerRightNorm. cross( listenerForwardNorm); const upProjection= sourceListener. dot( up); const projectedSource= sourceListener. diff( up. scale( upProjection)). normalize(); azimuth= 180 * Math. acos( projectedSource. dot( listenerRightNorm)) / Math. PI; // 소스가 리스너 앞/뒤에 있는지 const frontBack= projectedSource. dot( listenerForwardNorm); if ( frontBack< 0 ) azimuth= 360 - azimuth; // azimuth를 리스너의 "forward"가 아니라 "right" 기준으로 변환 if (( azimuth>= 0 ) && ( azimuth<= 270 )) azimuth= 90 - azimuth; else azimuth= 450 - azimuth; elevation= 90 - 180 * Math. acos( sourceListener. dot( up)) / Math. PI; if ( elevation> 90 ) elevation= 180 - elevation; else if ( elevation< - 90 ) elevation= - 180 - elevation;
6.3. 팬닝 알고리즘(Panning Algorithm)
모노-스테레오와 스테레오-스테레오 팬닝은 반드시 지원되어야 합니다. 입력의 모든 연결이 모노인 경우 모노-스테레오 처리가 사용됩니다. 그렇지 않으면 스테레오-스테레오 처리가 사용됩니다.
6.3.1. PannerNode "equalpower" 팬닝
이것은 간단하고 비교적 효율적인 알고리즘으로 기본적이고 합리적인 결과를 제공합니다. PannerNode에서
panningModel
속성이
"equalpower"로
설정된 경우 사용되며, 이때 elevation 값은 무시됩니다. 이 알고리즘은 automationRate에
지정된 적절한 rate로 반드시 구현되어야 합니다.
PannerNode의
AudioParam이나
AudioListener의
AudioParam이
"a-rate"라면
a-rate 처리로 구현되어야 합니다.
-
이
AudioNode가 계산할 각 샘플에 대해:-
azimuth를 방위각과 고도각에서 계산한 값으로 설정합니다.
-
azimuth 값을 [-90, 90] 범위로 제한합니다:
// 우선 azimuth를 [-180, 180] 범위로 클램프 azimuth= max( - 180 , azimuth); azimuth= min( 180 , azimuth); // 이후 [-90, 90] 범위로 래핑 if ( azimuth< - 90 ) azimuth= - 180 - azimuth; else if ( azimuth> 90 ) azimuth= 180 - azimuth; -
정규화된 값 x를 모노 입력에서는 azimuth로부터 다음과 같이 계산:
x
= ( azimuth+ 90 ) / 180 ; 스테레오 입력에서는:
if ( azimuth<= 0 ) { // -90 -> 0 // azimuth [-90, 0] 범위를 [-90, 90] 범위로 변환 x= ( azimuth+ 90 ) / 90 ; } else { // 0 -> 90 // azimuth [0, 90] 범위를 [-90, 90] 범위로 변환 x= azimuth/ 90 ; } -
좌우 게인 값은 다음과 같이 계산:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
모노 입력의 경우 스테레오 출력은:
outputL
= input* gainL; outputR= input* gainR; 스테레오 입력의 경우 출력은:
if ( azimuth<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; } -
거리 게인(distance gain)과 콘 게인(cone gain)을 적용합니다. 거리는 Distance Effects, 콘 게인은 Sound Cones에서 설명합니다:
let distance= distance(); let distanceGain= distanceModel( distance); let totalGain= coneGain() * distanceGain(); outputL= totalGain* outputL; outputR= totalGain* outputR;
-
6.3.2. PannerNode "HRTF" 팬닝(스테레오 전용)
이 방식은 다양한 방위각(azimuth)과 고도각(elevation)에서 녹음된 HRTF 임펄스 응답이 필요합니다. 구현에는 고도로 최적화된 컨볼루션 함수가 필요하며, "equalpower"보다 비용은 다소 높지만 더 지각적으로 공간화된 소리를 제공합니다.
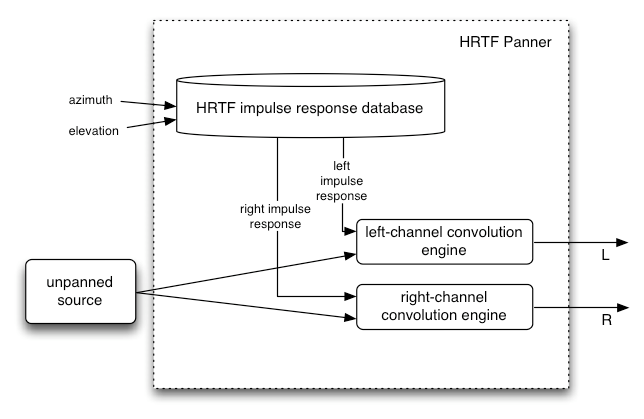
6.3.3. StereoPannerNode 팬닝
StereoPannerNode에
대해 다음 알고리즘을 반드시 구현해야 합니다.
-
이
AudioNode가 계산할 각 샘플에 대해-
pan을 이
panAudioParam의 computedValue로 설정합니다. -
pan을 [-1, 1]로 클램프합니다.
pan
= max( - 1 , pan); pan= min( 1 , pan); -
정규화한 x값을 pan에서 [0, 1]로 계산합니다. 모노 입력의 경우:
x
= ( pan+ 1 ) / 2 ; 스테레오 입력의 경우:
if ( pan<= 0 ) x= pan+ 1 ; else x= pan; -
좌우 게인 값은 다음과 같이 계산:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
모노 입력의 경우 스테레오 출력은:
outputL
= input* gainL; outputR= input* gainR; 스테레오 입력의 경우 출력은:
if ( pan<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; }
-
6.4. 거리 효과(Distance Effects)
소리가 가까우면 더 크게, 멀면 더 작게 들립니다. 소리의 볼륨이 리스너로부터의 거리에 따라 어떻게 변하는지는 distanceModel
속성에 따라 달라집니다.
오디오 렌더링 중에는, panner와 listener의 위치를 기반으로 distance 값이 아래와 같이 계산됩니다:
function distance( panner) { const pannerPosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listener= context. listener; const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); return pannerPosition. diff( listenerPosition). magnitude; }
distance는 이후 distanceModel
속성에 따라 distanceGain을 계산하는 데 사용됩니다. 각 distance model에 대한 계산 방법은 DistanceModelType
섹션을 참고하세요.
처리 과정에서 PannerNode는
입력 오디오 신호에 distanceGain을 곱해, 먼 소리는 더 작게, 가까운 소리는 더 크게 만듭니다.
6.5. 사운드 콘(Sound Cones)
리스너와 각 사운드 소스는 자신이 바라보는 방향을 설명하는 방향 벡터(orientation vector)를 가집니다. 각 사운드 소스의 소리 투영 특성은 내부 및 외부 "콘"으로 설명되며, 이는 소스 방향 벡터에서 소스/리스너 각도에 따른 소리의 세기를 나타냅니다. 즉, 리스너를 직접 향하면 소리가 더 크고, 축에서 벗어나면 더 작게 들립니다. 사운드 소스는 전방위(omni-directional)일 수도 있습니다.
아래 다이어그램은 리스너에 대한 소스 콘의 관계를 보여줍니다. 도식에서
coneInnerAngle
= 50coneOuterAngle
= 120

아래 알고리즘은 소스(PannerNode)와
리스너가 주어졌을 때, 콘 효과에 의한 게인 기여도를 계산하는 데 반드시 사용되어야 합니다:
function coneGain() { const sourceOrientation= new Vec3( source. orientationX, source. orientationY, source. orientationZ); if ( sourceOrientation. magnitude== 0 || (( source. coneInnerAngle== 360 ) && ( source. coneOuterAngle== 360 ))) return 1 ; // 콘이 지정되지 않으면 게인 1 // 정규화된 소스-리스너 벡터 const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceToListener= sourcePosition. diff( listenerPosition). normalize(); const normalizedSourceOrientation= sourceOrientation. normalize(); // 소스 방향 벡터와 소스-리스너 벡터 사이의 각도 const angle= 180 * Math. acos( sourceToListener. dot( normalizedSourceOrientation)) / Math. PI; const absAngle= Math. abs( angle); // API는 전체 각도(half-angle 아님)이므로 2로 나눔 const absInnerAngle= Math. abs( source. coneInnerAngle) / 2 ; const absOuterAngle= Math. abs( source. coneOuterAngle) / 2 ; let gain= 1 ; if ( absAngle<= absInnerAngle) { // 감쇠 없음 gain= 1 ; } else if ( absAngle>= absOuterAngle) { // 최대 감쇠 gain= source. coneOuterGain; } else { // 내부/외부 콘 사이 // inner -> outer, x는 0 -> 1 const x= ( absAngle- absInnerAngle) / ( absOuterAngle- absInnerAngle); gain= ( 1 - x) + source. coneOuterGain* x; } return gain; }
7. 성능 관련 사항(Performance Considerations)
7.1. 지연(Latency)
웹 애플리케이션에서는 마우스·키보드 이벤트(keydown, mousedown 등)와 소리가 들리는 사이의 시간 지연이 중요합니다.
이 시간 지연은 latency(지연)라고 하며, 여러 요인(입력 장치 지연, 내부 버퍼링 지연, DSP 처리 지연, 출력 장치 지연, 사용자 귀와 스피커 사이의 거리 등)의 누적 결과입니다. 이 latency가 클수록 사용자의 경험은 만족스럽지 않을 수 있습니다. 극단적으로는 음악 제작이나 게임 플레이가 불가능할 수도 있습니다. 적당한 수준에서도 타이밍에 영향을 주어 소리가 늦게 들리거나 게임이 반응이 느리다는 인상을 줄 수 있습니다. 음악 애플리케이션에서는 리듬이, 게임에서는 플레이의 정확도가 영향을 받습니다. 인터랙티브 애플리케이션에서는 매우 낮은 애니메이션 프레임 레이트와 비슷하게 사용자 경험의 품질을 떨어뜨립니다. 애플리케이션에 따라 합리적인 지연은 3-6ms ~ 25-50ms 정도일 수 있습니다.
구현체는 일반적으로 전체 latency를 최소화하려고 합니다.
전체 latency를 최소화하는 것과 함께, 구현체는 AudioContext의
currentTime과 AudioProcessingEvent의
playbackTime 차이도 최소화하려고 합니다.
ScriptProcessorNode의
폐기는 시간이 지나면서 이 문제를 덜 중요하게 만듭니다.
또한, 일부 AudioNode는
오디오 그래프 경로에 latency를 추가할 수 있습니다. 특히:
-
AudioWorkletNode는 내부 버퍼링을 하는 스크립트를 실행할 수 있어 신호 경로에 지연을 추가할 수 있습니다. -
DelayNode는 제어된 지연 시간을 추가하는 역할을 합니다. -
BiquadFilterNode와IIRFilterNode필터 설계는, 인과적 필터링 과정의 자연스러운 결과로 들어오는 샘플을 지연시킬 수 있습니다. -
ConvolverNode는 임펄스에 따라 컨볼루션 연산의 결과로 샘플을 지연시킬 수 있습니다. -
DynamicsCompressorNode는 look ahead 알고리즘을 사용하여 신호 경로에 지연을 유발합니다. -
MediaStreamAudioSourceNode,MediaStreamTrackAudioSourceNode,MediaStreamAudioDestinationNode는 구현에 따라 내부적으로 버퍼를 추가하여 지연을 유발할 수 있습니다. -
ScriptProcessorNode는 제어 스레드와 렌더링 스레드 사이에 버퍼를 가질 수 있습니다. -
WaveShaperNode는 오버샘플링 시, 오버샘플링 방식에 따라 신호 경로에 지연을 추가할 수 있습니다.
7.2. 오디오 버퍼 복사(Audio Buffer Copying)
acquire the content 작업이 AudioBuffer에서
수행될 때, 전체 작업은 일반적으로 채널 데이터를 복사하지 않고 구현할 수 있습니다. 특히 마지막 단계는 getChannelData()
호출 시 lazy하게 수행되어야 합니다.
즉, 중간에 getChannelData()
없이 연속적으로 acquire the content 작업(예: 동일
AudioBufferSourceNode
여러 개가 같은 AudioBuffer를
재생)을 수행하는 경우, 할당이나 복사 없이 구현할 수 있습니다.
구현체는 추가 최적화도 할 수 있습니다: getChannelData()가
AudioBuffer에서
호출되고, 새로운 ArrayBuffer가
아직 할당되지 않았지만, 이전 acquire the content
작업의 모든 호출자가 AudioBuffer의
데이터를 더 이상 사용하지 않는 경우, 원시 데이터 버퍼를 새로운 AudioBuffer에
재사용하여 채널 데이터의 재할당이나 복사를 피할 수 있습니다.
7.3. AudioParam 전이(AudioParam Transitions)
AudioParam의
value
속성을 직접 설정할 때는 자동 스무딩이 적용되지 않지만, 일부 파라미터에서는 값을 직접 설정하는 것보다 부드러운 전이가 바람직합니다.
setTargetAtTime()
메서드를 낮은 timeConstant와 함께 사용하면 부드러운 전이를 수행할 수 있습니다.
7.4. 오디오 글리치(Audio Glitching)
오디오 글리치는 정상적인 연속 오디오 스트림이 중단되어, 큰 클릭음이나 팝 노이즈가 나는 현상입니다. 이는 멀티미디어 시스템의 치명적 실패로 간주되며 반드시 방지해야 합니다. 오디오 스트림을 하드웨어에 전달하는 스레드에 문제가 있을 때(스레드가 적절한 우선순위나 시간 제약을 갖지 못해 스케줄링 지연이 발생하는 등) 발생할 수 있습니다. 또한, 오디오 DSP가 CPU의 속도에 비해 실시간으로 처리할 수 있는 작업량을 초과할 때도 발생할 수 있습니다.
8. 보안 및 개인정보 보호(Security and Privacy Considerations)
보안 및 개인정보 셀프 리뷰 질의서 § questions에 따라:
-
이 표준은 개인 식별 정보를 다루나요?
Web Audio API를 이용해 청력 테스트를 수행하여 한 사람이 들을 수 있는 주파수 범위를 알아낼 수 있습니다(나이가 들수록 감소합니다). 하지만 이는 사용자의 자각 및 동의 없이 이루어지기 어렵고, 적극적인 참여가 필요합니다.
-
이 표준은 고가치 데이터를 다루나요?
아니요. 신용카드 정보 등은 Web Audio에서 사용되지 않습니다. 음성 데이터를 처리하거나 분석하는 데 Web Audio를 사용할 수는 있지만, 이는 개인정보 문제가 될 수 있습니다. 하지만 사용자의 마이크 접근은
getUserMedia()를 통한 권한 기반입니다. -
이 표준은 출처(origin)에 대해 브라우징 세션 간 지속되는 새로운 상태를 도입하나요?
아니요. AudioWorklet은 브라우징 세션 간 지속되지 않습니다.
-
이 표준은 웹에 지속적이고 교차 출처 상태를 노출하나요?
네, 지원되는 오디오 샘플레이트와 출력 장치 채널 수가 노출됩니다.
AudioContext를 참고하세요. -
이 표준은 출처(origin)에 현재 접근권한이 없는 다른 데이터를 노출하나요?
네. 다양한
AudioNode정보를 제공할 때, Web Audio API는 클라이언트의 특징적 정보(예: 오디오 하드웨어 샘플레이트)를 API를 사용하는 모든 페이지에 노출할 수 있습니다. 또한,AnalyserNode또는ScriptProcessorNode인터페이스를 통해 타이밍 정보를 수집할 수 있습니다. 이 정보는 후에 클라이언트의 지문(fingerprint)을 만드는 데 사용될 수 있습니다.프린스턴 CITP의 Web Transparency and Accountability Project 연구에 따르면,
DynamicsCompressorNode와OscillatorNode를 사용해 클라이언트로부터 엔트로피를 수집하여 기기를 지문화할 수 있습니다. 이는 DSP 아키텍처, 리샘플링 방식, 반올림 처리의 미세한(대개 들리지 않는) 차이 때문입니다. 또한 컴파일러 플래그와 CPU 아키텍처(ARM vs x86)도 엔트로피에 기여합니다.실제로 이는 이미 더 쉬운 방법(사용자 에이전트 문자열 등)으로 쉽게 추론할 수 있는 정보를 얻는 것에 불과합니다(예: "이 브라우저 X가 플랫폼 Y에서 실행 중"). 하지만 추가 지문화 가능성을 줄이기 위해, 브라우저는 모든 노드의 출력에서 발생할 수 있는 지문화 문제를 완화해야 합니다.
클럭 스큐(skew) 기반 지문화는 Steven J Murdoch와 Sebastian Zander에 의해 기술되었으며,
getOutputTimestamp에서 이를 판별할 수 있습니다. 스큐 기반 지문화는 Nakibly 등 HTML에 대해에서도 입증되었습니다. 고해상도 시간(High Resolution Time) § 10. 개인정보 보호 고려사항을 참고하세요.latency(지연) 기반 지문화도 가능합니다;
baseLatency와outputLatency에서 추론할 수 있습니다. 완화 방안으로는 지터(jitter, 디더링)나 양자화(quantization)를 추가해 정확한 스큐가 잘못 보고되도록 하는 방법이 있습니다. 하지만 대부분의 오디오 시스템은 저지연(low latency)을 목표로 하므로, WebAudio가 생성한 오디오를 다른 오디오·비디오 소스 또는 시각적 신호(게임, 오디오 녹음, 음악 제작 환경 등)와 동기화할 때 필요합니다. 지나치게 높은 지연은 사용성을 떨어뜨리고 접근성 문제를 유발할 수 있습니다.AudioContext의 샘플레이트로도 지문화가 가능합니다. 이를 최소화하기 위해 다음을 권장합니다:-
기본값으로 44.1kHz와 48kHz만 허용하며, 시스템에서 가장 적합한 값을 선택합니다(예: 오디오 장치가 44.1kHz라면 44.1, 시스템이 96kHz라면 48kHz가 선택될 수 있음).
-
장치가 다른 샘플레이트일 경우, 시스템은 두 값 중 하나로 리샘플링해야 하며, 이는 배터리 소모가 증가할 수 있습니다(예: 시스템이 16kHz면 48kHz로 선택됨).
-
브라우저에서 네이티브 레이트를 강제로 사용할 수 있는 설정(예: 브라우저 플래그 등)을 제공해야 하며, 이 설정은 API에 노출되지 않습니다.
-
AudioContext생성자에서 명시적으로 다른 샘플레이트를 요청할 수 있습니다(현행 표준에 이미 있음). 이 경우 렌더링은 요청된 샘플레이트로 진행된 후, 장치 출력에 맞게 업/다운 샘플링됩니다. 만약 그 샘플레이트가 네이티브로 지원된다면, 렌더링 결과가 바로 출력될 수도 있습니다(예:MediaDevices의 capabilities를 읽어(사용자 동의 필요) 더 높은 레이트가 지원되는지 확인).
AudioContext의 출력 채널 수로도 지문화가 가능합니다.maxChannelCount를 2(스테레오)로 설정하는 것을 권장합니다. 스테레오가 압도적으로 일반적입니다. -
-
이 표준은 새로운 스크립트 실행/로딩 메커니즘을 허용하나요?
아니요. 이 표준은 [HTML]에서 정의된 스크립트 실행 방식을 사용합니다.
-
이 표준은 출처(origin)가 사용자의 위치에 접근할 수 있게 허용하나요?
아니요.
-
이 표준은 출처(origin)가 사용자의 기기 센서에 접근할 수 있게 허용하나요?
직접적으로는 아닙니다. 현재 오디오 입력은 본 문서에서 명시되지 않았지만, 클라이언트 머신의 오디오 입력/마이크 접근을 포함할 것이며, 적절한 방식으로(아마
getUserMedia()API를 통해) 사용자에게 권한을 요청해야 합니다.또한, Media Capture and Streams 표준의 보안 및 개인정보 보호 고려사항도 참고해야 합니다. 특히, 주변 오디오 분석이나 고유한 오디오 재생은 사용자의 위치를 방(room) 수준까지, 심지어 서로 다른 사용자가 같은 방에 있는지까지 식별할 수 있게 할 수 있습니다. 오디오 출력·입력 모두 접근할 수 있다면, 브라우저 내에서 분리된 컨텍스트들끼리 통신이 가능해질 수도 있습니다.
-
이 표준은 출처(origin)가 사용자의 로컬 컴퓨팅 환경의 측면에 접근할 수 있게 허용하나요?
직접적으로는 아닙니다; 요청된 모든 샘플레이트가 지원되며, 필요시 업샘플링됩니다. Media Capture and Streams를 통해 MediaTrackSupportedConstraints로 지원되는 오디오 샘플레이트를 프로브할 수 있습니다. 이때 명시적인 사용자 동의가 필요합니다. 이는 약간의 지문화가 가능하게 합니다. 하지만 실제로 대부분의 일반/준전문가용 기기는 두 표준 샘플레이트(44.1kHz, 48kHz)를 사용합니다. 자원이 매우 제한된 기기는 음성 품질의 11kHz, 고급 기기는 88.2, 96, 192kHz까지 지원할 수 있습니다.
모든 구현체에 대해 단일 공통 샘플레이트(예: 48kHz)로 업샘플링을 요구하면, 특별한 이점 없이 CPU 사용량만 늘어납니다. 고급 기기에 낮은 레이트만 쓰게 하면 Web Audio가 전문가용으로 부적합하다고 평가받을 수 있습니다.
-
이 표준은 출처(origin)가 다른 기기에 접근할 수 있게 허용하나요?
일반적으로는 다른 네트워크 기기에 접근하지 않습니다(고급 녹음 스튜디오의 Dante 네트워크 기기는 예외일 수 있으나, 별도의 전용 네트워크를 사용함). 사용자의 오디오 출력 장치에 접근은 필요에 따라 허용되며, 이는 종종 컴퓨터와 별도의 장치일 수 있습니다.
음성·소리 동작 기기에서는 Web Audio API가 다른 기기를 제어하는 데 쓰일 수 있습니다. 또한 소리 작동 기기가 초음파 근처 주파수에 민감하다면, 제어 신호가 들리지 않을 수도 있습니다. HTML에서도 <audio>, <video> 요소를 통해 그런 가능성이 있습니다. 일반적인 오디오 샘플링 레이트에서는 초음파 정보에 충분한 헤드룸이 없습니다:
인간의 청력 한계는 보통 20kHz로 말합니다. 44.1kHz 샘플링 레이트에서는 나이퀴스트 한계가 22.05kHz입니다. 실제로 브릭월(brickwall) 필터는 물리적으로 구현할 수 없으므로, 20kHz~22.05kHz 사이 공간은 급격한 롤오프 필터로 사용되어 나이퀴스트 이상 모든 주파수를 강하게 감쇠합니다.
48kHz 샘플링 레이트에서는 20kHz~24kHz에서도 급격한 감쇠가 있으며(패스밴드의 위상 리플 오류를 피하기 쉽습니다).
-
이 표준은 출처(origin)가 사용자 에이전트의 네이티브 UI의 측면을 제어할 수 있게 허용하나요?
UI에 오디오 컴포넌트(음성 비서, 화면읽기 등)가 있다면, Web Audio API를 써서 네이티브 UI의 일부를 흉내내 공격이 로컬 시스템 이벤트처럼 보이게 할 수 있습니다. HTML의 <audio> 요소로도 가능합니다.
-
이 표준은 웹에 임시 식별자를 노출하나요?
아니요.
-
이 표준은 1st-party와 3rd-party 컨텍스트에서 동작을 구분하나요?
아니요.
-
이 표준은 사용자 에이전트의 "시크릿 모드"에서 어떻게 동작해야 하나요?
동일하게 동작해야 합니다.
-
이 표준은 사용자 로컬 기기에 데이터를 영구 저장하나요?
아니요.
-
이 표준은 "보안 고려사항(Security Considerations)" 및 "개인정보 보호 고려사항(Privacy Considerations)" 섹션을 포함하나요?
네(이 문서가 해당 내용입니다).
-
이 표준은 기본 보안 특성을 다운그레이드할 수 있나요?
아니요.
9. 요구사항 및 사용 사례(Requirements and Use Cases)
[webaudio-usecases]를 참고하세요.
10. 명세 코드의 공통 정의(Common Definitions for Specification Code)
이 섹션에서는 명세 내 JavaScript 코드에서 사용하는 공통 함수와 클래스를 설명합니다.
// 3차원 벡터 클래스 class Vec3{ // 3좌표로 생성 constructor ( x, y, z) { this . x= x; this . y= y; this . z= z; } // 다른 벡터와 내적(Dot product) dot( v) { return ( this . x* v. x) + ( this . y* v. y) + ( this . z* v. z); } // 다른 벡터와 외적(Cross product) cross( v) { return new Vec3(( this . y* v. z) - ( this . z* v. y), ( this . z* v. x) - ( this . x* v. z), ( this . x* v. y) - ( this . y* v. x)); } // 다른 벡터와의 차(Difference) diff( v) { return new Vec3( this . x- v. x, this . y- v. y, this . z- v. z); } // 벡터의 크기(Magnitude) get magnitude() { return Math. sqrt( dot( this )); } // 스칼라 곱(Scale by scalar) scale( s) { return new Vec3( this . x* s, this . y* s, this . z* s); } // 정규화(Normalize) normalize() { const m= magnitude; if ( m== 0 ) { return new Vec3( 0 , 0 , 0 ); } return scale( 1 / m); } }
11. 변경 로그(Change Log)
12. 감사의 글(Acknowledgements)
이 명세는 W3C Audio Working Group의 공동 작업입니다.
워킹 그룹의 멤버·전 멤버 및 기여자(작성 당시 알파벳 순)는 다음과 같습니다:
Adenot, Paul (Mozilla Foundation) - Specification Co-editor;
Akhgari, Ehsan (Mozilla Foundation);
Becker, Steven (Microsoft Corporation);
Berkovitz, Joe (Invited Expert, affiliated with Noteflight/Hal Leonard) - WG co-chair from September 2013 to
December 2017);
Bossart, Pierre (Intel Corporation);
Borins, Myles (Google, Inc);
Buffa, Michel (NSAU);
Caceres, Marcos (Invited Expert);
Cardoso, Gabriel (INRIA);
Carlson, Eric (Apple, Inc);
Chen, Bin (Baidu, Inc);
Choi, Hongchan (Google, Inc) - Specification Co-editor;
Collichio, Lisa (Qualcomm);
Geelnard, Marcus (Opera Software);
Gehring, Todd (Dolby Laboratories);
Goode, Adam (Google, Inc);
Gregan, Matthew (Mozilla Foundation);
Hikawa, Kazuo (AMEI);
Hofmann, Bill (Dolby Laboratories);
Jägenstedt, Philip (Google, Inc);
Jeong, Paul Changjin (HTML5 Converged Technology Forum);
Kalliokoski, Jussi (Invited Expert);
Lee, WonSuk (Electronics and Telecommunications Research Institute);
Kakishita, Masahiro (AMEI);
Kawai, Ryoya (AMEI);
Kostiainen, Anssi (Intel Corporation);
Lilley, Chris (W3C Staff);
Lowis, Chris (Invited Expert) - WG co-chair from December 2012 to September 2013, affiliated with British
Broadcasting Corporation;
MacDonald, Alistair (W3C Invited Experts) — WG co-chair from March 2011 to July 2012;
Mandyam, Giridhar (Qualcomm Innovation Center, Inc);
Michel, Thierry (W3C/ERCIM);
Nair, Varun (Facebook);
Needham, Chris (British Broadcasting Corporation);
Noble, Jer (Apple, Inc);
O’Callahan, Robert(Mozilla Foundation);
Onumonu, Anthony (British Broadcasting Corporation);
Paradis, Matthew (British Broadcasting Corporation) - WG co-chair from September 2013 to present;
Pozdnyakov, Mikhail (Intel Corporation);
Raman, T.V. (Google, Inc);
Rogers, Chris (Google, Inc);
Schepers, Doug (W3C/MIT);
Schmitz, Alexander (JS Foundation);
Shires, Glen (Google, Inc);
Smith, Jerry (Microsoft Corporation);
Smith, Michael (W3C/Keio);
Thereaux, Olivier (British Broadcasting Corporation);
Toy, Raymond (Google, Inc.) - WG co-chair from December 2017 - Present;
Toyoshima, Takashi (Google, Inc);
Troncy, Raphael (Institut Telecom);
Verdie, Jean-Charles (MStar Semiconductor, Inc.);
Wei, James (Intel Corporation);
Weitnauer, Michael (IRT);
Wilson, Chris (Google,Inc);
Zergaoui, Mohamed (INNOVIMAX)