1. 소개
이 섹션은 비규범적입니다.
웹 스피치 API는 웹 브라우저에서 일반적인 음성 인식 또는 스크린 리더 소프트웨어를 사용할 때 일반적으로 제공되지 않는 음성 입력 및 텍스트-투-스피치 출력 기능을 웹 개발자가 제공할 수 있도록 하는 것을 목표로 합니다. API 자체는 기본 음성 인식 및 합성 구현에 대해 중립적이며 서버 기반 및 클라이언트 기반/내장형 인식과 합성 모두를 지원할 수 있습니다. 이 API는 짧은(원샷) 음성 입력과 연속적인 음성 입력을 모두 가능하게 하도록 설계되었습니다. 음성 인식 결과는 각 가설에 대한 기타 관련 정보와 함께 가설 목록으로 웹 페이지에 제공됩니다.
이 명세는 HTML Speech Incubator Group Final Report에 정의된 API의 부분집합입니다. 해당 보고서는 표준화 문서가 아니므로 전적으로 정보 제공용입니다. 그 보고서의 모든 부분은 이 문서와 관련하여 정보 참고 자료로 간주될 수 있으며, 이 문서에 대한 배경 설명을 제공합니다. 이 명세는 해당 보고서의 완전 기능 부분집합입니다. 구체적으로, 이 부분집합은 기본 전송 프로토콜과 제안된 HTML 마크업 추가를 제외하고, 자바스크립트 API의 단순화된 부분집합을 정의합니다. 이 부분집합은 Incubator Group Final Report의 대부분의 사용 사례와 샘플 코드를 지원합니다. 이 부분집합은 향후 마크업, API 또는 기본 전송 프로토콜에 대한 추가 표준화를 배제하지 않으며, 실제로 Incubator 보고서는 향후 작업을 위한 잠재적 로드맵을 정의합니다.
2. 사용 사례
이 섹션은 비규범적입니다.
이 명세는 Incubator Report의 섹션 4에 정의된 다음 사용 사례를 지원합니다.
- 음성 웹 검색
- 음성 명령 인터페이스
- 개방형 대화의 연속 인식
- 시각적 UI가 필요하지 않을 때 동작하는 음성 UI
- 음성 활동 감지
- 시각적 피드백을 제공하기 위한 합성의 시간적 구조
- 헬로 월드
- 음성 번역
- 음성 지원 이메일 클라이언트
- 대화형 시스템
- 다중 모달 상호작용
- 음성 기반 운전 안내
- 다중 모달 비디오 게임
- 다중 모달 검색
API를 최소화하기 위해, 이 명세는 다음 사용 사례를 직접적으로 지원하지 않습니다. 이는 향후 API 확장으로 지원을 추가하는 것을 배제하지 않으며, 실제로 Incubator 보고서는 이를 위한 로드맵을 제공합니다.
- 재인식
3. 보안 및 개인정보 보호 고려사항
-
사용자 에이전트는 명시적이고 충분히 설명된 사용자 동의가 있을 때만 음성 입력 세션을 시작해야 합니다.
사용자 동의는 예를 들어 다음을 포함할 수 있습니다:
- 명확한 그래픽 표시로 음성 입력을 시작함을 보여주는 가시적 음성 입력 요소에 사용자가 클릭하는 경우
start()호출의 결과로 표시되는 권한 프롬프트를 수락하는 경우- 이 웹 페이지에 대해 항상 음성 입력을 허용하도록 이전에 부여된 동의
-
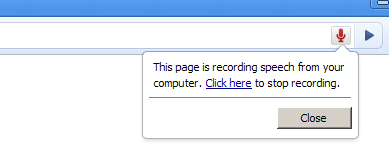
사용자 에이전트는 오디오가 녹음되고 있을 때 사용자에게 명확한 표시를 제공해야 합니다.
- 그래픽 사용자 에이전트에서는 이것이 브라우저 크롬의 일부로 사용자 에이전트가 표시하는 필수 알림이고 웹 페이지에서 접근할 수 없어야 합니다.
예를 들어 브라우저 크롬/주소 표시줄의 맥동/깜박이는 녹음 아이콘, 상태 표시줄의 표시, 음성 알림 등 사용자에게 관련 있고 접근 가능한 어떤 것이 될 수 있습니다.
이 UI 요소는 또한 사용자가 녹음을 중지할 수 있도록 해야 합니다.
- 음성 전용 사용자 에이전트에서는 표시가 예를 들어 음성 입력 요소의 레이블을 시스템이 말한 다음 짧은 삑 소리를 내는 형태일 수 있습니다.
- 그래픽 사용자 에이전트에서는 이것이 브라우저 크롬의 일부로 사용자 에이전트가 표시하는 필수 알림이고 웹 페이지에서 접근할 수 없어야 합니다.
예를 들어 브라우저 크롬/주소 표시줄의 맥동/깜박이는 녹음 아이콘, 상태 표시줄의 표시, 음성 알림 등 사용자에게 관련 있고 접근 가능한 어떤 것이 될 수 있습니다.
이 UI 요소는 또한 사용자가 녹음을 중지할 수 있도록 해야 합니다.
- 사용자 에이전트는 또한 처음으로 음성 입력이 사용될 때 사용자가 그것이 무엇인지, 필요할 경우 음성 녹음을 비활성화하기 위해 개인 정보 설정을 어떻게 조정할 수 있는지 알려주기 위한 보다 긴 설명을 제공할 수 있습니다.
- 핑거프린팅 위험을 완화하기 위해, 사용자 에이전트는
MediaStreamTrack에서 음성 인식을 수행할 때 음성 인식을 개인화해서는 안됩니다.
3.1. 구현 시 고려사항
이 섹션은 비규범적입니다.
- 말로 입력하는 비밀번호는 보안 관점에서 문제가 될 수 있지만, 비밀번호를 말할지 여부는 사용자 스스로 결정할 문제입니다.
- 음성 입력은 잠재적으로 사용자를 도청하는 데 사용될 수 있습니다. 악의적인 웹페이지는 입력 요소를 숨기거나 녹음을 중지한 것처럼 사용자에게 믿게 만들면서 계속해서 녹음하도록 하는 등의 속임수를 사용할 수 있습니다. 또한 입력 요소를 다른 것으로 보이도록 스타일링하여 사용자를 속여 클릭하게 할 수도 있습니다. 파일 입력 요소를 스타일링한 예는 https://www.quirksmode.org/dom/inputfile.html에서 볼 수 있습니다. 위의 권고 사항은 이러한 공격 위험을 줄이기 위한 것입니다.
4. API 설명
이 섹션은 규범적입니다.
4.1. SpeechRecognition 인터페이스
음성 인식 인터페이스는 주어진 인식을 제어하기 위한 스크립트 가능한 웹 API입니다.
The term "final result" indicates aSpeechRecognitionResult
in which the isFinal
attribute is true.
The term "interim result" indicates a SpeechRecognitionResult
in which the isFinal
attribute is false.
SpeechRecognition
has the following internal slots:
[[started]]-
음성 인식이 시작되었는지를 나타내는 불리언 플래그입니다. 초기 값은
false입니다.
[[processLocally]]-
인식이 로컬에서 수행되어야 하는지를 나타내는 불리언 플래그로, MUST로 로컬에서 수행되어야 함을 나타냅니다. 초기 값은
false입니다.
[[phrases]]-
컨텍스트 바이어싱을 위한 구문 목록을 나타내는
ObservableArray형식의SpeechRecognitionPhrase객체들입니다. 초기 값은 새로운 빈ObservableArray입니다.
[SecureContext ,Exposed =Window ]interface :SpeechRecognition EventTarget {(); // recognition parametersconstructor attribute SpeechGrammarList grammars ;attribute DOMString lang ;attribute boolean continuous ;attribute boolean interimResults ;attribute unsigned long maxAlternatives ;attribute boolean processLocally ;attribute ObservableArray <SpeechRecognitionPhrase >phrases ; // methods to drive the speech interactionundefined start ();undefined start (MediaStreamTrack );audioTrack undefined stop ();undefined abort ();static Promise <AvailabilityStatus >available (SpeechRecognitionOptions );options static Promise <boolean >install (SpeechRecognitionOptions ); // event methodsoptions attribute EventHandler ;onaudiostart attribute EventHandler ;onsoundstart attribute EventHandler ;onspeechstart attribute EventHandler ;onspeechend attribute EventHandler ;onsoundend attribute EventHandler ;onaudioend attribute EventHandler ;onresult attribute EventHandler ;onnomatch attribute EventHandler ;onerror attribute EventHandler ;onstart attribute EventHandler ; };onend dictionary {SpeechRecognitionOptions required sequence <DOMString >;langs boolean =processLocally false ; };enum {SpeechRecognitionErrorCode "no-speech" ,"aborted" ,"audio-capture" ,"network" ,"not-allowed" ,"service-not-allowed" ,"language-not-supported" ,"phrases-not-supported" };enum {AvailabilityStatus "unavailable" ,"downloadable" ,"downloading" ,"available" }; [SecureContext ,Exposed =Window ]interface :SpeechRecognitionErrorEvent Event {(constructor DOMString ,type SpeechRecognitionErrorEventInit );eventInitDict readonly attribute SpeechRecognitionErrorCode error ;readonly attribute DOMString message ; };dictionary :SpeechRecognitionErrorEventInit EventInit {required SpeechRecognitionErrorCode ;error DOMString = ""; }; // Item in N-best list [message SecureContext ,Exposed =Window ]interface {SpeechRecognitionAlternative readonly attribute DOMString transcript ;readonly attribute float confidence ; }; // A complete one-shot simple response [SecureContext ,Exposed =Window ]interface {SpeechRecognitionResult readonly attribute unsigned long length ;getter SpeechRecognitionAlternative item (unsigned long );index readonly attribute boolean isFinal ; }; // A collection of responses (used in continuous mode) [SecureContext ,Exposed =Window ]interface {SpeechRecognitionResultList readonly attribute unsigned long length ;getter SpeechRecognitionResult item (unsigned long ); }; // A full response, which could be interim or final, part of a continuous response or not [index SecureContext ,Exposed =Window ]interface :SpeechRecognitionEvent Event {(constructor DOMString ,type SpeechRecognitionEventInit );eventInitDict readonly attribute unsigned long resultIndex ;readonly attribute SpeechRecognitionResultList results ; };dictionary :SpeechRecognitionEventInit EventInit {unsigned long = 0;resultIndex required SpeechRecognitionResultList ; }; // The object representing a speech grammar. This interface has been deprecated and exists in this spec for the sole purpose of maintaining backwards compatibility. [results Exposed =Window ]interface {SpeechGrammar attribute DOMString src ;attribute float weight ; }; // The object representing a speech grammar collection. This interface has been deprecated and exists in this spec for the sole purpose of maintaining backwards compatibility. [Exposed =Window ]interface {SpeechGrammarList ();constructor readonly attribute unsigned long length ;getter SpeechGrammar item (unsigned long );index undefined addFromURI (DOMString ,src optional float = 1.0);weight undefined addFromString (DOMString ,string optional float = 1.0); }; // The object representing a phrase for contextual biasing. [weight SecureContext ,Exposed =Window ]interface {SpeechRecognitionPhrase constructor (DOMString ,phrase optional float = 1.0);boost readonly attribute DOMString phrase ;readonly attribute float boost ; };
4.1.1. SpeechRecognition 속성
grammarsattribute, of type SpeechGrammarList- grammars 속성은 이 인식에 대해 활성화된 문법을 나타내는 SpeechGrammar 객체들의 컬렉션을 저장합니다. 이 속성은 아무 동작도 하지 않으며 이 명세에 존재하는 것은 이전 호환성을 유지하기 위한 유일한 목적입니다.
langattribute, of type DOMString- 이 속성은 유효한 BCP 47 언어 태그를 사용하여 요청의 인식 언어를 설정합니다. [BCP47] 설정되지 않은 경우 스크립트에서 가져올 때 unset 상태로 남지만, 기본적으로 html 문서 루트 요소 및 관련 계층의 언어를 사용하도록 기본값이 적용됩니다. 이 기본값은 입력 요청이 인식 서비스에 연결을 열 때 계산되어 사용됩니다.
continuousattribute, of type boolean- continuous 속성이 false로 설정되면, 사용자 에이전트는 인식 시작에 대한 응답으로 하나의 최종 결과를 초과하여 반환해서는 안됩니다. 예를 들어 단일 턴 상호작용 패턴의 경우입니다. continuous 속성이 true로 설정되면, 사용자 에이전트는 인식 시작에 대한 응답으로 여러 연속 인식을 나타내는 0개 이상의 최종 결과를 반환해야 합니다. 예를 들어 받아쓰기의 경우입니다. 기본값은 false여야 합니다. 이 속성 설정은 임시 결과(interim results)에는 영향을 주지 않습니다.
interimResultsattribute, of type boolean- 임시 결과가 반환되는지 여부를 제어합니다. true로 설정되면 임시 결과가 반환되어야 합니다. false로 설정되면 임시 결과는 반환되어서는 안 됩니다. 기본값은 false여야 합니다. 이 속성 설정은 최종 결과에는 영향을 주지 않습니다.
maxAlternativesattribute, of type unsigned long- 이 속성은 결과당 반환될 수 있는
SpeechRecognitionAlternative의 최대 개수를 설정합니다. 기본값은 1입니다. processLocallyattribute, of type boolean- 이 속성이 true로 설정되면 음성 인식 프로세스가 사용자의 장치에서 로컬로 수행되어야 함을 요구합니다(MUST). false로 설정되면 사용자 에이전트는 로컬 처리와 원격 처리 사이에서 선택할 수 있습니다. 기본값은 false입니다.
phrasesattribute, of type ObservableArray<SpeechRecognitionPhrase>-
phrases속성은 컨텍스트 바이어싱에 사용될SpeechRecognitionPhrase객체들의 목록을 제공합니다. 이것은ObservableArray로, JavaScriptArray처럼 수정할 수 있습니다(예:push()사용).- getter 동작은
[[phrases]]의 값을 반환하는 것입니다. - getter 동작은
그룹은 WebRTC가 오디오 소스 선택 및 원격 인식기 지정에 사용될 수 있는지 여부를 논의했습니다. 관련 스레드는 Interacting with WebRTC, the Web Audio API and other external sources입니다.
4.1.2. SpeechRecognition 메서드
start()method-
장치의 마이크로폰에서 직접 음성 인식 프로세스를 시작합니다.
호출되면 다음 단계를 실행합니다:
-
requestMicrophonePermission이라는 불리언 변수를
true로 설정합니다. -
start session algorithm을 requestMicrophonePermission과 함께 실행합니다.
-
start(methodMediaStreamTrackaudioTrack)-
MediaStreamTrack를 사용하여 음성 인식 프로세스를 시작합니다. 호출되면 다음 단계를 실행합니다:-
audioTrack을 첫 번째 인수로 둡니다.
-
만약 audioTrack의
kind속성이"audio"가 아니면,InvalidStateError를 던지고 이 단계를 중단합니다. -
만약 audioTrack의
readyState속성이"live"가 아니면,InvalidStateError를 던지고 이 단계를 중단합니다. -
requestMicrophonePermission을
false로 설정합니다. -
start session algorithm을 requestMicrophonePermission과 함께 실행합니다.
-
stop()method- stop 메서드는 인식 서비스에 더 많은 오디오를 듣는 것을 중단하고, 이미 이 인식을 위해 수집한 오디오만으로 결과를 반환하려고 시도하라는 지시를 나타냅니다. 일반적인 사용 예는 최종 사용자가 끝을 가리키는 동작을 하는 경우(예: 워키토키와 유사)입니다. 최종 사용자가 말하기 위해 스페이스 바를 누르고 있는 동안 start가 호출되고, 스페이스 바를 놓으면 stop이 호출되어 시스템이 더 이상 사용자를 듣지 않도록 할 수 있습니다. stop이 호출된 이후 음성 서비스는 추가 오디오를 수집해서는 안 되며 사용자를 계속해서 들어서는 안 됩니다. 음성 서비스는 이 인식을 위해 이미 수집한 오디오를 기반으로 인식 결과(또는 nomatch)를 반환하려고 시도해야 합니다. 만약 start가 결코 호출되지 않았거나 end 또는 error 이벤트가 이미 발생했거나 이전에 stop이 호출된 객체에 대해 stop이 호출되면, 사용자 에이전트는 그 호출을 무시해야 합니다.
abort()method- abort 메서드는 즉시 듣기와 인식을 중지하고 어떠한 정보도 반환하지 않도록 요청하는 것입니다. abort가 호출되면 음성 서비스는 인식을 중지해야 합니다. 사용자 에이전트는 음성 서비스가 더 이상 연결되어 있지 않을 때 end 이벤트를 발생시켜야 합니다. 만약 start가 결코 호출되지 않았거나 end 또는 error 이벤트가 이미 발생했거나 이전에 abort가 호출된 객체에 대해 abort가 호출되면, 사용자 에이전트는 그 호출을 무시해야 합니다.
available(methodSpeechRecognitionOptionsoptions)-
available메서드는Promise를 반환하며, 이 Promise는AvailabilityStatus로 해결되어SpeechRecognitionOptions인수와 일치하는 인식 가능 상태를 나타냅니다. 이 메서드에 대한 접근은 "on-device-speech-recognition"라는 policy-controlled feature로 제어되며, 이 기능의 기본 허용 목록은'self'입니다.호출되면 다음 단계를 실행합니다:
-
promise를 새로운 프라미스로 둡니다.
-
availability algorithm을 options와 promise로 실행합니다. 만약 그것이 예외를 반환하면, 예외를 던지고 이 단계를 중단합니다.
-
promise를 반환합니다.
-
install(methodSpeechRecognitionOptionsoptions)-
install메서드는options.langs에 지정된 모든 언어에 대해 온-디바이스 음성 인식 언어 팩을 설치하려고 시도합니다. 이 메서드는Promise를 반환하며, 그 Promise는boolean로 해결됩니다. 요청된 및 지원되는 언어에 대한 모든 설치 시도가 성공했거나(또는 언어가 이미 설치되어 있는 경우) 프라미스는true로 해결됩니다.options.langs가 비어 있거나 요청된 모든 언어가 지원되지 않거나 지원되는 언어에 대한 어떤 설치 시도라도 실패하면 프라미스는false로 해결됩니다. 이 메서드에 대한 접근은 "on-device-speech-recognition"라는 policy-controlled feature로 제어되며, 이 기능의 기본 허용 목록은'self'입니다.호출되면 다음 단계를 실행합니다:
-
만약 current settings object의 relevant global object의 associated Document가 fully active가 아니라면,
InvalidStateError를 던지고 이 단계를 중단합니다. -
만약 options의
langs에 있는 어떤 lang이 유효한 [BCP47] 언어 태그가 아니면,SyntaxError를 던지고 이 단계를 중단합니다. -
만약 options의
langs에 있는 어떤 lang에 대해 온-디바이스 음성 인식 언어 팩이 지원되지 않으면,Promise를 false로 해결한 상태로 반환하고 나머지 단계는 건너뜁니다. -
promise를 새로운 프라미스로 둡니다.
-
options의
langs에 있는 각 lang에 대해 해당 언어의 온-디바이스 음성 인식 언어 다운로드를 시작합니다.참고: 사용자 에이전트는 온-디바이스 음성 인식 언어 팩을 다운로드하기 위해 사용자에게 명시적 권한을 요청할 수 있습니다.
-
Queue a task를 관련 전역 객체의 relevant global object의 task queue에 등록하여 다음 단계를 실행합니다:
-
options의
langs에 지정된 모든 언어의 다운로드가 성공하면 promise를true로 해결하고, 그렇지 않으면false로 해결합니다.참고: Promise의
false해결은 실패의 구체적 원인을 나타내지 않습니다. 사용자 에이전트는 개발자 도구 콘솔 메시지에 실패에 대한 보다 자세한 정보를 제공하는 것이 권장됩니다. 그러나 이 상세 오류 정보는 스크립트에 노출되지 않습니다.
-
-
promise를 반환합니다.
processLocally값은 이 알고리즘에서 사용되지 않습니다.
-
4.1.3. AvailabilityStatus Enum 값
AvailabilityStatus
enum은 음성 인식 기능의 사용 가능 상태를 나타냅니다. 값은 다음과 같습니다:
"unavailable"- 지정한 언어 및 처리 선호도에 대해 음성 인식을 사용할 수 없음을 나타냅니다.
processLocally가 options에서true인 경우, 이는 해당 언어의 온-디바이스 인식을 사용자 에이전트가 지원하지 않음을 의미합니다.processLocally가 options에서false인 경우, 이는 지정한 언어 중 적어도 하나에 대해 로컬/원격 인식 모두 사용할 수 없음을 의미합니다. "downloadable"- 지정한 언어의 온-디바이스 음성 인식을 사용자 에이전트가 지원하지만 현재 설치되어 있지 않음을 나타냅니다.
install()메서드를 사용하여 설치할 수 있습니다. 이 상태는 보통processLocally가 true일 때 관련이 있습니다. "downloading"- 지정한 언어의 온-디바이스 음성 인식이 현재 다운로드되고 있음을 나타냅니다. 이 상태는 보통
processLocally가 true일 때 관련이 있습니다. "available"- 모든 지정된 언어 및 주어진 처리 선호도에 대해 음성 인식을 사용할 수 있음을 나타냅니다.
processLocally가 true이면, 온-디바이스 인식이 설치되어 사용 준비가 된 상태를 의미합니다.processLocally가 false이면, (로컬 또는 원격일 수 있는) 인식을 사용할 수 있음을 의미합니다.
availability algorithm에 options와 promise가 전달되면, 사용자 에이전트는 다음 단계를 실행해야 합니다:
-
current settings object의 relevant global object의 associated Document가 fully active가 아니면,
InvalidStateError를 던지고 중단합니다. -
langs를 options의
langs로 둡니다. -
langs에 있는 어떤 lang이라도 [BCP47] 유효한 언어 태그가 아니면
SyntaxError를 던지고, 중단합니다. -
processLocally가 options에서false일 때:-
langs가 빈 시퀀스면, status를
unavailable로 둡니다. -
그렇지 않고 langs의 모든 language에 대해 음성 인식(원격 가능)이 가능하면, status를
available로 둡니다. -
그 밖에는 status를
unavailable로 둡니다.
-
-
processLocally가 options에서true일 때:- langs가 빈 시퀀스면 status를
unavailable로 둡니다. -
그 외의 경우:
- finalStatus를
available로 둡니다. -
langs의 각 language에 대해서:
- currentLanguageStatus를 둡니다.
- language에 대해 온-디바이스 음성 인식이 설치되어 있으면 currentLanguageStatus를
available로 둡니다. - 그렇지 않고 language에 대해 온-디바이스 음성 인식이 현재 다운로드 중이면
currentLanguageStatus를
downloading로 둡니다. - 그렇지 않고 language에 대해 온-디바이스 음성 인식을 사용자 에이전트가 지원하지만 아직 설치되지 않았다면
currentLanguageStatus를
downloadable로 둡니다. - 그 밖에는(language의 온-디바이스 인식을 지원하지 않으면)
currentLanguageStatus를
unavailable로 둡니다. - currentLanguageStatus가 finalStatus보다 아래 순위에 있다면,
[{{AvailabilityStatus/available}}, {{AvailabilityStatus/downloading}}, {{AvailabilityStatus/downloadable}}, {{AvailabilityStatus/unavailable}}]finalStatus를 currentLanguageStatus로 변경합니다.
- status를 finalStatus로 둡니다.
- finalStatus를
- langs가 빈 시퀀스면 status를
-
Queue a task를 relevant global object의 task queue에 등록하여 다음 단계를 실행합니다:
-
promise를 status로 resolve합니다.
-
start session algorithm이 requestMicrophonePermission과 함께 호출되면, 사용자 에이전트는 다음 단계를 실행해야 합니다:
-
current settings object의 relevant global object의 associated Document가 fully active가 아니면
InvalidStateError를 던지고 중단합니다. -
[[started]]가true이고 아직 error 또는 end 이벤트가 발생하지 않은 경우,InvalidStateError를 던지고 중단합니다. -
this.
phrases의length가 0보다 크고 사용자 에이전트가 컨텍스트 바이어싱을 지원하지 않으면:-
Queue a task로 다음 이벤트 발생. 이름은 error, 타겟은 this, 타입은
SpeechRecognitionErrorEvent이며,error속성은phrases-not-supported로 초기화,message속성은 사유를 나타내는 구현 정의 문자열로 설정합니다. -
이 단계를 중단합니다.
-
-
this.
[[processLocally]]가true이면:-
사용자 에이전트가 this.
lang에 대해 로컬 음성 인식이 불가능하거나, 로컬 처리를 충족할 수 없는 경우:-
Queue a task로 다음 이벤트 발생. 이름은 error, 타겟은 this, 타입은
SpeechRecognitionErrorEvent이며,error속성은service-not-allowed로 초기화,message속성은 사유를 나타내는 구현 정의 문자열로 설정합니다. -
이 단계를 중단합니다.
-
-
-
[[started]]를true로 설정합니다. -
requestMicrophonePermission이
true이고 request permission to use "microphone"이 "denied"인 경우:-
Queue a task로 다음 이벤트 발생. 이름은 error, 타겟은 this, 타입은
SpeechRecognitionErrorEvent이며,error속성은not-allowed로 초기화,message속성은 사유를 나타내는 구현 정의 문자열로 설정합니다. -
이 단계를 중단합니다.
-
4.1.4. SpeechRecognition 이벤트
음성 인식 이벤트에는 DOM Level 2 Event Model이 사용됩니다. 이벤트 리스너 등록에는 EventTarget 인터페이스의 메서드를 사용해야 합니다. SpeechRecognition 인터페이스에는 각각의 이벤트 타입별로 하나의 이벤트 핸들러를 등록할 수 있는 편의 속성도 포함되어 있습니다. 이 이벤트들은 버블링되지 않으며 취소할 수 없습니다.
이 모든 이벤트에 대해, DOM Level 2 Event 인터페이스에 정의된 timeStamp 속성은 이벤트 객체가 나타내는 실세계 이벤트가 발생한 시각을 최대한 정확히 나타내도록 설정되어야 합니다. 이 타임스탬프는 사용자 에이전트의 시간 기준이어야 하며, 원격 인식 서비스 등 타 머신에서 발생한 이벤트라도 마찬가지입니다(예: speechend 이벤트가 원격 speech endpointer에서 발생한 경우).
아래에 명시된 경우를 제외하고, 이벤트들의 순서는 정의되지 않습니다. 예를 들어 일부 구현에서는 오디오 감지기가 클라이언트이고 음성 감지기가 서버인 경우, audioend가 speechstart나 speechend보다 먼저 발생할 수 있습니다.
audiostartevent- 사용자 에이전트가 오디오를 캡처하기 시작할 때 발생합니다.
soundstartevent- 일부 소리(음성일 수도 있음)가 감지될 때 발생합니다. 이 이벤트는 (예: 클라이언트 측 에너지 감지기를 사용하여) 짧은 지연 시간으로 발생해야 합니다. audiostart 이벤트는 항상 soundstart 이벤트 전에 발생해야 합니다.
speechstartevent- 음성 인식에 사용할 음성이 시작될 때 발생합니다. audiostart 이벤트는 항상 speechstart 이벤트 전에 발생해야 합니다.
speechendevent- 음성 인식에 사용할 음성이 끝날 때 발생합니다. speechstart 이벤트는 항상 speechend 전에 발생해야 합니다.
soundendevent- 소리가 더 이상 감지되지 않을 때 발생합니다. 이 이벤트는 (예: 클라이언트 측 에너지 감지기를 사용하여) 짧은 지연 시간으로 발생해야 합니다. soundstart 이벤트는 항상 soundend 이벤트 전에 발생해야 합니다.
audioendevent- 사용자 에이전트가 오디오 캡처를 완료했을 때 발생합니다. audiostart 이벤트는 항상 audioend 이벤트 전에 발생해야 합니다.
resultevent- 음성 인식기가 결과를 반환할 때 발생합니다.
이벤트는
SpeechRecognitionEvent인터페이스를 사용해야 합니다. audiostart 이벤트는 항상 result 이벤트 전에 발생해야 합니다. nomatchevent- 음성 인식기가 신뢰 임계값을 충족하거나 초과하는 인식 가설 없이 최종 결과를 반환할 때 발생합니다.
이벤트는
SpeechRecognitionEvent인터페이스를 사용해야 합니다. 이벤트의results속성에는 신뢰 임계값 이하의 음성 인식 결과가 포함되어 있거나 null일 수 있습니다.audiostart이벤트는 항상 nomatch 이벤트 전에 발생해야 합니다. errorevent- 음성 인식 오류가 발생할 때 발생합니다.
이벤트는
SpeechRecognitionErrorEvent인터페이스를 사용해야 합니다. startevent- 인식 서비스가 인식을 위해 오디오 듣기를 시작하면 발생합니다.
endevent- 서비스가 연결이 끊어질 때 발생합니다. 이 이벤트는 종료의 사유와 상관없이 세션이 종료될 때 항상 생성되어야 합니다.
4.1.5. SpeechRecognitionErrorEvent
SpeechRecognitionErrorEvent
인터페이스는 error 이벤트에 사용됩니다.
errorattribute, type: SpeechRecognitionErrorCode (readonly)-
errorCode는 어떤 문제가 발생했는지를 나타내는 열거형입니다.
값은 다음과 같습니다:
"no-speech"- 음성이 감지되지 않았습니다.
"aborted"- 음성 입력이 중단되었습니다(예: 일부 사용자 에이전트 UI에서 사용자가 음성 입력을 취소).
"audio-capture"- 오디오 캡처에 실패했습니다.
"network"- 인식 완료에 필요한 네트워크 통신이 실패했습니다.
"not-allowed"- 보안, 개인정보 또는 사용자 설정상의 이유로 사용자 에이전트가 어떤 음성 입력도 허용하지 않습니다.
"service-not-allowed"- 사용자 에이전트가 웹 애플리케이션이 요청한 음성 서비스는 허용하지 않으나, 어떤 음성 서비스는 허용할 수 있습니다(지원되지 않아서, 또는 보안, 개인정보, 사용자 설정의 이유 등).
"language-not-supported"- 해당 언어가 지원되지 않습니다.
"phrases-not-supported"- 음성 인식 모델이 컨텍스트 바이어싱 구문을 지원하지 않습니다.
messageattribute, type: DOMString (readonly)- message의 내용은 구현에 따라 다릅니다. 이 속성은 주로 디버깅용이며, 개발자가 자신의 애플리케이션 UI에 직접 사용하는 것은 권장하지 않습니다.
4.1.6. SpeechRecognitionAlternative
SpeechRecognitionAlternative은 n-best 목록에서 사용되는 응답의 단순한 뷰를 나타냅니다.
transcriptattribute, 타입 DOMString, readonly- transcript 문자열은 사용자가 말한 원시 단어를 나타냅니다. 연속 인식의 경우, 인접한 SpeechRecognitionResult의 연결 결과가 세션의 올바른 전사문(transcript)이 되도록 앞뒤 공백을 필요에 따라 반드시 포함해야 합니다.
confidenceattribute, 타입 float, readonly-
confidence는 인식 결과가 올바르다는 것을 인식 시스템이 얼마나 신뢰하는지를 0과 1 사이의 숫자로 나타냅니다.
값이 클수록 시스템의 신뢰도가 더 높음을 의미합니다.
그룹에서는 confidence가 음성 인식 엔진 독립적으로 명시될 수 있는지, 그리고 confidence threshold나 nomatch가 포함될 필요가 있는지 논의했습니다. 이는 다이얼로그 API가 아니기 때문입니다. 관련 논의는 Confidence property 스레드를 참고하세요.
4.1.7. SpeechRecognitionResult
SpeechRecognitionResult 객체는 한 번의 인식 매치 결과 하나를 나타내며, 연속 인식의 한 작은 부분일 수도 있고 비연속 인식의 전체 반환 결과일 수도 있습니다.
lengthattribute, 타입 unsigned long, readonly- long 속성은 item 배열에 몇 개의 n-best 대안이 포함되어 있는지를 나타냅니다.
item(index)getter- item getter는 n-best 값 배열에서 index 위치의 SpeechRecognitionAlternative를 반환합니다. index가 length보다 크거나 같으면 null을 반환합니다. 사용자 에이전트는 length 속성이 배열 요소 개수와 항상 같도록 보장해야 합니다. 사용자 에이전트는 n-best 목록이 신뢰도 내림차순(각 요소의 신뢰도가 이전 요소 이하)으로 정렬되도록 해야 합니다.
isFinalattribute, 타입 boolean, readonly- final 불리언은 이 인덱스 값이 음성 서비스에서 반환되는 마지막 결과일 경우 true로 설정되어야 합니다. false인 경우, 이는 결과가 임시이며 변경될 수 있음을 나타냅니다.
4.1.8. SpeechRecognitionResultList
SpeechRecognitionResultList 객체는 연속 인식의 전체 반환 결과를 나타내는 일련의 인식 결과를 보유합니다. 비연속 인식의 경우 단일 값만 보유합니다.
lengthattribute, 타입 unsigned long, readonly- length 속성은 item 배열에 몇 개의 결과가 포함되어 있는지 나타냅니다.
item(index)getter- item getter는 result 값 배열에서 index 위치의 SpeechRecognitionResult를 반환합니다. index가 length보다 크거나 같으면 null을 반환합니다. 사용자 에이전트는 length 속성이 배열의 요소 개수와 항상 같도록 보장해야 합니다.
4.1.9. SpeechRecognitionEvent
SpeechRecognitionEvent는 임시 또는 최종 결과에 변화가 있을 때마다 발생하는 이벤트입니다.
resultIndexattribute, 타입 unsigned long, readonly- resultIndex는 "results" 배열에서 변경된 가장 낮은 인덱스를 설정합니다.
resultsattribute, 타입 SpeechRecognitionResultList, readonly- 이 세션의 현재 모든 인식 결과 배열입니다. 즉, 반환된 모든 최종 결과에 이어 모든 임시 결과에 대한 현 시점 최고의 가설이 오게 됩니다. 이는 0개 이상의 최종 결과와 그 다음 0개 이상의 임시 결과로 구성되어야 합니다. 이후 SpeechRecognitionResultEvent가 발생할 때마다, 임시 결과는 더 새로운 임시 결과나 최종 결과로 덮어써지거나, (배열의 마지막 위치라면) 삭제될 수 있습니다(배열 길이가 줄어드는 경우). 최종 결과는 덮어써지거나 제거되어서는 안 됩니다. resultIndex보다 작은 인덱스의 모든 항목은 마지막 SpeechRecognitionResultEvent 발생 시점 배열과 동일해야 합니다. resultIndex 이상 인덱스에 해당하는 항목(이전 이벤트의 배열에 있었다면)은 모두 삭제되고 새로운 결과로 덮어쓰여야 합니다. "results" 배열 길이는 늘거나 줄 수 있으나, resultIndex보다 작아서는 안 됩니다. resultIndex가 results.length와 같으면 새 결과가 반환되지 않으며, 이는 배열 길이가 줄어들며 하나 또는 그 이상의 임시 결과가 제거되는 경우에 발생할 수 있습니다.
4.1.10. SpeechRecognitionPhrase
SpeechRecognitionPhrase 객체는 컨텍스트 바이어싱을 위한 구문을 나타내며 다음 내부 슬롯을 가집니다:
[[phrase]]-
boost될 텍스트 문자열을 나타내는
DOMString입니다. 초기값은 null입니다. 빈 값은 허용되지만, 음성 인식 모델에서는 무시되어야 합니다.
[[boost]]-
이 구문이 음성 인식 모델에서 아는 것보다 웹사이트에서 얼마나 더 자주 등장할 것으로 생각하는지를 자연로그로 근사한 float입니다. boost 값은 [0.0, 10.0] 범위 내의 float이어야 하며, 지정하지 않으면 기본값은 1.0입니다. boost가 0.0이면 전혀 boost되지 않음을 의미하고, boost가 높을수록 해당 구문이 더 많이 나타날 확률이 커집니다. boost를 10.0으로 설정하는 것은 매우 드문 경우여야 하며, 이는 극단적으로 나타날 확률이 높다고 간주됨을 뜻합니다.
SpeechRecognitionPhrase(phrase, boost)constructor-
이 생성자가 호출되면 다음 단계를 실행합니다:
-
boost가 0.0보다 작거나 10.0보다 크면
SyntaxError를 던지고 중단합니다. -
phr을
SpeechRecognitionPhrase타입 새로운 객체로 만듭니다. -
phr의
[[phrase]]에 phrase 값을 설정합니다. -
phr의
[[boost]]에 boost 값을 설정합니다. -
phr을 반환합니다.
-
phraseattribute, 타입 DOMString, readonly- 이 속성은
[[phrase]]값을 반환합니다. boostattribute, 타입 float, readonly- 이 속성은
[[boost]]값을 반환합니다.
4.1.11. SpeechGrammar
SpeechGrammar 객체는 문법(grammar)에 대한 컨테이너를 나타냅니다.
문법 지원은 더 이상 권장되지 않으며 제거되었습니다. 문법 객체는 이전 버전과의 호환성을 위해 명세에 남아있을 뿐, 음성 인식에는 영향을 주지 않습니다.
이 구조는 다음 속성을 가집니다:
srcattribute, 타입 DOMString- 필수 src 속성은 해당 문법의 URI입니다.
weightattribute, 타입 float- 옵션 weight 속성은 이 문법을 사용할 때 음성 인식 서비스가 적용해야 하는 비중을 조절합니다. 기본적으로 문법의 weight는 1입니다. weight 값이 높을수록 문법의 비중이 높고, 낮을수록 비중이 약해집니다.
4.1.12. SpeechGrammarList
SpeechGrammarList 객체는 SpeechGrammar 객체 집합을 나타냅니다. 이 구조는 다음 속성을 가집니다:
문법 지원은 더 이상 권장되지 않으며 제거되었습니다. 문법 객체는 이전 버전과의 호환성을 위해 명세에 남아있을 뿐, 음성 인식에는 영향을 주지 않습니다.
lengthattribute, 타입 unsigned long, readonly- length 속성은 현재 배열에 포함된 문법의 개수를 나타냅니다.
item(index)getter- item getter는 grammars 배열에서 index 위치의 SpeechGrammar를 반환합니다. 사용자 에이전트는 length 속성이 배열 요소 개수와 항상 같도록 보장해야 합니다. 사용자 에이전트는 인덱스가 작은 쪽에서 큰 쪽 순서가 배열에 문법이 추가된 순서와 같음을 보장해야 합니다.
addFromURI(src, weight)method- 이 메서드는 URI를 기반으로 grammmars 배열에 문법을 추가합니다. 문법의 URI는 src 매개변수로 지정하며, 이는 문법의 URI를 나타냅니다. 일부 서비스는 URI로 지정할 수 있는 내장 문법을 지원할 수도 있습니다. weight 매개변수는 다른 문법과 비교해 이 문법의 상대적인 비중을 나타냅니다.
addFromString(string, weight)method- 이 메서드는 텍스트 기반으로 grammars 배열에 문법을 추가합니다. 문법의 내용은 string 매개변수로 지정합니다. 이 내용은 SpeechGrammar 객체를 만들 때 data: URI로 인코딩되어야 합니다. weight 매개변수는 다른 문법과 비교해 이 문법의 상대적인 비중을 나타냅니다.
4.2. SpeechSynthesis 인터페이스
SpeechSynthesis 인터페이스는 텍스트를 음성으로 변환하는 출력을 제어하는 스크립트 기반 웹 API입니다.
[Exposed =Window ]interface :SpeechSynthesis EventTarget {readonly attribute boolean pending ;readonly attribute boolean speaking ;readonly attribute boolean paused ;attribute EventHandler ;onvoiceschanged undefined speak (SpeechSynthesisUtterance );utterance undefined cancel ();undefined pause ();undefined resume ();sequence <SpeechSynthesisVoice >getVoices (); };partial interface Window { [SameObject ]readonly attribute SpeechSynthesis ; }; [speechSynthesis Exposed =Window ]interface :SpeechSynthesisUtterance EventTarget {(constructor optional DOMString );text attribute DOMString text ;attribute DOMString lang ;attribute SpeechSynthesisVoice ?voice ;attribute float volume ;attribute float rate ;attribute float pitch ;attribute EventHandler ;onstart attribute EventHandler ;onend attribute EventHandler ;onerror attribute EventHandler ;onpause attribute EventHandler ;onresume attribute EventHandler ;onmark attribute EventHandler ; }; [onboundary Exposed =Window ]interface :SpeechSynthesisEvent Event {(constructor DOMString ,type SpeechSynthesisEventInit );eventInitDict readonly attribute SpeechSynthesisUtterance utterance ;readonly attribute unsigned long charIndex ;readonly attribute unsigned long charLength ;readonly attribute float elapsedTime ;readonly attribute DOMString name ; };dictionary :SpeechSynthesisEventInit EventInit {required SpeechSynthesisUtterance ;utterance unsigned long = 0;charIndex unsigned long = 0;charLength float = 0;elapsedTime DOMString = ""; };name enum {SpeechSynthesisErrorCode "canceled" ,"interrupted" ,"audio-busy" ,"audio-hardware" ,"network" ,"synthesis-unavailable" ,"synthesis-failed" ,"language-unavailable" ,"voice-unavailable" ,"text-too-long" ,"invalid-argument" ,"not-allowed" , }; [Exposed =Window ]interface :SpeechSynthesisErrorEvent SpeechSynthesisEvent {(constructor DOMString ,type SpeechSynthesisErrorEventInit );eventInitDict readonly attribute SpeechSynthesisErrorCode error ; };dictionary :SpeechSynthesisErrorEventInit SpeechSynthesisEventInit {required SpeechSynthesisErrorCode ; }; [error Exposed =Window ]interface {SpeechSynthesisVoice readonly attribute DOMString voiceURI ;readonly attribute DOMString name ;readonly attribute DOMString lang ;readonly attribute boolean localService ;readonly attribute boolean default ; };
4.2.1. SpeechSynthesis 속성
pending속성, 타입 boolean, readonly- 전역 SpeechSynthesis 인스턴스의 큐에 아직 말하기가 시작되지 않은 발화(utterance)가 있으면 true입니다.
speaking속성, 타입 boolean, readonly- 발화가 실제로 말해지는 중이면 true입니다. 즉, 발화가 말하기를 시작했고 아직 끝나지 않았을 때입니다. 전역 SpeechSynthesis 인스턴스가 일시정지 상태인지 여부와는 무관합니다.
paused속성, 타입 boolean, readonly- 전역 SpeechSynthesis 인스턴스가 일시정지 상태인 경우 true입니다. 이 상태는 큐에 항목이 있는지와는 독립적입니다. 새 창의 기본 상태는 일시정지 아님입니다.
4.2.2. SpeechSynthesis 메서드
speak(utterance)메서드- 이 메서드는 SpeechSynthesisUtterance 객체 utterance를 전역 SpeechSynthesis 인스턴스의 큐 마지막에 추가합니다. SpeechSynthesis 인스턴스의 일시정지(paused) 상태는 변경하지 않습니다. 인스턴스가 일시정지 상태라면 그대로 유지됩니다. 일시정지 상태가 아니고 큐에 다른 발화가 없다면, 이 발화는 즉시 말해집니다. 그렇지 않으면 큐의 기존 발화가 모두 끝난 후에 말하기가 시작됩니다. 이 메서드 호출 후 end 또는 error 이벤트 발생 전 SpeechSynthesisUtterance 객체에 변경을 가하면, 그 변경이 실제 음성 출력을 변경할지 여부는 정의되지 않으며, 변경이 오류로 이어질 수 있습니다. SpeechSynthesis 객체는 해당 SpeechSynthesisUtterance 객체를 독점적으로 소유하게 됩니다. speak()의 인수로 다른 SpeechSynthesis 객체에 전달하면 예외가 발생해야 합니다. (예: 동일 출처에서 두 프레임이 각각 SpeechSynthesis 객체를 소유할 수 있음.)
cancel()메서드- 이 메서드는 큐에 있는 모든 발화를 제거합니다. 현재 말하고 있는 발화가 있으면 즉시 말하기가 중지됩니다. 이 메서드는 SpeechSynthesis 인스턴스의 일시정지 상태를 변경하지 않습니다.
pause()메서드- 이 메서드는 전역 SpeechSynthesis 인스턴스를 일시정지(paused) 상태로 만듭니다. 현재 발화가 진행 중이라면, 그 시점에서 멈춥니다. (이미 일시정지 상태인 경우 호출해도 아무런 동작을 하지 않습니다.)
resume()메서드- 이 메서드는 전역 SpeechSynthesis 인스턴스를 비일시정지 상태로 만듭니다. 발화가 진행 중이었다면, 멈춘 지점부터 이어서 말합니다. 아니라면 큐의 다음 발화(있다면)가 말해집니다. (이미 비일시정지 상태일 때 호출해도 아무 동작을 하지 않습니다.)
getVoices()메서드- 이 메서드는 사용 가능한 음성 목록을 반환합니다. 어떤 음성이 사용 가능한지는 사용자 에이전트마다 다릅니다. 사용 가능한 음성이 없거나, 사용 가능한 음성 목록이 아직 정해지지 않았다면(예: 서버 기반 합성, 비동기 결정), 이 메서드는 길이가 0인 SpeechSynthesisVoiceList를 반환해야 합니다.
4.2.3. SpeechSynthesis 이벤트
voiceschanged이벤트- getVoices 메서드가 반환하는 SpeechSynthesisVoiceList의 내용이 변경될 때 발생합니다. 예: 서버 기반 합성의 경우 목록이 비동기로 정해지거나, 클라이언트 음성이 설치/제거될 때 등.
4.2.4. SpeechSynthesisUtterance 속성
text속성, 타입 DOMString- 이 속성은 합성되고 말해질 발화의 텍스트를 지정합니다. 일반 텍스트나 완전하고 올바르게 작성된 SSML 문서일 수 있습니다. [SSML] 합성 엔진이 SSML을 지원하지 않거나 일부 태그만 지원하는 경우, 사용자 에이전트 또는 합성 엔진은 지원하지 않는 태그를 제거하고 텍스트만 말해야 합니다. 텍스트의 최대 길이가 있을 수 있으며, 예를 들어 32,767자로 제한될 수 있습니다.
lang속성, 타입 DOMString- 이 속성은 유효한 BCP 47 언어 태그를 사용하여 이 발화의 합성 언어를 지정합니다. [BCP47] 설정되지 않으면 스크립트에서 불러올 때 remains unset로 남지만, html 문서 루트 요소와 계층의 언어를 기본값으로 사용합니다. 이 기본값은 입력 요청이 인식 서비스에 연결을 열 때 계산되어 사용됩니다.
voice속성, 타입 SpeechSynthesisVoice, nullable- 이 속성은 웹 애플리케이션이 사용하고자 하는 음성 합성 voice를 지정합니다.
SpeechSynthesisUtterance객체가 생성될 때 이 속성은 반드시 null로 초기화되어야 합니다.speak()메서드를 호출할 때 이 속성이SpeechSynthesisVoice중 하나로 설정되어 있으면, 그 voice를 사용해야 합니다. 설정되지 않았거나 null이면, 사용자 에이전트의 기본 voice를 사용해야 합니다. 기본 voice는 현재 언어(아래lang참고)를 지원해야 하며, 로컬 또는 원격 합성 서비스일 수 있으며, 사용자 에이전트의 설정 인터페이스를 통해 최종 사용자의 선택을 반영할 수도 있습니다. volume속성, 타입 float- 이 속성은 발화의 볼륨 크기를 지정합니다. 0~1 사이의 값이며, 0이 최소, 1이 최대이고 기본값은 1입니다. SSML 사용 시, 이 값은 마크업의 prosody 태그에 의해 덮어써질 수 있습니다.
rate속성, 타입 float- 이 속성은 발화의 속도를 지정합니다. 해당 voice의 기본 속도에 대한 상대값입니다. 1은 기본 속도(보통 일반 말하기 속도), 2는 두 배, 0.5는 절반 속도를 의미합니다. 0.1 미만 또는 10 초과 값은 엄격히 허용하지 않으며, 엔진/voice가 허용하는 속도 범위는 더 제한적일 수 있습니다. 예를 들어, 3 초과 값을 줘도 실제로는 3배까지만 말할 수도 있습니다. SSML 사용 시, 이 값은 마크업의 prosody 태그에 의해 덮어써질 수 있습니다.
pitch속성, 타입 float- 이 속성은 발화의 높낮이(pitch)를 지정합니다. 0~2 사이의 값이며, 0이 가장 낮고 2가 가장 높으며, 1은 기본 값입니다. 엔진마다 허용 범위는 다를 수 있습니다. SSML 사용 시, 이 값은 마크업의 prosody 태그에 의해 덮어써질 수 있습니다.
4.2.5. SpeechSynthesisUtterance 이벤트
이 이벤트들은 모두 SpeechSynthesisEvent
인터페이스를 사용해야 하며,
error 이벤트만은 SpeechSynthesisErrorEvent
인터페이스를 사용해야 합니다.
이 이벤트들은 버블링되지 않고 취소할 수 없습니다.
start이벤트- 이 발화가 말하기를 시작할 때 발생합니다.
end이벤트- 이 발화가 다 말해졌을 때 발생합니다. 이 이벤트가 발생하면, error 이벤트는 이 발화에 대해 절대 발생하지 않습니다.
error이벤트- 이 발화를 성공적으로 말하지 못한 오류가 발생할 때 발생합니다. error 이벤트가 발생하면, end 이벤트는 이 발화에 대해 절대 발생하지 않습니다.
pause이벤트- 이 발화가 진행 중 일시정지되면 발생합니다.
resume이벤트- 이 발화가 일시정지 후 다시 재생될 때 발생합니다. 전역 SpeechSynthesis 인스턴스가 일시정지 상태에서 큐에 발화를 추가한 뒤 resume을 호출했을 때는 resume 이벤트가 아니라 start 이벤트만 발생합니다.
mark이벤트- 말하기가 SSML의 "mark" 태그에 기록한 이름에 도달했을 때 발생합니다. [SSML] 음성 합성 엔진이 이 이벤트를 제공하면 반드시 발생해야 합니다.
boundary이벤트- 말하기가 단어 혹은 문장 경계에 도달했을 때 발생합니다. 음성 합성 엔진이 이 이벤트를 제공하면 반드시 발생해야 합니다.
4.2.6. SpeechSynthesisEvent 속성
utterance속성, 타입 SpeechSynthesisUtterance, readonly- 이 이벤트를 유발한 SpeechSynthesisUtterance를 포함합니다.
charIndex속성, 타입 unsigned long, readonly- 이 속성은 음성 엔진이 현재 말하고 있는 위치에 가장 근접한 0 기반(Zero-based) 문자 인덱스를 나타냅니다. charIndex가 단어 경계(이전 단어 끝, 다음 단어 시작 등)와 정확히 일치할 것이라는 보장은 없으며, 단지 charIndex 앞의 텍스트는 이미 말해졌고 그 뒤의 텍스트는 아직 말해지지 않았음을 의미합니다. 지원하지 않는 엔진의 경우 0을 반환합니다.
charLength속성, 타입 unsigned long, readonly- 이 속성은 해당 이벤트에 맞는 말해지는 텍스트(단어나 문장)의 길이를 나타냅니다.
이 값은 해당 이벤트의
charIndex부터의 문자 수입니다. 엔진이 지원하거나 판단 가능하다면 이 값을 반환하고, 아니라면 0을 반환합니다. elapsedTime속성, 타입 float, readonly- 이 속성은 해당 이벤트가 발생한 시점을 이 발화가 말하기를 시작한 시간(초)으로부터 경과한 시간(초)로 나타냅니다. 엔진이 지원하거나 사용자 에이전트가 알 수 있다면 이 값을 반환하고, 아니라면 0을 반환합니다.
name속성, 타입 DOMString, readonly- mark 이벤트에서는 SSML의 mark 요소 name 속성값(마커 이름)을 나타냅니다. [SSML] boundary 이벤트에서는 "word" 또는 "sentence"와 같이 이벤트를 유발한 경계 종류를 나타냅니다. 그 외 이벤트에서는 ""을 반환해야 합니다.
4.2.7. SpeechSynthesisErrorEvent 속성
SpeechSynthesisErrorEvent는 SpeechSynthesisUtterance error 이벤트에 사용되는 인터페이스입니다.
error속성, 타입 SpeechSynthesisErrorCode, readonly-
errorCode는 어떤 오류가 발생했는지 나타내는 열거형입니다.
값은 다음과 같습니다:
"canceled"- cancel 메서드 호출로 SpeechSynthesisUtterance가 말하기를 시작하기 전에 큐에서 제거되었습니다.
"interrupted"- cancel 메서드 호출로 말하기가 시작된 이후 완료 되기 전에 발화가 중단되었습니다.
"audio-busy"- 현재 사용자 에이전트가 오디오 출력장치에 접근할 수 없어 작업을 완료할 수 없습니다. (예: 사용자가 다른 앱을 닫아야 할 수 있음.)
"audio-hardware"- 현재 사용자 에이전트가 오디오 출력장치를 인식할 수 없어 작업을 완료할 수 없습니다. (예: 사용자가 스피커를 연결하거나 시스템 설정을 해야 할 수 있음.)
"network"- 필요한 네트워크 통신이 실패하여 작업을 완료할 수 없습니다.
"synthesis-unavailable"- 현재 사용할 수 있는 합성 엔진이 없습니다. (예: 엔진 설치/설정 필요)
"synthesis-failed"- 합성 엔진 오류로 작업에 실패하였습니다.
"language-unavailable"- SpeechSynthesisUtterance의 lang에 지정된 언어에 맞는 voice가 없습니다.
"voice-unavailable"- SpeechSynthesisUtterance voice 속성에 지정된 voice가 없습니다.
"text-too-long"- SpeechSynthesisUtterance text 속성 내용이 너무 길어 합성할 수 없습니다.
"invalid-argument"- SpeechSynthesisUtterance의 rate, pitch, volume 속성 값이 합성 엔진에서 지원하지 않습니다.
"not-allowed"- 현재 컨텍스트에서 사용자 에이전트나 시스템에서 합성 실행이 허용되지 않았습니다.
4.2.8. SpeechSynthesisVoice 속성
voiceURI속성, 타입 DOMString, readonly- voiceURI 속성은 이 voice에 대한 음성 합성 voice와 그 서비스 위치를 지정합니다. voiceURI는 범용 URI이므로, 사용자 에이전트가 인식 가능한 URN 또는 URL을 통해 로컬/원격 서비스 어디든 지정할 수 있습니다.
name속성, 타입 DOMString, readonly- 이 속성은 사람 읽을 수 있는 이름 문자열이며, 모든 이름이 고유(유일)함을 보장하지 않습니다.
lang속성, 타입 DOMString, readonly- 이 속성은 BCP 47 언어 태그이며, 해당 음성의 언어를 나타냅니다. [BCP47]
localService속성, 타입 boolean, readonly- 이 속성은 로컬 음성 합성 엔진에서 제공하는 voice면 true, 원격 서비스 제공이면 false입니다. (원격은 추가 지연, 대역폭, 비용을 암시할 수 있고, 로컬은 품질 저하를 암시할 수 있으나, 이러한 의미들 모두 반드시 보장되지는 않습니다.)
default속성, 타입 boolean, readonly- 이 속성이 true인 voice는 언어별로 많아야 하나만 있습니다. 언어별로 서로 다른 기본 음성이 있을 수 있으며, 어떤 voice가 기본인지 결정 방법은 사용자 에이전트마다 다릅니다.
5. 예시
이 섹션은 비규범적입니다.
5.1. 음성 인식 예시
음성 인식을 사용하여 입력 필드를 채우고 웹 검색을 수행합니다.
< script type = "text/javascript" > var recognition= new SpeechRecognition(); recognition. onresult= function ( event) { if ( event. results. length> 0 ) { q. value= event. results[ 0 ][ 0 ]. transcript; q. form. submit(); } } </ script > < form action = "https://www.example.com/search" > < input type = "search" id = "q" name = "q" size = 60 > < input type = "button" value = "말하기 시작" onclick = "recognition.start()" > </ form >
음성 인식을 사용하여 대안 음성 결과로 옵션 목록을 채웁니다.
< script type = "text/javascript" > var recognition= new SpeechRecognition(); recognition. maxAlternatives= 10 ; recognition. onresult= function ( event) { if ( event. results. length> 0 ) { var result= event. results[ 0 ]; for ( var i= 0 ; i< result. length; ++ i) { var text= result[ i]. transcript; select. options[ i] = new Option( text, text); } } } function start() { select. options. length= 0 ; recognition. start(); } </ script > < select id = "select" ></ select > < button onclick = "start()" > 말하기 시작</ button >
연속 음성 인식을 사용하여 textarea를 채웁니다.
< textarea id = "textarea" rows = 10 cols = 80 ></ textarea > < button id = "button" onclick = "toggleStartStop()" ></ button > < script type = "text/javascript" > var recognizing; var recognition= new SpeechRecognition(); recognition. continuous= true ; reset(); recognition. onend= reset; recognition. onresult= function ( event) { for ( var i= event. resultIndex; i< event. results. length; ++ i) { if ( event. results[ i]. isFinal) { textarea. value+= event. results[ i][ 0 ]. transcript; } } } function reset() { recognizing= false ; button. innerHTML= "말하기 시작" ; } function toggleStartStop() { if ( recognizing) { recognition. stop(); reset(); } else { recognition. start(); recognizing= true ; button. innerHTML= "말하기 중지" ; } } </ script >
연속 음성 인식을 사용하여, 최종 결과는 검정색, 임시 결과는 회색으로 표시합니다.
< button id = "button" onclick = "toggleStartStop()" ></ button > < div style = "border:dotted;padding:10px" > < span id = "final_span" ></ span > < span id = "interim_span" style = "color:grey" ></ span > </ div > < script type = "text/javascript" > var recognizing; var recognition= new SpeechRecognition(); recognition. continuous= true ; recognition. interimResults= true ; reset(); recognition. onend= reset; recognition. onresult= function ( event) { var final = "" ; var interim= "" ; for ( var i= 0 ; i< event. results. length; ++ i) { if ( event. results[ i]. isFinal) { final += event. results[ i][ 0 ]. transcript; } else { interim+= event. results[ i][ 0 ]. transcript; } } final_span. innerHTML= final ; interim_span. innerHTML= interim; } function reset() { recognizing= false ; button. innerHTML= "말하기 시작" ; } function toggleStartStop() { if ( recognizing) { recognition. stop(); reset(); } else { recognition. start(); recognizing= true ; button. innerHTML= "말하기 중지" ; final_span. innerHTML= "" ; interim_span. innerHTML= "" ; } } </ script >
5.2. 음성 합성 예시
음성으로 출력되는 텍스트.
< script type = "text/javascript" > speechSynthesis. speak( new SpeechSynthesisUtterance( 'Hello World' )); </ script >
속성과 이벤트가 포함된 음성 텍스트.
< script type = "text/javascript" > var u= new SpeechSynthesisUtterance(); u. text= 'Hello World' ; u. lang= 'en-US' ; u. rate= 1.2 ; u. onend= function ( event) { alert( 'Finished in ' + event. elapsedTime+ ' seconds.' ); } speechSynthesis. speak( u); </ script >
감사의 글
Adam Sobieski (Phoster) Björn Bringert (Google) Charles Pritchard Dominic Mazzoni (Google) Gerardo Capiel (Benetech) Jerry Carter Kagami Sascha Rosylight Marcos Cáceres (Mozilla) Nagesh Kharidi (Openstream) Olli Pettay (Mozilla) Peter Beverloo (Google) Raj Tumuluri (Openstream) Satish Sampath (Google)
또한, HTML Speech Incubator Group의 구성원과 본 명세 기반을 만든 최종 보고서에 감사드립니다.