1. 인프라스트럭처
이 명세는 Infra Standard에 의존합니다. [INFRA]
2. 소개
2.1. 사용 사례
2.1.1. 웹 텍스트 참조
텍스트 조각의 핵심 사용 사례는 URL이 웹 전체에서 정확한 텍스트 참조로 사용될 수 있도록 하는 것입니다. 예를 들어, Wikipedia 참조는 인용하는 페이지의 정확한 텍스트로 연결될 수 있습니다. 유사하게, 검색 엔진은 사용자가 원하는 답이 페이지 내 어디에 있는지 바로 안내하는 URL을 제공할 수 있습니다. 이는 페이지 맨 위로 이동시키는 링크 대신입니다.2.1.2. 사용자 공유
텍스트 지시문이 있으면, 브라우저는 사용자가 텍스트를 선택 후 컨텍스트 메뉴를 열 때 '여기로 URL 복사' 옵션을 구현할 수 있습니다. 그 후 브라우저는 해당 텍스트 선택이 명확하게 지정된 URL을 생성할 수 있고, URL을 받은 사람은 지정된 텍스트가 편리하게 표시됩니다. 텍스트 조각이 없다면 사용자가 페이지에서 텍스트 일부를 공유하고 싶을 때, 아마도 단순히 그 일부를 복사해 붙여넣기 할 것이며, 이 경우 수신자는 페이지의 맥락(context)를 잃게 됩니다.2.2. 링크 수명
이 명세는 텍스트 지시문 링크의 유효 수명을 극대화하려고 시도합니다. 예를 들어, 실제 텍스트 내용을 URL 페이로드로 사용하고, 필요시 fallback 엘리먼트 ID 조각을 허용합니다. 하지만 웹의 페이지들은 종종 업데이트되고 그 내용을 변경합니다. 따라서 이런 링크들은 가리키는 텍스트가 더 이상 대상 페이지에 존재하지 않아 "썩는(rot)" 현상이 있을 수 있습니다.
이런 문제에도 불구하고 텍스트 지시문 링크는 유용할 수 있습니다. 사용자 공유 같은 use case에서는, 링크가 일시적(transient)이며, 전송 후 바로 사용되는 용도에 적합합니다. 참고 문헌이나 웹 페이지 링크처럼 오랜 기간 사용되는 경우, 텍스트 지시문은 점진적으로 일반 링크로 동작하므로 여전히 유용합니다. 추가로, 오래된(stale) 텍스트 지시문이 표시되면 사용자가 링크 생성자의 원래 의도를 이해하고, 링크가 생성된 이후 페이지 내용이 변경되었음을 알 수 있는 정보가 됩니다.
견고한 텍스트 지시문 링크 생성의 모범 사례는 § 4 텍스트 조각 지시문 생성을 참고하세요.
3. 설명
3.1. 표시
이 명세는 텍스트 일치 항목을 "표시"할 때 사용자 에이전트가 무엇을 해야 하는지 구체적으로 정의하지 않습니다. 사용자 에이전트마다 다양한 경험과 선택지가 있습니다. 가능한 동작의 예시:
-
텍스트 구절에 시각적 강조 또는 하이라이트 제공
-
페이지 이동 시, 해당 구절로 자동 스크롤
-
UA의 페이지 내 찾기(Find-in-page) 기능 활성화
-
"텍스트 구절로 스크롤" 알림 제공
-
텍스트 구절이 페이지에 없을 때 알림 제공
3.2. 구문
텍스트 지시문은 조각 지시문(§ 3.3 The Fragment Directive 참고)에 다음과 같은 형식으로 지정됩니다:
#:~:text=[prefix-,]start[,end][,-suffix]
context |--match--| context
(대괄호는 선택적 매개변수를 의미합니다)
텍스트 매개변수는 매칭 이전에 퍼센트 디코딩됩니다. Dash(-), ampersand(&), comma(,)는 지시문 구문으로 오해받지 않도록 퍼센트 인코딩됩니다.
필수 매개변수는 start 뿐입니다. start만 지정된 경우, 정확히 일치하는 첫 텍스트 문자열이 대상이 됩니다.
end 매개변수도 함께 지정되면, 텍스트 지시문은 페이지 내의 텍스트 범위를 참조하게 됩니다. 대상 텍스트 범위는 첫 start 발생 위치에서 바로
뒤따르는 end의 첫 발생 위치까지입니다. 이는 전체 텍스트 범위를 start에 명시하는 것과 같으나, 긴 지시문 사용을 피할 수 있습니다.
3.2.1. 문맥 용어
두 개의 다른 선택적 매개변수는 문맥 용어(context terms)입니다. prefix 뒤와 suffix 앞의 dash(-)로 구분되어, 어떤 조합의 선택 매개변수도 지정할 수 있도록
start와 end와 구별됩니다.
문맥 용어는 대상 텍스트 조각을 명확하게 식별하는 데 사용됩니다. 문맥 용어는 조각 바로 앞(prefix)이나 뒤(suffix)의 텍스트를 지정하며, 공백은 허용됩니다.
문맥 용어는 매칭 대상인 텍스트 조각에는 포함되지 않으며, 시각적으로 표시되지도 않습니다.
#:~:text=this%20is-,an%20example,-text%20fragment는 "this is an example text fragment"에서 "an
example"에 일치하지만, "here is an example text"에는 일치하지 않습니다.
3.2.2. 양방향(BiDi) 고려사항
URL 문자열은 ASCII로 인코딩되므로, 내장된 양방향 텍스트 지원이 없습니다. 하지만, 페이지의 대상 텍스트는 LTR(왼쪽→오른쪽), RTL(오른쪽→왼쪽), 또는 둘 다(BiDi)일 수 있습니다. 본 섹션에선 명세의 규범적 부분에서 암시된 동작을 직관적으로 설명합니다.
텍스트 조각 내 각 용어의 문자는 논리적 순서로 배치됩니다. 즉, 원어 사용자가 읽는 순서(메모리 저장 순서)입니다.
마찬가지로 prefix와 start 용어는 논리적 순서 상 앞에 오는 문자열을, suffix와 end는
논리적 순서 상 뒤에 오는 문자열을 지정합니다.
참고: 사용자 에이전트는, 예를 들어 표시 문자열을 유니코드로 변환함으로써, 원어 사용자에게 더 친숙하게 URL을 렌더링할 수 있습니다. 하지만 URL의 문자열 표현은 오직 ASCII 문자로 유지됩니다.
مِصر(이집트, 아랍어)을 선택하고, 그 앞에
البحرين(바레인, 아랍어)이 있을 경우라고 가정해봅시다. 각 용어를 퍼센트 인코딩하면:
مِصر는 "%D9%85%D8%B5%D8%B1"이 됩니다. (참고: UTF-8 문자 [0xD9,0x85]가 아랍어 단어의 첫(오른쪽) 문자)
البحرين는 "%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86"이 됩니다.
텍스트 조각은 이렇게 됩니다:
:~:text=%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86-,%D9%85%D8%B5%D8%B1
브라우저 주소창에서는 브라우저가 자연스러운 RTL 방향으로 시각적 렌더링을 하므로 사용자에게는 다음과 같이 보일 수 있습니다:
:~:text=البحرين-,مِصر
3.3. 조각 지시문
기존 URL 조각 사용과의 호환성 문제를 피하기 위해, 본 명세는 조각 지시문 개념을 도입합니다. 이것은 URL 조각의 조각 지시문 구분자 뒤에 오는 부분이며, 구분자가 조각에 나타나지 않은 경우 null일 수 있습니다.
조각 지시문 구분자는 문자열 ":~:"입니다. 즉, 연속된 3개의 코드포인트 U+003A(:), U+007E(~), U+003A(:)입니다.
조각 지시문은 개별 지시문으로 파싱되어 처리되며, 이는 사용자 에이전트가 어떤 동작을 수행해야 하는지 안내하는 명령입니다. 여러 개의 지시문이 조각 지시문에 나타날 수 있습니다.
페이지 동작에 영향을 주지 않도록, 스크립트에서 접근 가능한 API에선 제거됩니다. 이는 미래 지시문이 웹 호환성 위험 없이 추가될 수 있도록 해줍니다.
3.3.1. 조각 지시문 추출
이 섹션에서는 조각 지시문이 스크립트에서 어떻게 숨겨지는지와 HTML § 7.4 탐색 및 세션 기록에 어떻게 적용되는지를 설명합니다.
-
세션 기록 항목은 이제 새로운 "지시문 상태" 항목을 포함합니다
-
모든 새 항목은 비어 있는 값으로 지시문 상태가 생성됩니다. 만약 새 URL에 조각 지시문이 포함되어 있으면, 해당 지시문이 상태 값에 기록됩니다(그렇지 않으면 null로 남음).
-
조각 지시문이 포함될 가능성이 있는 URL이 세션 기록 항목에 기록될 때마다, URL에서 조각 지시문을 추출하여 항목의 지시문 상태에 저장합니다. URL에 지시문이 포함될 수 있는 네 가지 지점:
-
일반적인 크로스 도큐먼트 탐색의 "navigate" 단계
-
조각 기반 동일 문서 탐색의 "navigate to a fragment" 단계
-
pushState/replaceState와 같은 동기 업데이트를 위한 "URL 및 기록 갱신 단계"
-
리디렉션에서 오는 URL에 대한 "fetch로 내비게이션 파라미터 생성" 단계
-
-
조각만 변경되는 동일 문서 탐색에서 새 URL이 지시문을 지정하지 않은 경우, 새 항목의 지시문 상태는 이전 항목의 지시문 상태를 참조합니다.
HTML § 7.4.1 세션 기록에서 지시문 상태를 정의:
HTML § 7.4.1 세션 기록에 대한 몽키패치:
지시문 상태 는 세션 기록 항목이 생성될 당시의 조각 지시문 값을 저장하며, 해당 항목에 접근할 때마다(탐색 시 등) 지시문(예: 텍스트 하이라이트 등)을 적용하는 데 사용됩니다. 다음을 가집니다:
여러 세션 기록 항목이 하나의 지시문 상태를 공유할 수 있습니다.
조각 지시문은 URL이 세션 기록 항목에 설정되기 전에 URL에서 제거됩니다. 대신 지시문 상태에 저장됩니다. 이것은 스크립트 API에서 지시문이 보이지 않도록 하여, 페이지 동작에 영향을 주지 않고 지시문만 지정할 수 있게 합니다.
조각 지시문은 순수 문자열 대신 지시문 상태 오브젝트에 저장됩니다. 왜냐하면 같은 지시문 상태가 여러 인접 세션 기록 항목에 공유될 수 있기 때문입니다. 탐색 시, 두 항목 사이에서 지시문 상태가 변경된 경우에만(예: 텍스트 검색 및 하이라이트 등) 지시문이 적용됩니다.
세션 기록 항목의 정의에 추가:
HTML § 7.4.1.1 세션 기록 항목에 대한 몽키패치:
URL에서 조각 지시문 문자열을 제거하고 반환하는 헬퍼 알고리즘 추가:
[HTML]에 대한 몽키패치:
이 알고리즘은 URL의 프래그먼트가 조각 지시문 구분자에서 끝나게 합니다. 반환되는 조각 지시문은 구분자 뒷부분 전체를 포함하며 구분자 자체는 포함하지 않습니다.TODO: 만약 URL의 프래그먼트가 ':~:'로 끝나면(즉, 빈 지시문), null이 반환되며 명시적 지시문을 지정하지 않은 것으로 간주합니다(기존 값 덮어쓰기 방지). 그러나 이 경우 빈 문자열을 반환하는 것이 더 좋을까요? 이렇게 하면 '#:~:'로 이동/푸시했을 때 명확히 지시문/하이라이트를 초기화할 수 있습니다.조각 지시문 제거 알고리즘은 URL url에서 아래 단계로 진행합니다:
raw fragment를 url의 fragment로 둡니다.
fragment directive를 null로 둡니다.
만약 raw fragment가 null이 아니고 조각 지시문 구분자가 substring으로 포함되어 있다면:
position을 문자 위치 변수로 설정하며, raw fragment에 조각 지시문 구분자가 처음 나타나는 첫 코드 포인트 또는 raw fragment 끝을 가리키게 합니다.
new fragment를 문자 위치별 부분 문자열로 설정합니다. raw fragment의 시작부터 position까지입니다.
position에 구분자 코드 포인트 길이만큼을 더합니다 (조각 지시문 구분자 길이).
만약 position이 raw fragment 끝을 넘지 않는다면:
fragment directive를 끝까지 부분 문자열(raw fragment의 position부터 끝까지)로 설정
url의 fragment를 new fragment로 설정합니다.
fragment directive를 반환합니다.
다음 네 가지 몽키패치는, URL에 조각 지시문을 포함할 가능성이 있을 때 세션 히스토리 항목을 생성할 때, 조각 지시문을 제거하고 지시문 상태에 저장하는 부분을 수정합니다.
navigate 정의에서:
HTML § 7.4.2.2 탐색 시작에 대한 몽키패치:
내비게이션 가능한 대상으로 URL url을 탐색하려면...:
...
- navigationId를 ongoing navigation에 설정
url 스킴이 "javascript"일 경우...
다음 단계들을 병렬로 실행:
...
- url이 about:blank라면 documentState의 origin을 documentState의 initiator origin으로 설정
그 외에 url이 about:srcdoc이라면 documentState의 origin을 상위의 active document의 origin으로 설정
historyEntry를 새 세션 기록 항목으로 만들어 그 URL과 documentState를 설정합니다.- fragment directive에 조각 지시문 제거 결과를 넣습니다.
directive state를 지시문 상태(value는 fragment directive)로 새로 생성합니다.
historyEntry를 새 세션 기록 항목으로 만들어 URL은 url, documentState와 지시문 상태를 각각 설정합니다.
navigationParams를 null로 설정
...
navigate to a fragment 정의에서:
HTML § 7.4.2.3.3 조각 탐색에 대한 몽키패치:
navigable navigable 및 ...이 주어졌을 때 조각으로 탐색:
directive state를 navigable의 active 세션 기록 항목의 지시문 상태로 둡니다.
fragment directive에 조각 지시문 제거의 결과를 넣습니다.
fragment directive가 null이 아니면:
조각만 바뀌고 지시문이 명시되지 않으면 현재 entry의 지시문 상태를 재사용하여 하이라이트 덮어쓰기를 방지합니다.historyEntry(새 세션 기록 항목) 작성:
URL url
document state navigable의 active 세션 기록 항목의 document state
scroll restoration mode navigable의 active 세션 기록 항목의 scroll restoration mode
지시문 상태 directive state
entryToReplace를 historyHandling이 "replace"면 navigable의 active 세션 기록 항목, 아니면 null로 둡니다.
...
URL 및 기록 업데이트 단계 정의에서:
HTML § 7.4.4 논-프래그먼트 동기 "탐색"에 대한 몽키패치:
Document document, ...이 주어졌을 때 "URL 및 기록 업데이트 단계":
navigable을 document의 node navigable로 둡니다.
activeEntry를 navigable의 active 세션 기록 항목으로 둡니다.
fragment directive를 조각 지시문 제거 결과로 둡니다.
historyEntry(새 세션 기록 항목) 작성:
document의 is initial about:blank가 true라면 historyHandling을 "replace"로 둡니다.
historyHandling이 "push"라면:
그 외 fragment directive가 null이 아니라면, historyEntry의 지시문 상태의 value를 fragment directive로 설정.
serializedData가 null이 아니라면 document와 newEntry로 history object 상태 복원.
create navigation params by fetching 정의에서:
HTML § 7.4.5 세션 기록 항목 채우기에 대한 몽키패치:
세션 기록 항목 entry 등으로 navigation params by fetching 생성:
이 코드는 병렬로 실행됨을 보장합니다.
...
- currentURL을 request의 current URL로 설정
commitEarlyHints를 null로 설정
while true:
request의 reserved client가 null이 아니고 currentURL의 origin과 reserved client 생성 URL의 origin이 다르면:
...
- currentURL을 locationURL로 설정
fragment directive를 조각 지시문 제거(locationURL) 결과로 설정
entry의 URL을 currentURL으로 설정entry의 URL을 locationURL로 설정
locationURL이 fetch scheme이 아닌 경우, request의 current URL의 origin을 initiator origin으로 써서 non-fetch scheme navigation params 새로 반환
...
Document는 히스토리 entry에서 채워지므로, 그 URL
에는
조각 지시문이 포함되지 않습니다. 또한 window의 Location
객체는 URL의 표현이므로 활성 문서에서 모든 getter는 조각 지시문이 제거된 URL 버전을 리턴합니다.
또한 HashChangeEvent
는 조각의
변경에 응답해 fired 되기 때문에,
hashchange는 네비게이션 또는 traversal이 조각 지시문만 변경할 때는 fired 되지 않습니다.
다양한 edge case를 명확하게 하기 위한 예시가 아래에 제공됨
window.location = "https://example.com#page1:~:hello"; console.log(window.location.href); // 'https://example.com#page1' console.log(window.location.hash); // '#page1'
초기 탐색으로 새 세션 기록 항목이 생성됩니다. 기록 항목의 URL은 조각 지시문이 제거된 "https://example.com#page1"입니다. 해당 entry의 지시문 상태 값은 "hello"가 됩니다. document가 entry에서 채워지므로, 웹 API는 URL에 조각 지시문을 포함하지 않습니다.
location.hash = "page2"; console.log(location.href); // 'https://example.com#page2'
동일 문서 탐색에서 조각만 바뀌었습니다. 이로 새 세션 기록 항목이 navigate to a fragment 단계에서 추가됩니다. 단, 조각만 바뀐 것이므로 새 entry의 지시문 상태는 첫 entry와 같은 상태("bar")를 참조합니다.
onhashchange = () => console.assert(false, "hashchange doesn’t fire."); location.hash = "page2:~:world"; console.log(location.href); // 'https://example.com#page2' onhashchange = null;
동일 문서 탐색에서 조각만 바뀌고, 조각 지시문도 포함되어 전달되었습니다. 명시적으로 지시문을 제공하면, 새 entry는 "fizz" 값을 가지는 별도의 지시문 상태가 됩니다.
페이지에 표시되는 fragment가 바뀌지 않았으므로 hashchange 이벤트는 fired 되지 않습니다. session history entry의 URL은 조각 지시문이 제거되어 비교가 이루어지기 때문입니다.
history.pushState("", "", "page3");
console.log(location.href); // 'https://example.com/page3'
pushState는 동일 문서에 대해 새 세션 기록 항목을 생성합니다. 비-프래그먼트 URL이 바뀌었으므로, 이 entry는 별도의 지시문 상태(null) 값을 가집니다.
URL 객체 예시:
let url = new URL('https://example.com#foo:~:bar');
console.log(url.href); // 'https://example.com#foo:~:bar'
console.log(url.hash); // '#foo:~:bar'
document.url = url;
console.log(document.url.href); // 'https://example.com#foo:~:bar'
console.log(document.url.hash); // '#foo:~:bar'
<a> 또는 <area> 요소:
<a id='anchor' href="https://example.com#foo:~:bar">Anchor</a> <script> console.log(anchor.href); // 'https://example.com#foo:~:bar' console.log(anchor.hash); // '#foo:~:bar' </script>
3.3.2. 문서에 지시문 적용
위 섹션에서는 조각 지시문이 URL에서 분리되어 세션 기록 항목에 저장되는 방식을 설명했습니다.
이 섹션에서는 탐색 및 이동(traversal)이 세션 기록 항목의 지시문 상태를 어떻게, 언제 사용하여 해당 세션 기록 항목에 연결된 지시문을 문서(Document)에 적용하는지 정의합니다.
Monkeypatching DOM § 4.5 문서 인터페이스:
각 문서는 보류 중인 텍스트 지시문(pending text directives)을 가집니다. 이 값은 null 또는 텍스트 지시문 리스트입니다. 초깃값은 null입니다.
히스토리 단계 적용을 위한 문서 업데이트의 정의에서:
Monkeypatching HTML § 7.4.6.2 문서 업데이트:
Document document 및 세션 기록 항목 entry ...이 주어졌을 때 문서 업데이트:
...
- document의 히스토리 객체 길이를 scriptHistoryLength로 설정
만약 documentsEntryChanged가 true라면:
oldURL을 document의 latest entry의 URL로 둔다.
document의 보류 중인 텍스트 지시문을 fragment directive 파싱 결과로 설정한다.
document의 latest entry를 entry로 설정
...
3.3.3. 조각 지시문 문법
참고: 이 섹션은 비규범적입니다.
참고: 이 문법(grammer)은 참고용으로 제공되며, 파싱에 대한 규칙은 § 3.4 텍스트 지시문 섹션에 명령적으로 정의되어 있습니다. 만약 본 문법과 3.4 절의 단계가 불일치한다면 3.4절 내용이 권위(authoritative)합니다.
FragmentDirective는 "&" 문자로 분리된 여러 지시문을 포함할 수 있습니다. 이는 페이지 내 여러 문자열을 동시에 지시하기 위해 여러 텍스트 지시문을 허용함을 의미하지만, 앞으로 추가·결합되는 여러 지시문 유형(타입)을 위한 확장성을 위해 미지정(unknown) 지시문이 &로 분리된 목록에 있어도 파싱 실패하지 않습니다.
문자열(string)은 아래 EBNF(확장 배커스-나우어 형식)를 만족하면 유효한 조각 지시문입니다:
-
FragmentDirective::= -
(TextDirective | UnknownDirective) ("&" FragmentDirective)? -
TextDirective::= -
"text="CharacterString -
UnknownDirective::= -
CharacterString - TextDirective -
CharacterString::= -
(ExplicitChar | PercentEncodedByte)* -
ExplicitChar::= -
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~" | "," | "-"ExplicitChar는 "&"를 제외한 모든 URL 코드포인트일 수 있습니다.
TextDirective는 아래 production을 만족해야 유효하다고 간주합니다:
ValidTextDirective::="text=" TextDirectiveParametersTextDirectiveParameters::=-
(TextDirectivePrefix ",")? TextDirectiveString ("," TextDirectiveString)? ("," TextDirectiveSuffix)? TextDirectivePrefix::=TextDirectiveString"-"TextDirectiveSuffix::="-"TextDirectiveStringTextDirectiveString::=(TextDirectiveExplicitChar | PercentEncodedByte)+TextDirectiveExplicitChar::=-
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~"TextDirectiveExplicitChar는 URL 코드포인트 중 FragmentDirective 또는 ValidTextDirective 구문에서 명시적으로 쓰이지 않은 쪽("&", "-", ",")만 제외합니다. 문서에서 "&", "-", ","가 필요한 경우 퍼센트 인코딩됩니다. PercentEncodedByte::="%" [a-zA-Z0-9][a-zA-Z0-9]
3.4. 텍스트 지시문
텍스트 지시문은 지시문의 한 종류로, 사용자에게 표시될 텍스트 범위를 나타냅니다. 네 개의 문자열(start, end, prefix, suffix)로 구성된 구조체(struct)입니다. start는 반드시 non-null이어야 하며, 나머지 세 항목은 null일 수 있습니다(제공되지 않은 경우). 네 항목 모두 빈 문자열은 허용되지 않습니다.
각 구성요소 의미와 사용 방식은 § 3.2 구문을 참고하십시오.
-
term이 null이면 null 반환.
-
decoded bytes에 퍼센트 디코딩 term 결과를 둔다.
-
decoded bytes에 BOM 없는 UTF-8 디코딩을 실행한 결과를 반환.
본 알고리즘은 하나의 텍스트 지시문 문자열(e.g. "prefix-,foo,bar")을 받아 그 구성 요소(e.g. ("prefix", "foo", "bar", null))로 파싱합니다. 각 구성요소 의미와 사용 방식은 § 3.2 구문을 참고.
입력이 유효하지 않으면 null 반환, 유효하면 텍스트 지시문 반환.
-
prefix, suffix, start, end를 모두 null로 둔다.
-
Assert: text directive value는 ASCII 문자열이며 fragment percent-encode set의 코드포인트도 없고 U+0026 (&)도 없음.
-
tokens를 list로 하고, strictly split text directive value on U+002C(,).
-
tokens의 size가 1 미만 또는 4 초과면 null 반환.
-
tokens[0]이 U+002D(-)로 끝나면:
-
tokens 마지막 항목이 U+002D(-)로 시작하면:
-
tokens size가 2 초과면 null 반환.
-
start에 tokens의 첫 항목 저장.
-
첫 항목 삭제.
-
start가 빈 문자열이거나 U+002D(-)를 포함하면 null 반환.
-
tokens가 empty가 아니면:
-
end에 첫 항목 저장.
-
end가 빈 문자열이거나 U+002D(-)를 포함하면 null 반환.
-
-
다음 값으로 새 텍스트 지시문 반환:
조각 지시문 파싱 알고리즘(입력 ASCII 문자열 fragment directive):
-
directives에 strictly split fragment directive on U+0026(&).
-
output을 빈 텍스트 지시문 리스트로 둔다.
-
-
directive가 "
text="로 시작하지 않으면 continue -
text directive value를 부분 문자열(인덱스 5 ~ 끝)을 저장합니다.
Note: 이 값은 빈 문자열도 될 수 있음. -
parsed text directive에 파싱 text directive value 결과를 저장.
-
parsed text directive가 null이 아니면 output 리스트에 추가
-
-
output을 반환한다.
3.4.1. 텍스트 지시문 호출
이 섹션은 문서의 보류 중인 텍스트 지시문에 포함된 텍스트 지시문이 어떻게 처리되고, 관련 텍스트 구절의 강조(Indication)를 유발하는지 설명합니다.
-
지시된 부분(indicated part) 처리 모델을 수정하여, 보류 중인 텍스트 지시문을 range로 처리하고 해당 range가 지시된 부분으로 반환되도록 함.
-
"조각으로 스크롤" 동작을 수정하여, range 기반의 지시된 부분의 경우 올바르게 스크롤하고 Document의 target element를 설정함.
-
보류 중인 텍스트 지시문이, 현재 내비게이션/이동의 조각 검색이 끝났을 때 null로 리셋되는지 확인.
-
사용자 에이전트가 텍스트 지시문 검색을 마치면 fallback으로 일반 프래그먼트도 시도하게 함.
지시된 부분에서, 프래그먼트가 range를 나타내도록 허용. 다음과 같이 변경:
Monkeypatching HTML § 7.4.6.3 조각으로 스크롤:
HTML 문서 document의 지시된 부분을 결정하기 위한 처리 모델은 다음과 같음:
text directives를 document의 보류 중인 텍스트 지시문으로 설정.
text directives가 null이 아니면:
ranges를 리스트로 하고, 텍스트 지시문 호출 단계(text directives, document)를 실행한 결과로 둠.
ranges가 비어 있지 않으면:
firstRange를 ranges의 첫 아이템으로 둠.
ranges의 각 range를 구현 정의 방식으로 시각적으로 표시. 이 표시는 author script에서는 관찰할 수 없어야 함. 자세한 사항은 § 3.7 텍스트 일치 표시 참고.
ranges의 첫 range가 스크롤 대상이 되지만 모든 범위가 시각적으로 표시되어야 한다는 점 주의.firstRange를 document의 지시된 부분으로 설정하고, 반환.
fragment를 document의 URL의 fragment로 둔다.
fragment가 빈 문자열이면, 문서 맨 위(top of the document) 특수값을 반환.
potentialIndicatedElement를 document와 fragment로 potential indicated element 찾기 결과로 둔다.
...
프래그먼트로 스크롤에서는 지시된 부분이 range일 수 있고, force-load-at-top 정책 적용 시 프래그먼트 스크롤을 방지하도록 처리. 다음과 같이 변경:
Monkeypatching HTML § 7.4.6.3 조각으로 스크롤:
document의 indicated part가 null이면 document의 target element를 null로 설정.
그렇지 않고 indicated part가 문서 맨 위(top)이면:
document의 target element를 null로 설정.
문서의 맨 처음으로 스크롤.
return.
그 외:
assertion: document의 indicated part는 element이거나 range임.
scrollTarget을 document의 indicated part로 둠.
target에 scrollTarget을 복사.
target이 range이면:
target을 first common ancestor(start node, end node)로 설정.
target이 null이 아니면서 element가 아니면 target의 parent로 target 갱신하며 반복.
만약 shadow tree 내부라면 target을 어떻게 잡아야 하는가?#190assertion: target은 element임.
document의 target element를 target으로 설정.
ancestor details revealing algorithm을 target으로 실행.
ancestor hidden-until-found revealing algorithm을 target으로 실행.
해당 알고리즘은 target이 ancestor나 루트 document node일 수도 있어 정상 동작하지 않을 수 있음. #89 참조.contain:style layout블록으로 제한하면 해결될 수 있음.blockPosition은 scrollTarget이 range면 "center", 아니면 "start"로
텍스트 지시문으로 이동 시 block flow에서 중앙에 맞춰짐(center).target을 "auto"/"start"/"nearest"로 into view.- scroll a target into view, target = scrollTarget, behavior="auto", block=blockPosition, inline="nearest"
구현체는 text directive에서 나온 target의 경우 스크롤을 생략할 수 있음.
target에서 focusing steps 실행, 실패 시 문서 viewport fallback.
연속 포커스 네비게이션 시작 지점을 target으로 이동.
아래 두 개의 몽키패치는 fragment 검색 종료 시 보류 중인 텍스트 지시문이 반드시 null로처리됨을 보장합니다. 텍스트 지시문 탐색이 파싱 종료로 끝나면, 마지막으로 일반 프래그먼트도 재시도합니다.
try to scroll to the fragment 정의에서:
Monkeypatching HTML § 7.4.6.3 조각으로 스크롤:
Document document에 대해 fragment로 스크롤을 시도할 때, 병렬로 다음 단계 실행:
구현 정의 시간만큼 대기 (성능 최적화를 위한 user experience 확보 목적).
document의 relevant global object로 navigation and traversal task source에 글로벌 task를 큐잉해서 다음 실행:
document에 파서 없거나 파싱 중지, 혹은 스크롤 의도가 사라지도 abort.- 사용자 에이전트가 더 이상 스크롤 의지가 없다고 판단하면:
보류 중인 텍스트 지시문을 null로.
이후 단계는 중단(abort).
문서에 파서가 없거나 파서가 중지된 경우:
보류 중인 텍스트 지시문이 null이 아니면:
보류 중인 텍스트 지시문을 null로.
프래그먼트로 스크롤(document) 실행.
이후 단계는 중단(abort).
문서에 대해 fragment로 스크롤 실행.
indicated part가 여전히 null이면 fragment로 스크롤 재시도. else 보류 중인 텍스트 지시문을 null로.
navigate to a fragment 정의에서:
Monkeypatching HTML § 7.4.2.3.3 조각 탐색:
navigable navigable, ...로 조각 탐색 시:
...
- Update document for history step application(navigable의 active document, historyEntry, true, scriptHistoryIndex, scriptHistoryLength)
navigable의 active document에 대해 fragment로 스크롤.
- navigable의 active document의 보류 중인 텍스트 지시문을 null로.
traversable을 navigable의 traversable navigable로.
...
지시된 부분으로 스크롤하는 것은 "scroll to the fragment"에서 일어나는 여러 동작 중 하나일 뿐이다. 이에 따라, 관련 정의를 "조각 표시"로 리네임:
Monkeypatching HTML § 7.4.2.3.3 조각 탐색:
HTML § 7.4.2.3.3 조각 탐색 및 관련 단계를 모두 "조각 표시(indicating a fragment)"로 명칭 변경하여 더 포괄적인 효과를 반영.
3.5. 보안 및 프라이버시
3.5.1. 동기(motivation)
텍스트 지시문을 구현할 때 교차 오리진 정보 유출에 사용되지 않도록 주의해야 합니다. 스크립트는 cross-origin URL에 텍스트 지시문을 포함하여 페이지를 탐색시킬 수 있습니다. 악의적 행위자가 해당 navigation 결과로 피해 페이지에서 텍스트 조각이 실제로 발견됐음을 알 수 있다면, 페이지의 특정 텍스트 존재 여부를 유추할 수 있습니다.
아래 하위 섹션의 처리 모델은 예상 공격 벡터를 완화하도록 제한합니다. 요약하면, 텍스트 지시문은 다음에 한정됨:
-
최상위 내비게이블(top level navigables, 즉 iframe 안 아님).
-
이 부분은 완전히 정확하진 않음. 크롬은 same-origin 시작자에 대해 허용함. 명세 보완 필요. [이슈 #WICG/scroll-to-text-fragment#240]
-
-
사용자 행위로 인한 navigation에서만 허용
-
navigation 시작자가 cross-origin인 경우, 목적지는 opener isolated(즉, 다른 문서에서 해당 global object를 참조 불가)이어야 함
3.5.2. 탐색 시 스크롤
UA는 일치하는 텍스트 구절을 자동으로 시야로 스크롤해줄 수 있습니다. 사용성 측면에선 편리하지만 구현시 주의할 보안 리스크도 있습니다.
내비게이션 시 스크롤이 발생한 사실이 자연스러운 사용자 스크롤과 구분되어 감지될 가능성이 알려진 사례(혹은 잠재적 방법)가 있습니다.
이처럼 알려진 케이스는 타깃 페이지의 특수한 상황에서만 성립하므로 일반적으로 적용되는 건 아님. 텍스트 조각의 호출 조건을 더 제한하면 공격 여지가 더욱 좁아집니다. 다만, 여러 UA(브라우저)마다 위험 허용 기준이 다를 수 있으므로, 스크롤 동작 여부는 UA마다 개별적으로 고려해야 함.
표준 준수 UA는 내비게이션 시 자동 스크롤을 하지 않을 수도 있습니다. 대신 "클릭 시 스크롤" 같은 UI 혹은 아무런 동작도 제공하지 않을 수 있습니다. 이 경우에는 지시 대상 구절이 아래에 존재함을 사용자에게 알려주는 방식이 적합합니다.
위 예시에서 특정 상황에선 공격자가 페이지의 콘텐츠에 대해 1bit의 정보를 추출할 수 있지만, 반복공격으로 임의의 내용을 추출할 수 없도록 방어해야 함. 이를 위해 사용자 활성화 조건, 브라우징 컨텍스트 격리를 반드시 구현해야 함.
또한, 해당 그룹 내 유일 브라우징 컨텍스트면(top level browsing context, 즉 전체 탭/윈도우)이므로, 악의적 사용 은폐도 어렵게 함.
UA가 자동 스크롤을 선택한다면, 반드시 문서가 백그라운드(비활성 탭 등)일 때는 스크롤이 일어나지 않게 해야 합니다. 이를 통해 비정상적 자동 탐색 시도를 사용자가 인지할 수 있고, 백그라운드 조작 공격도 방지할 수 있습니다.
UA가 자동 스크롤을 하지 않기로 할 경우, 텍스트 조각 일치 여부에 상관없이 제공된 fallback element-id는 반드시 시야로 스크롤해야 합니다. 스크롤 여부만으로 텍스트 조각 일치 여부가 감지되는 것을 막기 위함입니다.
3.5.3. 검색 타이밍
텍스트 검색 알고리즘을 단순히 구현하면 매칭/비매칭 쿼리의 실행시간 차이로 정보 유출이 가능해질 수 있습니다. 공격자가 텍스트 지시문 URL로 동기 탐색을 유도해 내비게이션 콜의 소요시간 차이로 텍스트 존재 여부를 파악할 수 있습니다.
즉, UA 구현체는 § 3.6 텍스트 조각으로의 탐색 각 단계의 runtime이 매칭 성공/실패에 따라 달라지지 않도록 보장해야 함.
구체적 방법은 본 명세에서 규정하지 않음. 예를 들어 UA는 텍스트 지시문 범위 찾기 함수에서 일치 후에도 계속 트리를 순회하거나, 또는 비동기 태스크로 찾고 Document의 indicated part를 나중에 설정하는 등의 방법이 있음.
3.5.4. 텍스트 조각 제한
-
Document와 Request 모두에 불리언
text directive user activation을 추가. 이 플래그는 사용자 활성화 내비게이션에서 작성된 문서에 설정되고, 텍스트 지시문이 스크롤될 때 소비됩니다. 소비되지 않으면 아웃고잉 내비게이션 요청에 전달될 수 있습니다. 아래 note에서 설명한 user-activation-through-redirects 동작을 구현합니다. -
문서와 내비게이션의 사용자 참여 및 시작 오리진 상태에 대해 일련의 체크를 정의하여, 텍스트 지시문이 스크롤을 수행할 수 있을지 결정합니다.
-
"finalize a cross document navigation", "navigate to a fragment steps"에서 스크롤 권한을 계산하고, "scroll to the fragment" 단계까지 전달하여, 텍스트 지시문 스크롤을 중단하는 데 사용합니다.
request와 Document 정의에 새로운 불리언 text directive user activation 필드를 포함:
Monkeypatching [FETCH]:
request는 관련 불리언 text directive user activation을 가집니다. 기본값은 false입니다.
Monkeypatching [HTML]:
각 Document는 text directive user activation이라는 불리언을 가집니다. 초깃값은 false입니다.
text directive user activation은 텍스트 조각의 단일 활성화를 허용하는 사용자 제스처 신호를 제공합니다. 문서가 로드될 때 내비게이션이 사용자 활성화로 인해 발생한 경우 true로 설정되며, 클라이언트 측 리디렉션에서도 전달됩니다.만약 Document의 text directive user activation이 텍스트 조각 활성화에 사용되지 않으면, 대신 새 내비게이션 request의 text directive user activation을 true로 설정하는 데 사용됩니다. 이 방식으로 text directive user activation은 한 내비게이션에서 다른 내비게이션으로 전달될 수 있습니다.
Document의 text directive user activation과 request의 text directive user activation은 사용 시 항상 false로 설정되어, 단일 사용자 활성화로 두 개 이상의 텍스트 조각을 활성화할 수 없습니다.
이 메커니즘은 텍스트 조각이 많은 웹 사이트에서 사용하는 일반적인 리디렉션을 통해 활성화될 수 있도록 합니다. 이런 사이트는 200 status code와 함께 window.location 을 설정하는 스크립트를 반환하여 사용자를 의도한 목적지로 리디렉션합니다.
실제 HTTP (
status 3xx
) 리디렉션과 달리, 이러한 "클라이언트 측"
리디렉션은 내비게이션이 사용자 제스처 결과임을 전달할 수 없습니다. text directive user activation 메커니즘은 이 경우에
한정된 user-activation의 전달을 가능하게 합니다.
이는 페이지가 프로그래밍적으로 텍스트 조각에 한 번 한정해 사용자 제스처처럼 내비게이션하게 합니다. 그러나 text fragment user
activation은 초기화되므로 추가적인 텍스트 조각 내비게이션은 새 사용자 제스처 없이는 불가능합니다.
아래 다이어그램은 클라이언트 측 리디렉션을 통한 텍스트 조각 활성화에 flag가 어떻게 쓰이는지 보여줍니다:
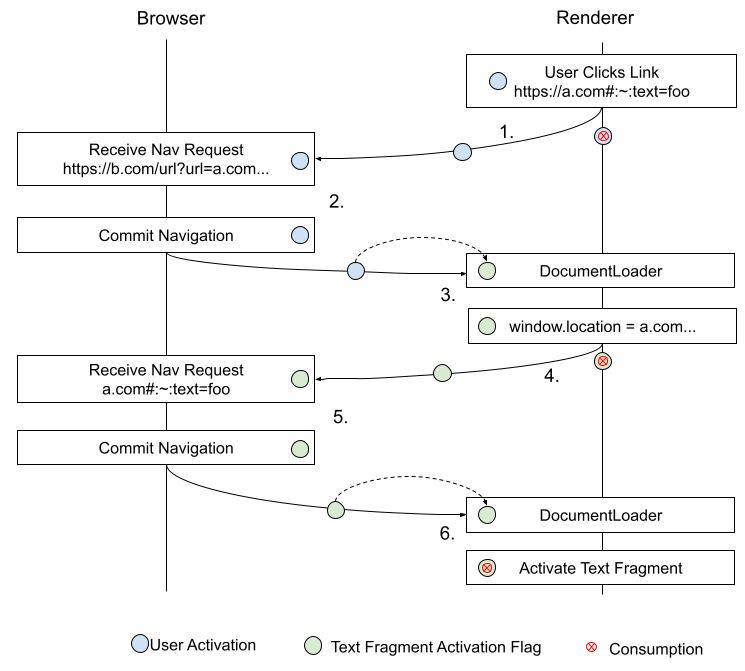
보다 심층적인 논의는 redirects.md 참고.
create navigation params by fetching 단계에서 active document의 text directive user activation 값을 request의 text directive user activation으로 전달.
Monkeypatching [HTML]:
이 코드는 병렬로 실행됩니다.
documentResource를 entry의 document state의 resource로 둡니다.
request를 새 request로 생성, 다음으로 설정
- url
- entry의 URL
- ...
- ...
- referrer policy
- entry의 document state의 request referrer policy
- text directive user activation
- navigable의 active document의 text directive user activation
navigable의 active document의 text directive user activation을 false로 설정.
documentResource가 POST resource이면:
...
navigation params 정의에 새 필드 추가:
Monkeypatching [HTML]:
- user involvement
- user navigation involvement 값.
navigation params가 어디서든 생성되는 곳에서 user involvement 값 초기화. 구체적으로는 create navigation params by fetching 케이스에서 true로 초기화:
Monkeypatching [HTML]:
To create navigation params by fetching given a session history entry entry, a navigable navigable, a source snapshot params sourceSnapshotParams, a target snapshot params targetSnapshotParams, a string cspNavigationType, a navigation ID-or-null navigationId, a NavigationTimingType navTimingType, 그리고 user navigation involvement user involvement, 다음 단계를 진행. navigation params, non-fetch scheme navigation params 또는 null을 반환
이 코드는 병렬로 실행됨.
...
- resultPolicyContainer를 response의 URL, entry의 document state의 history policy container, sourceSnapshotParams의 source policy container, null, responsePolicyContainer로 결정
navigable의 컨테이너가 iframe이고 response의 timing allow passed flag가 설정된 경우 컨테이너의 pending resource-timing start time을 null로.
navigation params를 새로 생성하여 반환:
- id
- navigationId
- ...
- ...
- about base URL
- entry의 document state의 about base URL
- user involvement
- user involvement
create and initialize a Document object 단계를 수정하여 text directive user activation 플래그를 계산 및 저장:
Monkeypatching [HTML]:
navigationParams의 response, "pre-media"로 document에 link headers를 처리.
navigationParams의 user involvement가 "
activation"일 때navigationParams의 user involvement가 "
browser UI"일 때navigationParams의 request의 text directive user activation이 true일 때
text directive user activation은 복사 불가해야 하므로, 한 번의 user-activated navigation마다 단가(text fragment)만 활성화.document 반환
text
directive allowing MIME type은 MIME type인데, essence가 "text/html" 또는 "text/plain"입니다.
참고: scrolling to a fragment, fragment processing은 MIME type마다 별도 정의됨. 이 때문에 scroll to the fragment 단계에서 텍스트 지시문 스크롤 처리는 text/html에서만 적용되어야 함. 다만 실 브라우저는 HTML fragment 처리 로직을 text/plain에도 적용하는 경향이 있음(ID 가진 element 추가시 text/plain에서도 fragment-id 스크롤 동작 등). 실질적으로 text/plain에서 텍스트 지시문 활성화도 유용함. 기타 타입은 XS-Search 등 민감 데이터 공격 가능성 때문에 명확히 금지됩니다(ex: text/css, application/json, application/javascript 등).
-
document의 보류 중인 텍스트 지시문이 null이거나 empty이면 false 반환.
-
is user involved를 true로 둠: document의 text directive user activation이 true이거나, user involvement가 "
activation" 또는 "browser UI"일 때. 아니면 false. -
document의 text directive user activation을 false로.
-
document의 content type이 text directive allowing MIME type이 아니면 false 반환.
-
user involvement가 "
browser UI"면 true 반환.내비게이션이 브라우저 UI에서 시작되면 무조건 허용. 사용자가 직접 트리거한 것이고 페이지/스크립트가 텍스트 스니펫을 제공하지 않음.
본 항목의 취지는 앱/페이지 측에서 URL을 제어할 수 있는 경우와 사용자가 완전히 제어하는 경우를 구분하기 위함. 전자는 스크립트가 텍스트 조각과 부작용(사이드이펙트) 모두 갖기에 cross-origin 시 그룹 분리된 브라우징 컨텍스트에서만 허용 필요. 새 창으로 열기 등 일부 browser UI 동작은 부분적으로 예외일 수 있음.
관련 논의는 sec-fetch-site 및 [FETCH-METADATA] 참고.
-
is user involved가 false면 false 반환.
-
document의 node navigable에 parent가 있으면 false 반환.
-
initiator origin이 non-null이고 document의 origin이 same origin이면 true 반환.
-
document의 browsing context의 group의 browsing context set 길이가 1이면 true 반환.
즉, cross-origin element/script에서 시작될 때는 문서가 noopener 컨텍스트(새 top level browsing context group, script 접근없는 새 프로세스)로 열렸을 때만 허용. -
아니면 false 반환.
scroll to the fragment 단계를 수정하여 불리언 allow text directive scroll 파라미터 추가:
Monkeypatching HTML § 7.4.6.3 조각으로 스크롤:
Document document 및 불리언 allow text directive scroll를 인자로 fragment로 스크롤할 때:
document의 indicated part가 null이면 target element를 null로.
...
그 외:
assertion: indicated part는 element이거나 range임.
...
- target이 range라면:
allow text directive scroll이 false면 return.
target을 first common ancestor(start node, end node)로.
...
try to scroll to the fragment에 불리언 allow text directive scroll 플래그를 추가하고, step 2에서 큐잉되는 태스크 내용을 대체:
Monkeypatching [HTML]:
Document document, 불리언 allow text directive scroll으로 fragment로 스크롤 시 병렬로 다음 단계:
구현 정의 시간만큼 대기(사용자 경험 최적화 목적).
document의 relevant global object로 navigation and traversal task 소스에 글로벌 태스크 큐잉, 다음 단계 수행:
parser가 없거나, 파서가 중단되었거나, 스크롤을 원치 않는 상황이면 중단.
fragment로 스크롤(document, allow text directive scroll).
indicated part가 여전히 null이면 fragment로 스크롤(document, allow text directive scroll) 재시도.
update document for history step application 단계에 불리언 allow text directive scroll 파라미터를 받아 fragment로 스크롤 시 사용:
Monkeypatching [HTML]:
Document document, session history entry entry, 불리언 doNotReactivate, 정수 scriptHistoryLength, 정수 scriptHistoryIndex, (optional) session history entry 리스트 entriesForNavigationAPI, 불리언 allow text directive scroll 인자로 history step 적용:
documentIsNew를 document의 latest entry가 null이면 true, 아니면 false로.
...
- documentsEntryChanged가 true면:
oldURL을 document의 latest entry의 URL로.
...
documentIsNew가 true라면:
fragment로 스크롤(document, allow text directive scroll).
apply the history step 알고리즘에 불리언 allow text directive scroll를 받아, update document for history step application 호출 시 전달:
Monkeypatching [HTML]:
apply the history step를 step, traversable, 불리언 checkForCancelation, sourceSnapshotParams-or-null sourceSnapshotParams, navigable-or-null initiatorToCheck, user navigation involvement-or-null userInvolvementForNavigateEvents, 불리언 allow text directive scroll (기본값 false)와 함께 호출 시 아래 단계. 리턴값: "initiator-disallowed", "canceled-by-beforeunload", "canceled-by-navigate", "applied".
completedChangeJobs ≠ totalChangeJobs 동안 반복:
...
- navigable의 active window로 글로벌 태스크 큐잉, 단계:
changingNavigableContinuation의 update-only가 false면:
...
history entry targetEntry를 activiate.
updateDocument를 update document for history step application(targetEntry의 document, targetEntry, changingNavigableContinuation의 update-only, scriptHistoryLength, scriptHistoryIndex, entriesForNavigationAPI, allow text directive scroll)로 수행.
targetEntry의 document = displayedDocument라면 updateDocument 수행.
totalNonchangingJobs를 nonchangingNavigablesThatStillNeedUpdates의 크기로.
apply the push/replace history step에서 allow text directive scrolling를 받아 apply the history step에 전달:
Monkeypatching [HTML]:
apply the push/replace history step를 step, traversable traversable, 불리언 allow text directive scroll (기본값 false) 인자로 호출:apply the history step(step, traversable, false, null, null, null, allow text directive scroll)의 결과를 반환.
참고: allow text directive scroll은 traversal, reload시 의도적으로 설정되지 않습니다. initiator origin, user involvement, history scroll state 체크를 모두 반복할 필요를 피하고, history scroll state가 더 중요하기 때문입니다. 이 경우에도 지시문의 하이라이트 복원은 계속 가능합니다.
finalize a cross-document navigation을 수정하여 user involvement 파라미터를 받아 allow text directive scrolling을 계산해서 apply the push/replace history step에 전달:
Monkeypatching [HTML]:
finalize a cross-document navigation을 navigable, historyHandling, historyEntry, 그리고 user navigation involvement user involvement (기본값 "none") 인자로 호출:
이 코드는 navigable의 traversable navigable의 session history traversal queue에서 실행됨.
...
- allow text directive scroll을 텍스트 지시문 스크롤 허용 체크(historyEntry의 document, historyEntry의 document state의 initiator origin, user involvement)로 결정
apply the push/replace history step targetStep(traversable, allow text directive scroll) 실행.
navigate 알고리즘을 수정하여 finalize a cross-document navigation 단계로 user involvement을 전달:
Monkeypatching [HTML]:
...
- . 병렬로 다음 단계 수행:
...
- . historyEntry의 document를 채우는 단계서, navigable, "navigate", sourceSnapshotParams, targetSnapshotParams, navigationId, navigationParams, cspNavigationType, allowPOST true, completionSteps를 아래로:
navigable의 traversable로 session history traversal steps에 finalize a cross-document navigation(navigable, historyHandling, historyEntry, userInvolvement) 추가.
Navigate to a fragment 알고리즘을 수정하여 initiator origin을 받아, fragment로 스크롤 시 allow text directive scroll 플래그 전달:
Monkeypatching [HTML]:
navigate to a fragment(navigable, url, historyHandling, userInvolvement, navigationAPIState, navigationId, origin initiator origin):
navigation을 navigable의 active window의 navigation API로.
...
- update document for history step application(navigable의 active document, historyEntry, true, scriptHistoryIndex, scriptHistoryLength)
same-document navigation API entry 업데이트(navigation, historyEntry, historyHandling)
allow text directive scroll을 텍스트 지시문 스크롤 허용 체크(navigable의 active document, initiator origin, userInvolvement)로 결정
fragment로 스크롤(navigable의 active document, allow text directive scroll)
navigate 알고리즘을 수정하여 fragment navigation 수행 시 initiator origin도 전달하도록:
Monkeypatching [HTML]:
url과 navigable의 active document로 replace 필요 여부 결정.
아래가 모두 true라면:
documentResource가 null
response가 null
url이 navigable의 active session history entry의 URL(프래그먼트 제외)와 동일
url의 fragment는 non-null
then:
navigate to a fragment(navigable, url, historyHandling, userInvolvement, navigationAPIState, navigationId, initiatorOriginSnapshot)
navigation을 navigable의 active window의 navigation API로.
3.5.5. 로드 시 스크롤 제한
이 섹션은 force-load-at-top 정책이 새 문서를 불러올 때 텍스트 지시문을 포함하여 모든 종류의 스크롤을 방지하는 방법을 정의합니다.
force-load-at-top이 Navigation API와 어떻게 상호작용하는지 결정 필요. [Issue
#WICG/scroll-to-text-fragment#242]
restore persisted state 절차를 수정하여, 스크롤 복원을 억제하는 새 불리언 파라미터를 받게 합니다:
Monkeypatching [HTML]:
restore persisted state를 session history entry entry , 그리고 불리언 suppressScrolling으로:
entry의 scroll restoration mode가 "auto"이고, suppressScrolling이 false이며, entry의 document의 relevant global object의 navigation API의 suppress normal scroll restoration during ongoing navigation이 false이면, entry로 scroll position data 복원.
...
update document for history step
application 절차를 수정하여, 새 문서에서 force-load-at-top 정책을 체크하고 설정 시 스크롤을 수행하지 않도록 합니다.
Monkeypatching [HTML]:
...
- document의 history object의 length를 scriptHistoryLength로 설정.
scrollingBlockedInNewDocument을 해당 정책 값 조회(
force-load-at-top, document) 결과로 둠.documentsEntryChanged가 true라면:
oldURL을 document의 latest entry의 URL로 둠.
...
- documentIsNew가 false면:
same-document navigation의 navigation API entry를 navigation, entry, "traverse"로 업데이트.
popstate 이벤트 발생...
entry 및 suppressScrolling false로 restore persisted state 실행.
oldURL의 fragment가 ...와 다르면
그 외,
entriesForNavigationAPI가 제공됨을 assert.
entry 및 scrollingBlockedInNewDocument로 restore persisted state 실행.
새 문서용 navigation API entry를 navigation, entriesForNavigationAPI, entry로 초기화.
documentIsNew가 true면:
scrollingBlockedInNewDocument가 false면, document에 대해 fragment로 스크롤 시도.
이 시점에 새로 생성된 문서에 대해 스크립트가 실행될 수 있음.
그 외 documentsEntryChanged가 false이고 doNotReactivate가 false면:
...
3.6. 텍스트 조각으로 이동
-
commonAncestor를 nodeA로 둡니다.
-
commonAncestor가 null이 아니고 shadow-including inclusive ancestor가 nodeB가 아니면 commonAncestor를 shadow-including parent로 업데이트.
-
commonAncestor를 반환.
-
node가 shadow root이면 node의 host를 반환.
-
그 외엔 node의 parent를 반환.
3.6.1. 문서 내 범위 찾기
고수준에서 조각 지시문 문자열을 예시처럼 받습니다:
text=prefix-,foo&unknown&text=bar,baz
이를 개별 텍스트 지시문으로 쪼갭니다:
text=prefix-,foo text=bar,baz
각 텍스트 지시문마다 문서 내에서 해당 지시문 조건에 맞는 렌더드 텍스트의 첫 사례를 검색합니다. 각 검색은 서로 독립적이며, 몇 개 지시문이 주어졌거나 일치 결과에 따라 결과가 달라지지 않습니다.
지시문이 문서 내 텍스트와 일치하면, 해당 일치 범위를 나타내는 range를 반환합니다. invoke text directives 단계가 이 섹션의 상위 API이며, fragment 지시문 문자열에 지정된 순서대로 각 지시문 개별 매칭 단계를 돌려서 매칭된 range 리스트를 반환합니다.
일치하지 않은 지시문은 반환 리스트에 항목을 추가하지 않습니다.
-
ranges를 empty 리스트로 둠.
-
-
find a range from a text directive(directive, document) 결과가 null이 아니면 ranges에 append.
-
-
ranges를 반환.
end가 null이면 "정확 일치"이며 반환되는 range는 start와 문자열만 일치. end가 있으면 "범위 검색"으로, 반환 range는 start부터 end까지. 이하 모든 모드에서 "일치 텍스트"라 통칭.
prefix, suffix는 null 허용(해당 쪽 문맥 무시). 예: prefix가 null이면 앞쪽 무관.
-
searchRange를 range로 생성, start는 (document, 0), end는 (document, document의 length)
-
searchRange가 collapsed가 아닐 때까지:
-
potentialMatch를 null로 둔다.
-
parsedValues의 prefix가 null이 아니면:
-
prefixMatch를 find a string in range (query=parsedValues의 prefix, searchRange, wordStartBounded=true, wordEndBounded=false) 실행 결과로 설정
-
prefixMatch가 null이면 null 반환.
-
searchRange의 start를 prefixMatch의 boundary point after로 이동
-
matchRange를 start=prefixMatch의 end, end=searchRange의 end로 하는 range로
-
matchRange의 start를 next non-whitespace position으로 이동
-
matchRange가 collapsed이면 null 반환.
prefixMatch end나, 후행 non-whitespace가 문서 끝이면 이 상황 발생. -
Assert: matchRange의 start node는
Text노드임.이제 matchRange의 start는 matched prefix 직후의 non-whitespace에 위치. -
mustEndAtWordBoundary를, parsedValues의 end가 null이 아니거나 parsedValues의 suffix가 null이면 true, 아니면 false.
-
potentialMatch를 find a string in range(parsedValues의 start, searchRange, matchRange, wordStartBounded=false, wordEndBounded=mustEndAtWordBoundary) 결과로 설정
-
potentialMatch가 null이면 null 반환.
-
potentialMatch의 start가 matchRange의 start와 다르면 계속
이 경우 prefix는 맞지만 뒤가 원하는 텍스트가 아니라 다음 prefix를 다시 찾기 위해 continue.
-
-
그 외:
-
mustEndAtWordBoundary를 parsedValues의 end가 null이 아니거나 parsedValues의 suffix가 null이면 true, 아니면 false.
-
potentialMatch를 find a string in range(parsedValues의 start, searchRange, searchRange, wordStartBounded=true, wordEndBounded=mustEndAtWordBoundary) 결과로 설정.
-
potentialMatch가 null이면 null 반환.
-
searchRange의 start를 potentialMatch의 boundary point after로 이동.
-
-
rangeEndSearchRange를 start=potentialMatch의 end, end=searchRange의 end로 하는 range로 설정.
-
rangeEndSearchRange가 collapsed가 아닐 때까지:
-
parsedValues의 end가 null이 아니면:
-
mustEndAtWordBoundary를 parsedValues의 suffix가 null이면 true, 아니면 false.
-
endMatch를 find a string in range(parsedValues의 end, searchRange, rangeEndSearchRange, wordStartBounded=true, wordEndBounded=mustEndAtWordBoundary) 결과로
-
endMatch가 null이면 null 반환.
-
-
Assert: potentialMatch는 null 아님, collapsed 아님, 정확히 매칭 텍스트 범위를 나타냄.
-
parsedValues의 suffix 가 null이면 potentialMatch 반환.
-
suffixRange를 start=potentialMatch의 end, end=searchRange의 end인 range로
-
suffixRange의 start를 next non-whitespace position으로 이동.
-
suffixMatch를 find a string in range(parsedValues의 suffix, searchRange, suffixRange, wordStartBounded=false, wordEndBounded=true) 결과로
-
suffixMatch가 null이면 null 반환.
suffix가 문서 남은 부분에 없으면 일치 불가. -
suffixMatch의 start가 suffixRange의 start와 같으면 potentialMatch 반환.
-
parsedValues의 end가 null이면 break;
정확 일치에서 suffix가 안 맞으면 inner loop에서 break(outer는 계속). 범위검색이면 end가 맞는지 계속 진행. -
rangeEndSearchRange의 start를 potentialMatch의 end로 갱신.
이 경우 시작 범위는 맞췄으나, 정확 종료 범위는 못 맞췄다는 뜻. inner loop 계속하며 rangeEnd 추가 매칭 검색.
-
-
rangeEndSearchRange가 collapsed라면:
-
-
null 반환
-
range가 collapsed되지 않은 동안:
-
node를 range의 start node로 둡니다.
-
offset을 range의 start offset으로 둡니다.
-
node가 검색 불가 서브트리의 일부이거나 node 가 가시 텍스트 노드가 아니거나 offset이 node의 length와 같으면:
-
range의 start node를 그림자-포함 순서의 다음 노드로 설정합니다.
-
range의 start offset을 0으로 설정합니다.
-
계속.
-
-
node의 offset offset 위치에서 6자를 substring data로 가져와 " "와 같다면:
-
range의 start offset에 6을 더합니다.
-
-
그 외에 substring data의 5자가 " "라면:
-
range의 start offset에 5를 더합니다.
-
-
그 외의 경우:
-
cp에 White_Space 속성이 없다면, 리턴.
-
range의 start offset에 1을 더합니다.
-
본 알고리즘의 기본 전제는 블록 내의 모든 검색 가능 텍스트 노드를 검사하여 리스트로 수집함. 이 리스트를 하나의 문자열로 합쳐 그 안에서 검색을 수행. 노드 리스트를 이용해 오프셋 등 계산, 결국 range를 반환.
노드 수집은 블록 노드를 만나면 종료되며, 예시 트리에서:
<div> a<em>b</em>c<div>d</div>e </div>
위 구조라면 "abc"에서 먼저 검색, 이어 "d"와 "e"에서 따로 검색됨.
즉, query는 단일 블록 컨테이너 안에서 연속(중단 없는) 텍스트만 일치 가능.
-
searchRange가 collapsed 상태가 아닌 동안:
-
curNode를 searchRange의 start node로 둠.
-
curNode가 검색 불가 서브트리의 일부라면:
-
searchRange의 start node를 그림자-포함 트리 순서상 curNode의 shadow-including descendant가 아닌 다음 노드로.
-
searchRange의 start offset을 0으로.
-
계속.
-
-
curNode가 가시 텍스트 노드가 아니라면:
-
searchRange의 start node를 다음 그림자-포함 순서의, doctype이 아닌 노드로.
-
searchRange의 start offset을 0으로.
-
계속.
-
-
blockAncestor를 가장 근접한 블록 조상으로.
-
textNodeList를 Text 노드 리스트(빈값)로.
-
curNode가 blockAncestor의 그림자-포함 자손이고, 경계 지점(curNode, 0)이 searchRange의 end 뒤가 아닐 때까지 반복:
-
노드 리스트에서 범위 찾기(query, searchRange, textNodeList, wordStartBounded, wordEndBounded) 실행 결과가 null이 아니면 반환.
-
curNode가 null이면 break.
-
Assert: curNode가 searchRange의 start node 이후임.
-
-
null 반환.
노드가 검색 비가시 노드임은 해당 노드가 element이고 HTML 네임스페이스에 속하며 다음 조건 중 하나라도 만족할 때입니다:
-
노드가 void로 직렬화되는 경우.
-
다음 타입에 해당하는 경우:
HTMLIFrameElement,HTMLImageElement,HTMLMeterElement,HTMLObjectElement,HTMLProgressElement,HTMLStyleElement,HTMLScriptElement,HTMLVideoElement,HTMLAudioElement
노드가 검색 불가 서브트리 일부임은, 자신 또는 그림자-포함 조상 중에 검색 비가시 노드가 있을 때입니다.
노드는 가시 텍스트 노드임이란,
Text
노드이고, 계산 값 중 부모 요소의 parent element visibility 속성이 visible이고, 해당 노드가 렌더링중일 때입니다.
노드가 블록 레벨 display를 가짐이란, 해당 노드가 element이고 계산 값의 display 값이 block, table, flow-root, grid, flex, list-item 중 하나일 때입니다.
-
curNode를 node로 둡니다.
-
curNode가 null이 아닐 동안
-
curNode가
Text노드가 아니면서 블록 레벨 display가 있으면 curNode 반환. -
그 외엔 curNode를 curNode의 parent로 설정.
-
-
node의 node document의 document element 반환.
-
단어 경계에서만 시작해야 하면 “color orange”에는 매칭되지 않음.
-
단어 경계에서만 끝나야 하면 “forest ranger”에는 매칭되지 않음.
자세한 내용 및 예시는 § 3.6.2 단어 경계 참고.
-
searchBuffer를 nodes의 data를 이어붙인 값으로 저장.
data는 실제로는 DOM에 존재하는 텍스트이며, 명세상은 렌더링된 텍스트로 처리되어야 함(및 Range 변환 필요). [이슈 #WICG/scroll-to-text-fragment#98]
-
searchStart를 0으로 둠.
-
nodes의 첫 번째 항목이 searchRange의 start node라면 searchStart를 searchRange의 start offset으로 설정.
-
start와 end를 경계 지점(null)으로 둠.
-
matchIndex를 null로 둡니다.
-
matchIndex가 null인 동안 반복
-
searchBuffer에서 queryString이 searchStart부터 처음 등장하는 인덱스를 matchIndex로 설정합니다. 문자열 검색은 기본 레벨로, 즉 대소문자/악센트/음표 등 무시로, [UTS10] 참조.
직관적으로, 대소문자 구분 없이 악센트, 변형 등을 무시합니다. -
matchIndex가 null이면 null 반환.
-
endIx를 matchIndex + queryString의 길이로 둠.
endIx는 매칭된 문자열의 마지막 문자 인덱스 + 1. -
start를 경계 지점으로, get boundary point at index(matchIndex, nodes, isEnd=false) 실행 결과로.
-
end를 경계 지점으로, get boundary point at index(endIx, nodes, isEnd=true) 실행 결과로.
-
wordStartBounded가 true이고, searchBuffer에서 matchIndex가 단어 경계가 아니면, start node의 언어를 locale로 사용; 또는 wordEndBounded가 true이고, matchIndex+queryString의 길이가 단어 경계가 아니면, end node의 언어를 locale로 사용:
-
searchStart를 matchIndex + 1로 설정.
-
matchIndex를 null로 설정.
-
-
-
endInset을 0으로 둡니다.
-
nodes 마지막 항목이 searchRange의 end node라면, endInset을 (searchRange의 end node의 length − searchRange의 end offset)으로.
endInset은 마지막 노드의 마지막 위치에서 뒤로 되돌아간 오프셋(범위에 포함되지 않은 노드 부분 길이). -
matchIndex+queryString의 길이가 searchBuffer의 길이 − endInset 초과면 null 반환.
매칭이 검색 범위 끝을 넘으면 null 반환. -
range(start, end)를 반환.
위 알고리즘에서 concatenated string의 인덱스가 어느 노드/위치에 해당하는지 구함.
isEnd는 시작/종료 위치 구분. 종료 인덱스는 "하나 이후" 문자를 가리킴. 만약 매치가 노드 경계에서 종료되면 end offset은 다음 노드의 첫 위치가 아니라 해당 노드 내 마지막 위치여야 함.
3.6.2. 단어 경계
단어 경계는 [UAX29]의 Unicode Text Segmentation § Word_Boundaries에서 정의됩니다. Unicode Text Segmentation § Default_Word_Boundaries는 기본 단어 경계 집합을 정의하지만, 명세상 언급된 것처럼 로케일에 따라 더 정교한 알고리즘을 사용해야 합니다.
사전(dict) 기반 단어 경계 구분은 분리 문자가 없는 로케일(언어)에서 특히 주의해야 합니다. 예컨대 영어에서는 스페이스(' ')로 단어를 구분하지만, 일본어에서는 단어 구분 문자가 없습니다. 이 경우와, 알파벳이 100자 미만인 언어의 경우 사전에 가능한 1글자 단어가 알파벳의 20%를 넘지 않아야 합니다.
로케일은 문자열로, [BCP47] 언어 태그, 또는 빈 문자열이 올 수 있습니다. 빈 문자열은 주언어 미상임을 뜻합니다.
하위 문자열이 로케일 startLocale와 endLocale에서 모두 첫 글자 위치와 마지막 글자 다음 위치가 각각 단어 경계일 때, 문자열 text에서 이 하위 문자열을 단어 경계로 묶인(word bounded)이라고 합니다.
숫자 position이 문자열 text에서 로케일 locale 기준으로 단어 경계에 있으면, 즉 단어 경계가 position번째 코드 유닛 앞에 있거나, text 길이가 0보다 크고 position이 0 또는 길이와 같을 때 단어 경계에 있음이라 정의합니다.
구분 기호(예: 공백)가 있는 언어(영어 등)에선 비교적 직관적이나, 줄바꿈, 하이픈, 따옴표 등 세부 내용은 앞서 언급한 기술문서에서 다룹니다.
중국어/일본어/한국어 등 단어 구분 기호 없는 언어는, 주어진 로케일의 사전을 통해 유효 단어를 판단해야 합니다.
텍스트 조각은 매칭 용어와 주변 문맥이 합쳐졌을 때 단어 경계로 끊겨야만 일치하도록 제한됩니다. 예를 들어, prefix,start,suffix와 같은 정확
매칭에서는 "prefix+start+suffix"가 전체가 단어 경계로 묶여야만 일치합니다. 반면
prefix,start,end,suffix와 같은 범위 매칭에서는 "prefix+start"와 "end+suffix"
모두 단어 경계여야만 일치합니다.
이는 제삼자가 일치하는 토큰 전체를 이미 알고 있어야 한다는 보안을 위한 조치입니다. start,end와 같은 범위 매칭이 두 용어 사이 내부에서 단어 경계를
요구하지 않는다면, 제삼자가 반복 공격으로 토큰(예: "Balance: 123,456 $" 같은)을 한 글자씩 맞춰내려 시도할 수 있기 때문입니다(예:
prefix="Balance: ", end="$" 및 start 변화).
자세한 보안 해설은 Security Review Doc 참고
3.7. 텍스트 일치 표시
UA는 조각으로 스크롤 시도 단계 또는 다른 메커니즘을 통해 텍스트 조각을 시야에 보이게 스크롤할 수 있으나, 반드시 스크롤해야 할 의무는 없습니다.
UA는 매칭된 텍스트가 눈에 띄도록(예: 명도 대비가 큰 하이라이트 등) 시각적으로 표시하여, 사용자가 해당 텍스트 일치를 인식할 수 있도록 해야 합니다.
UA는 사용자가 일치 시각적 표시를 해제(dismiss)할 수 있는 방법을 제공해야 하며, 해제 시 더 이상 매칭된 텍스트가 표시되지 않게 해야 합니다.
시각 효과 및 동작 방식의 구체적인 형태는 UA 구현에 맡깁니다. 그러나, UA는 표시를 위해 Document의 selection과 같은 author script에서 관찰 가능한 방법을 써서는 안 됩니다. 이는 컨텐츠 유출 공격 벡터가 될 수 있습니다.
UA는 제공된 문맥 용어(context term)는 시각적으로 표시해서는 안 됩니다.
인디케이터는 문서 내용에 속하지 않으므로, UA는 인디케이터와 페이지 본문(내용)이 사용자의 관점에서 구분될 수 있도록 처리해야 합니다.
3.7.1. UA 기능의 URL
UA는 문서의 URL을 노출하는 다양한 기능(예: location bar, 북마크 저장 등. window.location 같은 프로그래밍적 API는 제외)을 제공합니다.
사용자 혼동 방지를 위해, UA는 이런 URL에 조각 지시문 포함 여부를 일관되게 처리해야 합니다. 본 절은 UA가 각 상황을 처리하는 기본 원칙 사례를 제시합니다.
동작 일관성 확보를 위한 지침일 뿐, cross-UA 호환에 직접적 영향은 없으므로 엄격한 준수 의무는 아닙니다.
구체적 동작 결정은 각 구현 UA에 맡기며, 일부 UA는 사용자가 기본값을 구성하거나 UI를 통해 조각 지시문 포함 여부를 선택하게 할 수도 있습니다.
또한, UA가 사용 경험 개선을 다양한 방식으로 실험하는 것도 의미 있습니다. 예: 사용자가 스크롤해 일치 구절이 화면에서 벗어나면, 표시 URL에서 text fragment를 생략할 수도 있을 것입니다.
일반 원칙은 시각적 인디케이터(하이라이트 등)가 표시 중일 때만 URL에 조각 지시문을 포함시킵니다. 사용자가 인디케이터를 해제(dismiss)하면 URL에서 조각 지시문도 제거되어야 합니다.
URL에 텍스트 조각이 포함됐으나 현재 페이지에서 일치를 찾지 못한 경우, UA는 노출되는 URL에서 이를 생략할 수 있습니다.
해당 페이지에서 찾을 수 없는 텍스트 조각도, 사용자가 생성 시점 이후 페이지가 바뀌었음을 보여주는 정보로 쓸 수 있습니다.
그러나 북마크에선 이런 정보가 거의 의미 없을 것입니다.
아래에 몇 가지 대표적인 예시를 들었습니다.
3.7.1.1. 주소 표시줄
주소 표시줄의 URL은 시각적 인디케이터(하이라이트)가 표시되는 동안 텍스트 조각을 포함해야 합니다. 사용자가 인디케이터를 해제하면, 주소 표시줄 URL에서 조각 지시문도 제거해야 합니다.
문서 내에서 일치하는 결과가 없어도, text fragment는 주소 표시줄 URL에 표시하는 것이 권장됩니다.
3.7.1.2. 북마크
대부분의 UA는 사용자가 현재 페이지의 링크를 북마크로 저장하는 기능을 제공합니다.
새로 생성된 북마크는 기본적으로, 일치가 발견되고 시각 인디케이터가 해제되지 않은 경우에만 URL에 조각 지시문을 포함해야 합니다.
북마크에서 URL로 이동 시 보통 내비게이션과 동일하게 조각 지시문을 처리해야 합니다.
3.7.1.3. 공유
일부 UA는 사용자가 현재 페이지를 다른 앱 또는 메신저 등으로 공유할 수 있도록 기능을 제공합니다.
이 경우도, 일치가 발견되고 시각적 인디케이터가 해제되지 않았을 때만 조각 지시문이 포함된 URL을 전달해야 합니다.
3.8. 문서 정책 통합
이 명세는 configuration point로 이름이
"force-load-at-top"인 항목을 Document Policy에 정의합니다. 타입은 boolean이며 기본값은
false입니다.
https://example.com#:~:text=foo로 이동한다고
가정합니다.
example.com 서버의 응답 헤더는 아래와 같습니다:
Document-Policy: force-load-at-top
페이지가 로드되면, "foo"를 포함한 요소가 지시된 부분으로 지정되고 document의 target element가 됩니다. 그러나 "foo"는 시야에 스크롤되지 않습니다.
이 정책의 프래그먼트 기반 스크롤 차단은 본 문서 scroll to the fragment 알고리즘 개정으로 § 3.6 텍스트 조각으로 이동 절에 명시됩니다.
히스토리 스크롤 복원 차단은 restore persisted state 단계에서 2번 이후 아래 새 단계를 추가해 정의됩니다:
-
이 "force-load-at-top" policy의 값 조회, 그 결과가 true라면 UA는 Document나 그 어떤 스크롤 가능한 영역에도 스크롤 위치를 복원하지 않아야 함.
3.9. 기능 감지
기능 감지를 위해, UA가 해당 기능을 지원하는 경우 document.fragmentDirective를 통해 노출되는 새로운 FragmentDirective 인터페이스
추가를 제안합니다.
[Exposed =Window ]interface { };FragmentDirective
이 객체는 향후 텍스트 프래그먼트 혹은 기타 조각 지시문에 대한 추가 정보를 제공하는 데 사용될 수 있습니다.
4. 텍스트 조각 지시문 생성
이 절은 UA가 텍스트 지시문을 포함한 URL을 자동 생성하는 경우의 권장 사항을 포함합니다. 이 권장 사항은 엄격한 규범 사항은 아니지만, 생성된 URL이 최대한 안정적이고 활용도 높게 만들기 위함입니다.
4.1. 정확 일치 우선
매칭 텍스트는 "text=foo%20bar%20baz"처럼 정확 문자열을 활용할 수도 있고, "text=foo,bar"와 같이 범위로도 지정할 수 있습니다.
가능하다면 전체 문자열을 정확 일치로 지정하는 것이 좋습니다. 이렇게 하면, 목적지 페이지가 삭제되거나 변경되었을 때에도, URL 자체에서 원래 의도된 대상을 유추할 수 있습니다.
The first recorded idea of using digital electronics for computing was the 1931 paper "The Use of Thyratrons for High Speed Automatic Counting of Physical Phenomena" by C. E. Wynn-Williams.
범위 기반 매칭은 다음과 같습니다:
https://en.wikipedia.org/wiki/History_of_computing#:~:text=The%20first%20recorded,Williams
또는 전체 문장을 정확 일치로 인코딩할 수도 있습니다:
범위 기반 매칭은 덜 안정적입니다. 예를 들어, 페이지에 "The first recorded"가 앞부분에 새로 등장하면, 링크가 원치 않는 스니펫을 가리킬 수 있습니다.
범위 기반 매칭은 의미적으로도 덜 유용합니다. 문장이 지워질 경우, 사용자는 무엇이 원래 타깃이었는지 알 수 없게 되지만, 정확 일치의 경우 검색된 텍스트(없을 시)를 보여줄 수 있습니다.
인용 텍스트가 지나치게 길어서 전체 문자열 인코딩이 지나치게 긴 URL을 만들 위험이 있을 때, 범위 기반 매칭이 유용할 수 있습니다.
텍스트 스니펫이 300자 미만이라면 정확 매칭 방식으로 인코딩을 권장합니다. 그 이상이라면 범위 기반 방식도 허용할 수 있습니다.
4.2. 필요할 때만 문맥 사용
문맥 용어(context terms)는 텍스트 지시문이 페이지 내 텍스트 스니펫을 명확히 구별하는 데 쓰입니다. 다만 사용이 잦거나, 특정 구조(단락 경계 등)에서는 URL의 안정성이 취약해질 수 있습니다. 즉, 원하는 문자열이 요소 경계에서 시작/끝난다면, 문맥이 인접 요소에 존재하는데, 이런 구조적 변경 시 지시문이 무효화될 수 있습니다.
<div class="section">HEADER</div> <div class="content">Text to quote</div>
아래처럼 텍스트 지시문을 구성할 수 있습니다:
text=HEADER-,Text%20to%20quote
그러나, 페이지가 바뀌어 모든 section 헤더 옆에 "[edit]" 링크가 붙는다면, 이 URL은 더 이상 유효하지 않게 됩니다.
텍스트 스니펫이 길고 유일하다면, UA는 불필요한 문맥 용어 추가를 피해야 합니다.
아래 중 하나에 해당할 때만 문맥을 추가하세요:
- UA가 인용 텍스트가 애매하다고 판단할 때
- 인용 텍스트가 3단어 이하일 때
4.3. 조각 ID 필요 여부 결정
UA가 텍스트 지시문을 포함한 URL로 이동할 때, 텍스트 조각에 일치하지 않으면 일반 element-id 기반 프래그먼트(조각)로 스크롤링 fallback합니다(존재시).
문서 내 텍스트가 변경되어 텍스트 지시문이 무효화될 때를 대비한 fallback 용도로 유용합니다.
The earliest known tool for use in computation is the Sumerian abacus
텍스트가 등장하는 section도 명시하면, 문구가 변경·삭제되어도 사용자가 관련 섹션으로 이동하게 할 수 있습니다:
다만, fallback element-id 프래그먼트가 적절히 선정되었는지 주의해야 합니다:
By the late 1960s, computer systems could perform symbolic algebraic manipulations
현 페이지 URL이 https://en.wikipedia.org/wiki/History_of_computing#Early_computation 라 해도, fallback으로 #Early_computation을 쓰는 것은 부적절. 만일 위 문장이 수정·삭제된다면, 페이지가 #Early_computation 섹션에서 시작돼 사용자를 혼란시킬 수 있음.
UA가 적절한 fallback 조각을 신뢰성 있게 결정할 수 없다면, URL에서 fragment id를 빼는 것이 바람직합니다: