1. 소개
이 모듈은 CSS의 조판 제어 기능을 설명합니다. 즉, 소스 텍스트를 포맷된 줄바꿈 텍스트로 변환하는 CSS의 기능을 제어합니다. 다양한 CSS 속성들은 대소문자 변환, 공백 병합, 텍스트 줄바꿈, 줄바꿈 규칙 및 하이픈 처리, 정렬 및 균등 분배, 간격, 그리고 들여쓰기를 제어합니다. 레벨 3 이후의 추가사항은 레벨 3 이후의 변경사항을 참조하세요.
밑줄, 밑줄, 강조 표시, 그리고 그림자 등 텍스트 장식 기능은 (이전에는 이 모듈의 일부였으나) CSS 텍스트 장식 모듈에서 다룹니다. [CSS-TEXT-DECOR-3]
양방향 및 수직 텍스트는 CSS 쓰기 모드 모듈에서 다룹니다. [CSS-WRITING-MODES-4].
세계 여러 언어 및 문자 체계의 조판 요구사항에 대한 추가 정보는 국제화 작업 그룹의 언어 활성화 색인에서 확인할 수 있습니다. [TYPOGRAPHY]
1.1. 모듈 간 상호작용
이 모듈은 CSS 텍스트 장식 모듈과 함께, 계단식 스타일시트 레벨 2 16장에서 정의된 텍스트 수준 기능을 대체 및 확장합니다. [CSS-TEXT-DECOR-3] [CSS2]
아래에 정의된 용어 외에도, 이 명세에서 사용된 기타 용어 및 개념은 계단식 스타일시트 레벨 2 및 CSS 쓰기 모드 모듈에서 정의됩니다. [CSS2] 및 [CSS-WRITING-MODES-4].
1.2. 값 정의
이 명세는 CSS 속성 정의 관례를 [CSS2]에서 따르며, 값 정의 구문을 [CSS-VALUES-3]에서 사용합니다. 이 명세에서 정의되지 않은 값 타입은 CSS 값 및 단위 [CSS-VALUES-3]에서 정의됩니다. 다른 CSS 모듈과의 조합으로 이러한 값 타입의 정의가 확장될 수 있습니다.
각 속성 정의에 나열된 속성별 값 외에도, 이 명세에서 정의된 모든 속성은 CSS-공통 키워드도 속성 값으로 허용합니다. 가독성을 위해 명시적으로 반복하지 않았습니다.
1.3. 언어 및 조판
작성자는 최적의 조판 효과를 위해 콘텐츠의 언어 태그를 정확히 지정해야 합니다.
많은 조판 효과는 언어적 맥락에 따라 달라집니다. 언어와 문자 체계 관례는 줄바꿈, 하이픈 처리, 정렬, 글리프 선택 등 다양한 조판 효과에 영향을 줄 수 있습니다. CSS에서는 콘텐츠 언어가 알려진(선언된) 경우에만 언어별 조판 맞춤이 적용됩니다. 따라서 더 높은 품질의 조판을 위해서는 작성자가 문서 내 텍스트의 올바른 언어적 맥락을 UA에 전달해야 합니다.
콘텐츠 언어란 요소가 문서 언어의 규칙에 따라 선언된 (사람) 언어를 의미합니다. 요소의 콘텐츠 언어가 알려지지 않을 수도 있습니다—예: 언태그된 콘텐츠나, 언어 태그 기능이 없는 문서 언어의 콘텐츠는 콘텐츠 언어가 알려지지 않은 것으로 간주합니다.
참고: 작성자는 HTML의 글로벌 lang 속성이나
XML의 범용 xml:lang 속성을 사용해 콘텐츠 언어를 선언할 수 있습니다.
HTML에서 HTML 요소의 콘텐츠 언어 결정 규칙과,
XML 1.0에서 XML 요소의 콘텐츠 언어 결정 규칙을 참고하세요. [HTML] [XML10]
콘텐츠 언어는 해당 요소에서 사용된 특정 문어 형태를 식별하며, 이를 콘텐츠 문자 체계라고 합니다. 문서 언어의 콘텐츠 언어 식별 기능에 따라, 이 정보는 명시적일 수도 암시적일 수도 있습니다. 규범적 내용은 부록 F: 콘텐츠 문자 체계 식별을 참고하세요.
참고: 일부 언어는 여러 문자 체계 전통을 가질 수 있습니다; 또는 어떤 언어는 외국 문자 체계로 음차될 수도 있습니다. 작성자는 UA가 적절히 대응할 수 있도록 이런 경우 서브태그를 지정해야 합니다.
ko)는
한글(-Hang),
한자(-Hani),
혹은 조합(-Kore)으로 작성될 수 있습니다.
한자만으로 작성된 고문서는
단어 사이에 공백을 사용하지 않으며
현대 중국어와 유사하게 포맷됩니다.
즉, 조판 목적상 ko-Hani는 zh-Hant와 비슷하게 동작하며
ko(ko-Kore)와는 다릅니다.
또 다른 예로 일본어(ja)는
일반적으로 히라가나(-Hira),
가타카나(-Kana), 한자(-Hani)의 조합(-Japn)으로 작성됩니다.
그러나, 특별한 목적(예: 언어 학습 교재)을 위해 라틴 문자(-Latn)로 “로마자 표기”될 수도 있으며,
이 경우에는 일본어가 아닌 영어와 유사하게 포맷되어야 합니다.
또 다른 예로, 현대 몽골어는 두 가지 문자로 작성됩니다:
키릴 문자(-Cyrl, 몽골에서 공식적으로 사용됨)
그리고 몽골 문자(-Mong, 중국 내 내몽골에서 더 흔함).
이들은 매우 다른 포맷 요구사항을 가지며,
키릴 문자는 라틴 및 그리스 문자와 유사하게 동작하고,
몽골 문자는 아랍 및 중국 문자 관례에서 기원합니다.
1.4. 문자와 글자
조판의 기본 단위는 문자입니다. 하지만 문자 체계가 항상 기본 영어 알파벳처럼 단순하지 않기 때문에, 문자가 실제로 무엇인지는 용어가 사용되는 맥락에 따라 다릅니다. 예를 들어, 한글(한국어 문자 체계)에서는 각 음절의 네모꼴 표현(예: 한=Han) 자체를 문자로 볼 수 있습니다. 하지만, 이 네모 기호는 실제로 여러 개의 각각 음소를 나타내는 글자들로 구성되어 있으며 (예: ㅎ=h, ㅏ=a, ㄴ=n) 이것들도 각각 문자로 볼 수 있습니다.
컴퓨터 텍스트 인코딩의 기본 단위 또한 문자라고 하며, 인코딩에 따라 하나의 인코딩 문자가 전체 사전 구성된 음절 문자(예: 한)에 해당할 수도 있고, 개별 음소 문자(예: ㅎ)에 해당할 수도 있으며, 또는 더 작은 단위(예: 기본 글자 형태(ㅇ)와 변형을 위한 결합 기호(예: 추가 획))에 해당할 수도 있습니다.
또한, 하나의 인코딩 문자가 데이터 스트림에서는 하나 이상의 바이트로 표현될 수 있으며, 프로그래밍 환경에서는 하나의 바이트를 문자라고 부르기도 합니다.
따라서 문자라는 용어는 기술적으로 정밀함이 요구될 때는 상당히 모호합니다.
텍스트 레이아웃에서는 조판 문자 단위를 텍스트의 기본 단위로 사용합니다. 텍스트 레이아웃 내에서도, 해당 문자 단위는 작업에 따라 달라집니다. 예를 들어, 줄바꿈과 글자 간격 조정에서는 U+0E33 ำ 태국 문자 SARA AM을 포함하는 태국어 문자 시퀀스를 다르게 분할할 수 있습니다; 또는 데바나가리와 같은 문자에서 합자 자음의 동작은 사용되는 글꼴에 따라 달라질 수 있습니다. 따라서 조판 문자는 문자 체계의 단위—예: 라틴 알파벳(발음 기호 포함), 한글 음절, 한자, 미얀마 음절군—을 나타내며, 특정 조판 작업(줄바꿈, 첫 글자 효과, 트래킹, 균등 분배, 수직 배치 등)에 대해 분할되지 않는 단위입니다.
유니코드 표준 부속서 #29: 텍스트 분절는 그래프 클러스터라는 단위를 정의하며, 이는 조판 문자를 근사합니다. [UAX29] UA는 확장 그래프 클러스터(레거시 그래프 클러스터가 아님)를 UAX29에서 정의된 대로 조판 문자 단위의 기준으로 사용해야 합니다. 그러나 UA는 조판 전통에 따라 정의를 맞춤 설정해야 하며, 기본 규칙이 항상 적합하거나 이상적이지 않으므로 작업마다 다르게 맞춤 설정할 수 있습니다.
참고: 이러한 맞춤 설정 규칙은 CSS의 범위를 벗어납니다.
- 미얀마나 데바나가리와 같은 일부 문자 체계에서는, 균등 분배와 줄바꿈 모두에 대해 조판 문자 단위가 전체 음절로, 이는 유니코드 그래프 클러스터 하나 이상을 포함할 수 있습니다. [UAX29]
-
태국어나 라오와 같은 문자 체계에서는
줄바꿈에서는 조판 문자가 유니코드의 기본 그래프 클러스터와 일치하지만,
글자 간격에서는 해당 단위가
유니코드 그래프 클러스터보다 작은 단위가 필요하며,
간격을 삽입하기 전에 분해 또는 다른 대체가 필요할 수 있습니다. [UAX29]
예를 들어, 태국어 단어 คำ(U+0E04 + U+0E33)에 글자 간격을 올바르게 삽입하려면, U+0E33을 U+0E4D + U+0E32로 분해하고, 추가 글자 간격을 U+0E32 앞에 삽입해야 합니다: คํ า.
좀 더 복잡한 예로 น้ำ(U+0E19 + U+0E49 + U+0E33)의 경우, 일반적인 태국어 조형에서는 먼저 U+0E33을 U+0E4D + U+0E32로 분해하고, U+0E4D를 U+0E49와 교환하여 U+0E19 + U+0E4D + U+0E49 + U+0E32가 됩니다. 앞서와 같이 추가 글자 간격은 U+0E32 앞에 삽입됩니다: นํ้ า.
- 수직 조판도 맞춤 설정이 필요할 수 있습니다. 예를 들어, 수직 텍스트를 조판할 때, 티베트어 tsek 및 shad 기호는 앞선 그래프 클러스터와 함께 유지되며, 독립적인 조판 문자 단위로 처리되지 않습니다. [CSS-WRITING-MODES-4]
조판 글자 단위(또는 이 명세에서 글자)란 조판 문자 단위 중 Letter 혹은 Number 유니코드 범주에 속하는 것입니다. 조판 문자 단위의 유니코드 속성 결정 방법은 부록 E: 문자 및 속성을 참고하세요.
조판 문자 단위가 요소 경계에 의해 나뉘는 경우의 렌더링 특성은 정의되지 않습니다. 이상적으로는 각 구성 요소가 해당 요소의 속성에 따라 포맷 요구사항에 맞게 렌더링되면서 조판 문자 단위 전체의 올바른 조형과 위치를 유지해야 합니다. 하지만 부분 간의 포맷 차이와 사용되는 글꼴 기술의 기능에 따라, 항상 가능한 것은 아닙니다. 따라서 이러한 조판 문자 단위는 경계 어느 한쪽에 속한 것으로 렌더링되거나, 양쪽에 속한 것으로 근사 렌더링될 수 있습니다. 작성자는 그래프 클러스터나 합자를 요소 경계로 나누면 일관성 없거나 원치 않는 결과가 발생할 수 있음을 주의해야 합니다.
1.5. 텍스트 처리
CSS는 유니코드를 기반으로 합니다. [UNICODE] 유니코드 지원 UA는 유니코드 핵심 표준의 모든 규범적 요구사항을 CSS에서 명시적으로 재정의하지 않는 한 반드시 준수해야 합니다. 유니코드가 아닌 텍스트 인코딩 모델을 기반으로 구현된 UA도 적절한 매핑과 유사 동작을 가정하여 동일한 텍스트 처리 요구사항을 충족해야 합니다.
텍스트 처리(공백 처리, 텍스트 변환, 줄바꿈 등)에서 인접성을 결정하기 위해, 그리고 이 명세 전반에 걸쳐, 중간에 있는 인라인 박스 경계와 플로우 밖 요소는 무시되어야 합니다. 텍스트 조형과 관련해서는 § 8.7 요소 경계 간 조형을 참고하세요.
2. 텍스트 변환
2.1. 대소문자 변환: text-transform 속성
| 이름: | text-transform |
|---|---|
| 값: | none | [capitalize | uppercase | lowercase ] || full-width || full-size-kana | math-auto |
| 초기값: | none |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 스타일링을 위해 텍스트를 변환합니다. 이는 기본 콘텐츠에는 영향을 주지 않으며, 일반 텍스트 복사 & 붙여넣기 작업의 내용에는 영향을 주지 않아야 합니다.
작성자는 text-transform에 의미적 목적을 의존해서는 안 됩니다; 올바른 대소문자 및 의미는 소스 문서 텍스트와 마크업에 직접 인코딩해야 합니다.
각 값의 의미는 다음과 같습니다:
- none
- 효과 없음.
- capitalize
- 각 단어의 첫 조판 글자 단위가 소문자인 경우에는 제목 대문자로 변환합니다. 그 밖의 문자는 변환되지 않습니다.
- uppercase
- 모든 글자를 대문자로 변환합니다.
- lowercase
- 모든 글자를 소문자로 변환합니다.
- full-width
- 모든 조판 문자 단위를 전각 형태로 변환합니다. 해당 문자에 전각 형태가 없는 경우에는 그대로 둡니다. 이 값은 일반적으로 라틴 문자 및 숫자를 한자와 같이 조판할 때 사용됩니다.
- full-size-kana
- 모든 작은 가나 문자를 해당하는 큰 가나로 변환합니다. 이 값은 일반적으로 루비 주석 텍스트에 사용되며, 작성자가 작은 글꼴 크기에서 시인성을 보완하기 위해 모든 작은 가나를 큰 가나로 표시하고자 할 때 활용됩니다.
- math-auto
- MathML Core § 4.2 새로운 text-transform 값을 참고하세요.
abbr : lang ( ja) { text-transform : full-width; }
참고: text-transform의 목적은 문서의 의미에 영향을 주지 않고 표현상의 대소문자 변환을 허용하는 데 있습니다. 특히 text-transform의 대소문자 변환은 손실이 발생하며, 텍스트의 의미가 왜곡될 수 있습니다. 접근성 인터페이스에서는 렌더링된 텍스트의 대소문자를 사용자에게 전달하고자 할 수 있지만, 변환된 텍스트는 문서의 기본 의미를 정확히 나타낸다고 볼 수 없습니다.
section > p:first-of-type::first-line{ text-transform : uppercase; }
이 효과는 줄바꿈 위치가 레이아웃에 따라 달라지기 때문에 소스 문서에 직접 작성할 수 없습니다. 또한, 대문자화는 의미적 구분을 반영하는 것이 아니며 단락의 읽기 방식에 영향을 주려는 의도가 아니므로, 프레젠테이션 계층에 포함되어야 합니다.
rt{ font-size : 50 % ; text-transform : full-size-kana; } :is ( h1, h2, h3, h4) rt{ text-transform : none; /* 큰 텍스트에서는 해제 */ }
이렇게 하면 작은 글꼴 크기에서 해당 글자가 더 잘 보이지만, 변환 과정에서 텍스트가 왜곡됩니다: 독자는 적절한 위치에 작은 가나를 정신적으로 대입해야 하므로, 모든 “U”가 “V”처럼 보이는 라틴 비문을 읽는 것과 비슷합니다.
예를 들어, 다음 소스에 text-transform: full-size-kana를 적용하면 주석은 “じゆう”(jiyū, 자유)로 읽히게 되며, 실제로 주석된 “十”에 맞는 올바른 읽기와 의미인 “じゅう”(jū, 10)가 아닌 결과가 나옵니다.
< ruby > 十< rt > じゅう</ ruby >
2.1.1. 매핑 규칙
capitalize의 경우, “단어”의 정의는 UA에 따라 다릅니다; [UAX29]를 권장(필수 아님)하며 단어 경계 결정에 사용할 수 있습니다. 플로우 밖 요소와 인라인 요소 경계는 text-transform 단어 경계를 만들면 안 되며, 해당 경계를 결정할 때 무시되어야 합니다.
참고: 작성자는 capitalize가 언어별 제목 대문자 규칙(영어에서 관사 건너뛰기 등)을 따를 것이라 기대할 수 없습니다.
UA는 유니코드 표준의 기본 대소문자 알고리즘 섹션에 정의된 대소문자 전체 매핑 및 모든 조건부 대소문자 규칙을 반드시 사용해야 합니다. [UNICODE] 요소의 콘텐츠 언어가 문서 언어의 규칙에 따라 알려진 경우에만, 해당 언어별 규칙을 적용해야 합니다. 최소한 유니코드 SpecialCasing.txt의 언어별 규칙을 포함해야 하며, 이에 국한되지 않습니다.
전각
및 반각 형태의 정의는
Unicode Standard Annex #11:
East Asian Width에서 확인할 수 있습니다. [UAX11] 전각 형태로의 매핑은
Unicode Standard Annex #44: Unicode Character
Database의 Decomposition_Mapping에서 <wide> 또는 <narrow>
태그가 있는
코드 포인트를 기준으로 정의됩니다. [UAX44] <narrow> 태그의 경우,
매핑은 코드 포인트에서 분해 결과(태그 제외)로,
<wide> 태그의 경우
매핑은 분해 결과(태그 제외)에서 원래 코드 포인트로 이루어집니다.
작은 가나에서 큰 가나로의 매핑은 부록 G: 소형 가나 매핑에서 정의됩니다.
2.2. 단어 사이 확장: word-space-transform 속성
| 이름: | word-space-transform |
|---|---|
| 값: | none | [ space | ideographic-space ] && auto-phrase? |
| 초기값: | none |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 그대로 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
일부 언어와 문자 체계는 단어를 구분하는데 다양한 구분 문자를 사용하거나, 때로는 눈에 보이지 않는 구분 문자를 사용하기도 합니다. 이 속성은 작성자가 마크업을 변경하지 않고도 렌더링을 한 스타일에서 다른 스타일로 변경할 수 있도록 합니다.
- none
- 이 속성은 아무런 효과가 없습니다.
- space
- 이 요소의 자식 확장 가능한 구분자가 U+0020 스페이스(공백)로 대체됩니다.
- ideographic-space
- 이 요소의 자식 확장 가능한 구분자가 U+3000 전각 스페이스로 대체됩니다.
- auto-phrase
-
콘텐츠 언어가 알려져 있고
UA가 해당 언어에 대한 언어 분석을 지원하는 경우,
UA는 구
경계 탐지를 수행해야 합니다.
단어 구분 문자나 기타 공백
구분자,
또는 U+200B 제로 폭 스페이스가 해당 경계에 이미 없을 경우,
UA는 가상 확장 구분자를 삽입해야 합니다.
이 값이 생략되었거나, 콘텐츠 언어가 알려지지 않았거나, UA가 해당 언어에 대해 구 경계 탐지를 지원하지 않을 경우, 가상 확장 구분자는 없습니다.
이 속성에서 확장 가능한 구분자란 다음 중 하나를 의미합니다:
가상 확장 구분자는 UA가 텍스트 내에서 탐지한 구문 경계로, 원본 문서에 없는 확장 가능한 구분자를 나타냅니다. 이 속성 외에는 아무런 효과가 없습니다.
UA는 확장 가능한 구분자가 강제 줄바꿈 바로 앞이나 바로 뒤에 있을 때 (중간 인라인 박스 경계, 관련 margin/border/padding을 무시함) 해당 구분자를 대체하면 안 됩니다.
참고: 가상 확장 구분자는 인라인 박스 경계에 참여하는 가장 바깥 요소에 삽입되기 때문에, 인라인 박스의 경계와 일치하고 해당 부모 박스에 사용된 값이 word-space-transform: none인 경우, 해당 가상 확장 구분자는 확장되지 않습니다. 이는 부모 박스에 삽입되기 때문입니다.
text-transform과 마찬가지로, 이 속성은 스타일링을 위한 텍스트 변환만 수행합니다. 기본 콘텐츠에는 영향을 주지 않으며, 일반 텍스트 복사 & 붙여넣기 작업의 내용에는 영향을 주지 않습니다.
성인용 책과 달리, 일본 어린이용 책에는 종종 문장 단위로 공백이 들어가 있어 읽기 편하게 되어 있습니다. 난독증이 있는 사람들도 이런 스타일을 더 쉽게 읽는 경향이 있습니다.
특별한 스타일링 없이, 아래 문장은 다음과 같이 렌더링됩니다.
< p > むかしむかし、< wbr > あるところに、< wbr > おじいさんと< wbr > おばあさんが< wbr > すんでいました。
むかしむかし、あるところに、おじいさんとおばあさんがすんでいました。
구 기반 공백은 다음 css로 적용할 수 있습니다:
p {
word-space-transform : ideographic-space;
}
むかしむかし、 あるところに、 おじいさんと おばあさん가 すんでいました。
또 다른 일반적인 변형은 허용 줄바꿈 위치를 이러한 구 경계로 제한하는 것입니다. 같은 마크업을 사용하면 다음 css로 쉽게 구현할 수 있습니다:
p {
word-break : keep-all;
word-space-transform : ideographic-space;
}
むかしむかし、
소스 코드를 더 읽기 쉽게 만들 뿐만 아니라,
마크업에서 U+200B 대신
wbr
요소를 사용하면
구분자를 여러 그룹으로 분류할 수도 있습니다.
아래 예시에서는
wbr
요소가
단어 경계에서는 아무 표시 없이,
구 경계에서는 p 클래스가 지정되어 있습니다.
< p > らいしゅう< wbr > の< wbr > じゅぎょう< wbr > に< wbr class = p
> たいこ< wbr > と< wbr > ばち< wbr > を< wbr class = p
> もって< wbr > きて< wbr > ください。
이렇게 하면 흔한 구 기반 공백뿐 아니라, 난독증이 있는 사람이 모호함을 줄이기 위해 선호할 수 있는 단어별 공백 등 다양한 변형(구 기반 공백 + 단어 기반 줄바꿈 등)도 구현할 수 있습니다.
らいしゅう
p wbr.p {
word-space-transform : ideographic-space;
}
らいしゅう
p wbr {
word-space-transform : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr.p {
word-space-transform : ideographic-space;
}
らいしゅう
p {
word-break : keep-all;
}
p wbr {
word-space-transform : ideographic-space;
}
らいしゅう
2.3. 변환 적용 순서
여러 변환을 적용해야 할 경우, 다음 순서로 적용됩니다:
단어 간 공백 변환과 텍스트 변환은 § 4.3.1 1단계: 병합 및 변환 이후, § 4.3.2 2단계: 트리밍 및 위치 조정 이전에 적용됩니다. 예를 들어 full-width는 보존된 공백 내에서만 스페이스(U+0020)를 U+3000 전각 스페이스로 변환합니다.
참고: 부록 A: 텍스트 처리 순서에서 정의된 대로, 변환은 줄바꿈이나 기타 포맷 작업에 영향을 미칩니다.
3. 공백 및 줄바꿈: white-space 속성
| 이름: | white-space |
|---|---|
| 값: | normal | pre | pre-wrap | pre-line | <'white-space-collapse'> || <'text-wrap-mode'> || <'white-space-trim'> |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 개별 속성 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 white-space-collapse, text-wrap-mode, white-space-trim에 대한 단축 속성입니다. 두 가지를 지정합니다:
- 공백이 병합되는지 여부와 방법; 공백 처리 참조
- 줄이 강제되지 않은 소프트 줄바꿈 기회에서 줄바꿈이 허용되는지; § 5 텍스트 줄바꿈 및 줄바꿈 참조
참고: 이 단축 속성은 상속되는 속성과 상속되지 않는 속성을 모두 포함합니다. 만약 문제가 있다면 CSSWG에 알려주세요.
별도 지정하지 않는 한, 생략된 개별 속성은 초기값으로 설정됩니다.
아래 표는 단축 속성의 특수 키워드 값이 각각 어떤 개별 속성 값으로 매핑되는지 규범적으로 보여줍니다.
| white-space | white-space-collapse | text-wrap-mode | white-space-trim |
|---|---|---|---|
| normal | collapse | wrap | none |
| pre | preserve | nowrap | none |
| pre-wrap | preserve | wrap | none |
| pre-line | preserve-breaks | wrap | none |
참고: 어떤 경우에는 보존된 공백과 기타 공백 구분자가 줄 끝에서 매달림이 발생할 수 있으며, 이는 내재 크기 측정에 영향을 줄 수 있습니다.
아래 비규범 표는 여러 white-space 값의 동작을 요약합니다:
| 줄 바꿈 | 공백 및 탭 | 텍스트 줄바꿈 | 줄 끝 공백 | 줄 끝 기타 공백 구분자 | |
|---|---|---|---|---|---|
| normal | 병합 | 병합 | 줄바꿈 | 제거 | 매달림 |
| pre | 보존 | 보존 | 줄바꿈 없음 | 보존 | 줄바꿈 없음 |
| nowrap | 병합 | 병합 | 줄바꿈 없음 | 제거 | 매달림 |
| pre-wrap | 보존 | 보존 | 줄바꿈 | 매달림 | 매달림 |
| break-spaces | 보존 | 보존 | 줄바꿈 | 줄바꿈 | 줄바꿈 |
| pre-line | 보존 | 병합 | 줄바꿈 | 제거 | 매달림 |
4. 공백 처리 및 제어 문자
문서의 소스 텍스트에는 실제 렌더링과 관련 없는 서식이 자주 포함되어 있습니다: 예를 들어, 편집 편의를 위해 소스를 여러 구간(줄)로 나누거나 공백 문자인 탭과 스페이스로 소스 코드를 들여쓰는 경우가 그렇습니다. CSS 공백 처리는 작성자가 이런 서식의 해석을 제어할 수 있도록 하며: 렌더링 시 보존 또는 병합(제거)할 수 있습니다. CSS의 공백 처리 (white-space-collapse 및 white-space-trim 속성으로 제어) 공백 문자를 렌더링 용도로만 해석합니다: 기본 문서 데이터에는 영향을 주지 않습니다.
참고: 문서 언어에 따라,
구간은 특정 개행 시퀀스(줄바꿈 문자 또는 CRLF 쌍 등)로 분리되거나,
SGML의 RECORD-START 및 RECORD-END 토큰과 같이 다른 메커니즘으로 구분될 수 있습니다.
CSS 처리에서는 문서 언어에서 정의한 “구간 분리” 또는 “개행 시퀀스”—정의가 없으면 텍스트 내의 각 줄바꿈(U+000A)—을 구간 분리로 취급하며, 이는 white-space 속성에 따라 렌더링 시 해석됩니다.
HTML의 경우, 줄바꿈이 정규화되어 줄바꿈 문자(U+000A)로 DOM에 나타나므로, HTML 문서가 DOM 트리로 표현될 때 각 줄바꿈(U+000A)이 구간 분리로 취급됩니다. [HTML] [DOM]
참고: 대부분의 CSS 구현에서, HTML은 직접 스타일링되지 않고, DOM 트리로 변환된 뒤 스타일링됩니다. HTML과 달리, DOM에서는 캐리지 리턴(U+000D)에 특별한 의미를 부여하지 않으므로 구간 분리로 처리되지 않습니다. 캐리지 리턴(U+000D)이 HTML 파싱 이외 방식으로 DOM에 삽입된 경우, 아래 정의에 따라 처리됩니다.
참고: 문서 파서는 구간 분리를 정규화할 뿐만 아니라, 다른 공백 문자를 병합하거나 마크업 규칙에 따라 공백을 처리할 수 있습니다. CSS 처리는 파싱 단계 이후에 일어나므로, 스타일링을 위해 이런 문자를 복원하는 것은 불가능합니다. 따라서 아래 명세된 일부 동작은 이런 제한에 의해 UA마다 다를 수 있습니다.
참고: 병합 가능한 공백만으로 이루어진 익명 블록은 렌더링 트리에서 제거됩니다. 따라서 블록 요소 주변의 이러한 공백은 모두 병합(제거)됩니다. CSS 2.1 § 9.2.2.1 익명 인라인 박스 참조. [CSS2]
제어 문자(유니코드
범주 Cc)—탭(U+0009), 줄바꿈(U+000A),
캐리지 리턴(U+000D),
그리고 구간 분리를 형성하는 시퀀스를 제외하고—는
UA가 글리프를 합성해
반드시 보이는 글리프로 렌더링해야 하며,
그 외에는 Other Symbols(So) 일반 범주 및 Common 스크립트의 문자와 동일하게 처리해야 합니다.
UA는 해당 제어 문자에 대해 폰트에서 제공하는 글리프를 사용하거나,
Control Pictures 블록의 해당 기호 글리프를 대체하거나,
코드 포인트 값을 시각적으로 표시하거나,
다른 적절한 방법으로 보이는 글리프를 제공할 수 있습니다.
유니코드 요구대로,
지원되지 않는 Default_ignorable 문자는 텍스트 렌더링에서 무시되어야 합니다. [UNICODE]
캐리지 리턴(U+000D)은 모든 면에서 스페이스(U+0020)와 동일하게 처리됩니다.
참고: HTML 문서의 경우,
소스 코드에 포함된 캐리지 리턴은
파싱 단계에서 줄바꿈 문자로 변환됩니다
(HTML
§ 13.2.3.5 입력 스트림 전처리 및 줄바꿈 정규화 정의
참조)
따라서 CSS에서는 U+000D 캐리지 리턴으로 나타나지 않습니다. [HTML] [INFRA])
하지만 escape sequence(
4.1. 공백 병합: white-space-collapse 속성
이 섹션은 아직 논의 중이며, 이후 초안에서 변경될 수 있습니다.
| 이름: | white-space-collapse |
|---|---|
| 값: | collapse | discard | preserve | preserve-breaks | preserve-spaces | break-spaces |
| 초기값: | collapse |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 공백이 병합되는지 여부와 방법을 지정합니다. 각 값의 의미는 공백 처리 규칙에 따라 해석되어야 합니다:
- collapse
- 이 값은 UA가 공백 시퀀스를 하나의 문자(또는 일부 경우에는 아무 문자 없음)로 병합하도록 지시합니다.
- preserve
- 이 값은 UA가 공백 시퀀스를 병합하지 않도록 합니다. 구간 분리(줄바꿈 등)는 강제 줄바꿈으로 보존됩니다.
- preserve-breaks
- collapse와 유사하게, 이 값은 연속된 공백 문자를 병합하지만, 소스 내 구간 분리는 강제 줄바꿈으로 보존합니다.
- preserve-spaces
- 이 값은 UA가 공백 시퀀스를 병합하지 않도록 하며,
탭과 구간 분리를 스페이스로 변환합니다.
(이 값은 SVG에서
xml:space="preserve"의 동작을 나타내기 위해 의도되었습니다.) - break-spaces
-
동작은 preserve와 동일하지만, 다음과 같은 차이가 있습니다:
- 보존된 공백 또는 기타 공백 구분자의 시퀀스는 항상 공간을 차지합니다, 줄 끝에서도 마찬가지입니다.
- 소프트 줄바꿈 기회가 모든 보존된 공백 문자 뒤와 모든 기타 공백 구분자 뒤에 항상 존재합니다(인접한 스페이스 사이도 포함).
참고: 이 값은 공백으로 인해 오버플로우가 절대 발생하지 않음을 보장하지 않습니다: 예를 들어, 줄 길이가 너무 짧아 단 하나의 공백 문자조차 들어가지 못할 경우 오버플로우는 피할 수 없습니다.
- discard
-
이 값은 UA가 해당 요소 내의 모든 공백을 “버리도록” 지시합니다.
줄바꿈 기회를 보존해야 하나요? 별도의 "hide" 값이 필요할까요? 줄바꿈 기회를 보존한다면, word-space-transform 값으로 대체해야 할지도 모릅니다.
공백이 공백 처리로 인해 제거되거나 병합되지 않은 경우, 보존된 공백이라고 합니다.
아래 스타일 규칙은 MathML의 공백 처리 방식 구현 예시입니다:
@namespace m "http://www.w3.org/1998/Math/MathML";
m|* {
white-space-collapse: discard;
}
m|mi, m|mn, m|mo, m|ms, m|mtext {
white-space-trim: discard-inner;
}
4.2. 공백 트리밍: white-space-trim 속성
| 이름: | white-space-trim |
|---|---|
| 값: | none | discard-before || discard-after || discard-inner |
| 초기값: | none |
| 적용 대상: | 인라인 박스 및 블록 컨테이너 |
| 상속 여부: | 아니오 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드들 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 박스의 시작과 끝에서 트리밍 동작을 지정할 수 있도록 해줍니다. 각 값의 의미는 다음과 같습니다:
- discard-before
- 이 값은 UA가 요소 시작 직전의 모든 병합 가능한 공백을 병합(제거)하도록 지시합니다.
- discard-after
- 이 값은 UA가 요소 끝 바로 뒤의 모든 병합 가능한 공백을 병합(제거)하도록 지시합니다.
- discard-inner
- 블록 컨테이너의 경우 이 값은 UA가 요소 시작 부분에서 첫 번째 공백이 아닌 문자 전까지, 그리고 마지막 공백이 아닌 문자 이후부터 요소 끝까지의 모든 공백을 (구간 분리 포함) 병합(제거)하도록 지시합니다. 다른 요소의 경우 시작과 끝의 모든 공백을 병합(제거)합니다.
참고: white-space-trim으로 문서 공백을 제거하면 텍스트 내 소프트 줄바꿈 기회가 발생하는 위치에 영향을 줄 수 있습니다.
아래 스타일 규칙은 DT 요소를 소스 문서에서 줄이 분리되어 있어도 쉼표로 구분된 목록처럼 렌더링합니다:
dt { display: inline; }
dt + dt:before { content: ", "; white-space-trim: discard-before; }
아래 스타일 규칙은 서식 있는 블록의 시작/끝 태그 인접 소스 공백만 제거하고, 실제 요소 내용에 적용된 들여쓰기나 중간 공백은 제거하지 않습니다:
pre { white-space: pre; white-space-trim: discard-inner; }
이 결과, 두 개의 소스 코드 스니펫은 다음과 같이:
< pre > some preformatted text</ pre >
< pre > some preformatted text</ pre >
some preformatted text
반대로 인라인 요소에 적용하면:
span { white-space: normal; white-space-trim: discard-inner; }
start[< span > some inline text</ span > ]end
start[< span > some inline text</ span > ]end
start[some inline text]end
white-space-trim의 공백 처리는 § 4.3.1 1단계: 병합 및 변환 이전에 수행됩니다.
4.3. 공백 처리 규칙
별도로 명시하지 않은 경우, CSS에서의 공백 처리는 오직 문서 공백 문자에만 영향을 미칩니다: 스페이스 (U+0020), 탭 (U+0009), 그리고 구간 분리.
참고: 문서 공백으로 간주되는 문자 집합(문서 콘텐츠의 일부) 와 구문적 공백(CSS 구문의 일부)으로 간주되는 문자 집합은 반드시 동일하지는 않습니다. 하지만 스페이스(U+0020), 탭(U+0009), 줄바꿈(U+000A)은 모두 포함되기 때문에 대부분의 작성자는 차이를 느끼지 못합니다.
스페이스(U+0020)와 줄바꿈 없는 스페이스(U+00A0) 외에도, 유니코드에는 추가적인 여러 공간 구분 문자가 정의되어 있습니다. [UNICODE] 본 명세에서는 유니코드 일반 범주 Zs에 속하지만 스페이스(U+0020)와 줄바꿈 없는 스페이스(U+00A0)를 제외한 모든 문자를 기타 공간 구분자라 통칭합니다.
4.3.1. 1단계: 병합 및 변환
참고: white-space-trim은 이 단계 이전에 고려됩니다.
각 인라인(익명 인라인 포함;
CSS 2.1 § 9.2.2.1 익명 인라인 박스 [CSS2] 참고)
인라인 포맷팅 컨텍스트 내에서, 공백 문자는 줄바꿈 처리와 양방향 재정렬 이전에 아래와 같이 처리됩니다.
양방향 포맷팅 문자
(Bidi_Control 속성을 가진 문자 [UAX9])
는 존재하지 않는 것처럼 무시합니다:
-
white-space-collapse가 collapse 또는 preserve-breaks로 설정된 경우, 공백 문자는
병합 가능한 공백으로 간주되며, 다음 단계로 처리됩니다:
- 병합 가능한 스페이스와 탭이 구간 분리(segment break) 바로 앞 또는 뒤에 연속된 경우, 모두 제거됩니다.
- 병합 가능한 구간 분리는 렌더링 시 구간 분리 변환 규칙에 따라 변환됩니다.
- 모든 병합 가능한 탭은 병합 가능한 스페이스(U+0020)로 변환됩니다.
- 다른 병합 가능한 스페이스 바로 뒤에 오는 병합 가능한 스페이스—해당 스페이스가 포함된 인라인 경계 외부라 하더라도, 두 스페이스가 동일 인라인 포맷팅 컨텍스트 내에 있으면—진행 폭이 0이 되도록 병합됩니다. (보이지 않지만, 소프트 줄바꿈 기회는 유지됩니다.)
- white-space-collapse가 preserve-spaces로 설정된 경우, 각 탭과 구간 분리는 스페이스로 변환됩니다.
- white-space-collapse가 preserve 또는 preserve-spaces로 설정된 경우, 스페이스 시퀀스는 논브레이킹 스페이스 시퀀스로 취급되지만, 소프트 줄바꿈 기회는 각 최대 시퀀스의 스페이스 및 탭 끝에 존재합니다. break-spaces의 경우, 모든 스페이스와 탭 뒤에 소프트 줄바꿈 기회가 존재합니다.
<ltr>A <rtl> B </rtl> C</ltr><ltr> 요소는 좌-우 임베딩을,
<rtl> 요소는 우-좌 임베딩을 나타냅니다.
white-space 속성이 normal이면,
공백 처리 모델은 아래와 같은 결과를 만듭니다:
결과적으로 두 개의 스페이스가 남게 되며, 하나는 좌-우 임베딩 레벨의 A 뒤에, 하나는 우-좌 임베딩 레벨의 B 뒤에 위치합니다. 텍스트는 유니코드 양방향 알고리즘에 따라 정렬되며, 최종 결과는 다음과 같습니다:
A BC
A와 B 사이에는 두 개의 스페이스가, B와 C 사이에는 스페이스가 없다는 점을 주목하세요. 이런 현상은 스페이스를 요소 안쪽이 아닌 바깥쪽에 배치하거나, 가능하다면 명시적 임베딩 레벨 대신 암시적 양방향성을 활용하는 것이 바람직합니다.
4.3.2. 2단계: 트리밍 및 위치 조정
그 후 전체 블록이 렌더링됩니다. 인라인들이 배치되며, 양방향 재정렬을 고려하고, 줄바꿈은 text-wrap-mode 및 text-wrap-style에 따라 지정됩니다. 각 줄을 배치할 때,
- 줄 시작에 있는 병합 가능한 스페이스 시퀀스는 제거됩니다.
-
탭 크기가 0이면 보존된
탭은 렌더링되지 않습니다.
그렇지 않은 경우, 각 보존된 탭은
다음 탭 스톱에 맞춰 다음 글리프의 시작 모서리가 정렬되도록 수평
이동으로 렌더링됩니다.
이 거리가 0.5ch 미만이면, 다음 탭 스톱이 사용됩니다. 탭 스톱은
보존된 탭의 가장 가까운 블록 컨테이너 조상 컨텐츠 시작 모서리에서
탭 크기의 배수 위치에 존재합니다.
탭 크기는 tab-size
속성으로 지정됩니다.
참고: 유니코드 탭(U+0009)과 양방향성의 상호작용 규칙 참고. [UAX9]
-
줄 끝의 병합
가능한 스페이스 시퀀스와, white-space-collapse 속성이 collapse 또는 preserve-breaks일 때 줄 끝에 위치한 U+1680
오감 스페이스 마크는 제거됩니다.
참고: 유니코드 양방향 알고리즘 규칙 L1에 따라, 줄 끝에 위치한 병합 가능한 스페이스 시퀀스는 양방향 재정렬 전후 모두 줄 끝에 위치하게 됩니다. [UAX9] [CSS-WRITING-MODES-4]
-
줄 끝(양방향 재정렬 이후 [CSS-WRITING-MODES-4])에 공백, 기타 공간 구분자, 보존된 탭 시퀀스가 남아 있다면:
- white-space-collapse가 collapse 또는 preserve-breaks인 경우, UA는 무조건적으로 해당 시퀀스를 매달림 처리해야 합니다.
-
white-space-collapse가 preserve이고, text-wrap-mode가 nowrap이 아니면,
UA는 (무조건적으로) 해당 시퀀스를 매달림 처리해야 하며,
만약 해당 시퀀스 뒤에 강제 줄바꿈이 오면,
대신 조건부
매달림 처리해야 합니다.
필요하다면 오버플로우될 문자의 진행 폭을 시각적으로 병합할 수도 있습니다.
참고: 공백을 병합하지 않고 매달림 처리하면 사용자가 텍스트 선택 또는 편집 시 공간을 볼 수 있습니다.
-
white-space-collapse가 break-spaces로 설정된 경우,
스페이스, 탭, 기타 공간 구분자는 다른 보이는
문자와 동일하게 취급됩니다:
매달림 처리하거나 진행 폭을 병합하지 않습니다.
참고: 이런 문자는 공간을 차지하므로, 사용 가능한 공간과 줄바꿈 제어에 따라 오버플로우되거나 줄이 감싸질 수 있습니다.
white-space-collapse: preserve-spaces의 경우 어떻게 처리해야 하나요?
p {
white-space : pre-wrap;
width : 5 ch ;
border : solid 1 px ;
font-family : monospace;
text-align : center;
}
< p > 0</ p >
위 샘플은 다음과 같이 렌더링됩니다:
마지막 스페이스가 강제 줄바꿈 앞에 있고 오버플로우되지 않으므로, 매달림 처리되지 않으며, 가운데 정렬이 정상적으로 작동합니다.
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
위 샘플은 다음과 같이 렌더링됩니다:
0 0
0
p
를 추가하면,
결과는 다음과 같습니다:
0 0
0
강제 줄바꿈 없는 줄 끝의 보존된 스페이스는 매달림 처리되어, 텍스트 정렬 시 줄의 나머지 부분 배치에 고려되지 않습니다. 끝쪽으로 정렬할 때, 이런 스페이스는 오버플로우되며, 줄 나머지 콘텐츠가 끝에 맞춰 배치되는 것을 방해하지 않습니다. 반면, 줄 끝의 보존된 스페이스가 강제 줄바꿈이 있는 경우에는 조건부 매달림 처리됩니다. 이 예시에서는 마지막 줄 끝의 공간이 오버플로우되지 않으므로, 매달림 처리되지 않고 텍스트 정렬에 포함됩니다.
p {
white-space : pre-wrap;
width : 3 ch ;
border : solid 1 px ;
font-family : monospace;
}
< p > 0 0 0 0</ p >
0 0
마지막 줄은 마지막 0 앞에서 줄이 감싸지지 않는데,
그 이유는 조건부 매달림
문자는
줄의 적합성 측정에 포함되지 않기 때문입니다.
4.3.3. 구간 분리 변환 규칙
white-space-collapse가 collapse가 아닐 때, 구간 분리는 병합 가능하지 않습니다. collapse나 preserve-spaces 외의 값(이 값은 구간 분리를 스페이스로 변환함)에서는, 구간 분리는 보존된 줄바꿈(U+000A)으로 변환됩니다.
white-space-collapse가 collapse일 때, 구간 분리는 병합 가능하며, 아래와 같이 병합됩니다:
- 먼저, 병합 가능한 구간 분리가 다른 병합 가능한 구간 분리 바로 뒤에 오면 제거됩니다.
-
남은 구간 분리는
상황에 따라 스페이스(U+0020)로 변환되거나 제거됩니다.
이 동작 규칙은 이 레벨에서는 UA에서 정의합니다.
참고: 공백 처리 규칙에서 이미 탭과 스페이스를 구간 분리 주변에서 제거했으므로, 이 컨텍스트 평가 전에 적용됩니다.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
Here is an English paragraph that is broken into multiple lines in the source code so that it can be more easily read and edited in a text editor.
중국어처럼 단어 구분자가 없는 언어에서는 줄을 이어붙일 때 중간에 공백 없이 연결해야 합니다.
這個段落是那麼長,
在一行寫不行。最好
用三行寫。
這個段落是那麼長,在一行寫不行。最好用三行寫。
구간 분리 변환 규칙은 인접한 컨텍스트를 활용하여, 구간 분리를 스페이스로 변환하거나 완전히 제거할 수 있습니다.
참고: 역사적으로 HTML과 CSS는 구간 분리를 무조건 스페이스로 변환해왔으나, 이로 인해 중국어 등 일부 언어에서는 소스 내에서 줄을 자유롭게 쪼갤 수 없었습니다. 따라서 UA 휴리스틱은 이런 언어 지원을 개선하려 할 때에도 구간 분리를 버리는 위치에 대해 신중해야 합니다.
4.4. 탭 문자 크기: tab-size 속성
| 이름: | tab-size |
|---|---|
| 값: | <number [0,∞]> | <length [0,∞]> |
| 초기값: | 8 |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 숫자 또는 절대 길이 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 계산된 값 타입별 |
이 속성은 탭 크기를 결정하며, 보존된 탭 문자(U+0009)를 렌더링할 때 사용됩니다. <number> 값은 가장 가까운 블록 컨테이너 조상의 스페이스 문자(U+0020) 진행폭의 배수로 크기를 나타냅니다. 보존된 탭에는 관련 letter-spacing 및 word-spacing이 포함됩니다. 음수 값은 허용되지 않습니다.
5. 텍스트 줄바꿈
인라인 레벨 콘텐츠가 줄로 배치될 때, 줄 박스 사이에서 분리됩니다. 이러한 분리를 줄바꿈이라고 합니다. 줄이 명시적 줄바꿈 제어(예: 보존된 줄바꿈 문자)나 블록의 시작 또는 끝에 의해 분리될 때, 이는 강제 줄바꿈입니다. 줄이 콘텐츠 자동 줄바꿈(즉, UA가 콘텐츠를 너비에 맞추기 위해 강제되지 않은 줄바꿈을 생성하는 경우)에 의해 분리될 때, 이는 소프트 줄바꿈입니다. 인라인 레벨 콘텐츠를 줄로 나누는 과정을 줄바꿈 처리라고 합니다.
줄바꿈은 허용된 분리 지점(브레이크 포인트)에서만 수행되며, 이를 소프트 줄바꿈 기회라고 합니다. 줄바꿈이 활성화된 경우(white-space 참조), UA는 줄에서 오버플로우되는 콘텐츠를 최소화하기 위해 소프트 줄바꿈 기회에서 줄을 감싸야 합니다(존재할 경우).
텍스트가 어디서 줄바꿈될 수 있는지는 줄바꿈 규칙 및 제어로, 줄바꿈이 허용되는지와 한 줄 내 여러 소프트 줄바꿈 기회의 우선순위 지정 방식은 text-wrap-mode, text-wrap-style, wrap-before, wrap-after, wrap-inside 속성에 의해 제어됩니다.
5.1. 줄바꿈 여부 결정: text-wrap-mode 속성
| 이름: | text-wrap-mode |
|---|---|
| 값: | wrap | nowrap |
| 초기값: | wrap |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성의 이름은 임시이며, CSSWG가 더 나은 이름을 찾을 때까지 대기 중입니다.
참고: 이 속성은 white-space와 text-wrap의 개별 속성입니다.
이 속성은 줄이 강제되지 않은 소프트 줄바꿈 기회에서 줄바꿈이 허용되는지 지정합니다. 가능한 값은 다음과 같습니다:
- wrap
-
콘텐츠는 허용된 소프트
줄바꿈 기회에서 줄을 나눌 수 있으며,
적용 중인 줄바꿈 규칙에 따라
인라인 축 오버플로우를 최소화합니다.
참고: § 5.6 줄바꿈 세부사항에서 소프트 줄바꿈 기회에 대한 규칙 및 제약을 더 자세히 확인할 수 있습니다.
- nowrap
- 인라인 레벨 콘텐츠는 줄을 나누지 않으며, 콘텐츠가 블록 컨테이너 내에 맞지 않으면 오버플로우됩니다.
text-wrap-mode 값과 관계없이,
보존된 구간 분리와
BK, CR, LF, NL 줄바꿈 클래스가 있는 모든 유니코드 문자는
강제 줄바꿈으로 처리되어야 합니다. [UAX14]
참고: 이런 강제 줄바꿈의 양방향성 관련 사항은 Unicode 양방향 알고리즘에서 정의됩니다. [UAX9]
5.2. 박스 내에서의 줄바꿈 제어: wrap-inside 속성
| 이름: | wrap-inside |
|---|---|
| 값: | auto | avoid |
| 초기값: | auto |
| 적용 대상: | 인라인 박스 |
| 상속 여부: | 아니오 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
- auto
- 박스 내에서 허용된 브레이크 포인트에서 줄이 나뉠 수 있으며, 적용 중인 줄바꿈 규칙에 따라 결정됩니다.
- avoid
-
박스 내에서의 줄바꿈이 억제됩니다:
UA는 줄 내에 다른 유효한 브레이크 포인트가 없을 때만 박스 내에서 줄바꿈할 수 있습니다.
텍스트가 줄바꿈되면,
줄바꿈 제한은 auto와 동일하게 적용됩니다.
여러 avoid 값을 가진 박스가 중첩된 경우, UA가 반드시 박스 내에서 줄바꿈해야 한다면, 내부 박스보다 외부 박스에서 먼저 줄바꿈이 발생해야 합니다.
5.2.1. 'wrap-inside: avoid'를 푸터에 적용한 예시
브레이크 포인트의 우선순위를 설정하여 텍스트의 의도된 그룹화를 반영할 수 있습니다.
다음 규칙이 주어진다면
footer { wrap-inside: avoid; }
venue { wrap-inside: avoid; }
date { wrap-inside: avoid; }
place { wrap-inside: avoid; }
그리고 다음과 같은 마크업이 있다면:
<footer> <venue>27th Internationalization and Unicode Conference</venue> • <date>April 7, 2005</date> • <place>Berlin, Germany</place> </footer>
좁은 창에서는 푸터가 다음과 같이 줄바꿈될 수 있습니다
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
혹은 더 좁은 창에서는 다음과 같이 줄바꿈될 수 있습니다
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
하지만 다음과 같이 줄바꿈되면 안 됩니다
27th Internationalization and Unicode Conference • April 7, 2005 • Berlin, Germany
5.3. 박스 사이 줄바꿈 제어: wrap-before/wrap-after 속성
| 이름: | wrap-before, wrap-after |
|---|---|
| 값: | auto | avoid | avoid-line | avoid-flex | line | flex |
| 초기값: | auto |
| 적용 대상: | 인라인 레벨 박스와 플렉스 항목 |
| 상속 여부: | 아니오 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성들은 줄바꿈(및 플렉스 줄 줄바꿈 [CSS3-FLEXBOX])에서의 줄바꿈 기회를 수정합니다. 가능한 값:
- auto
- 허용된 브레이크 포인트에서 박스 앞뒤로 줄이 나뉠 수 있으며, 적용 중인 줄바꿈 규칙에 따라 결정됩니다.
- avoid
- 박스 바로 앞/뒤에서의 줄바꿈이 억제됩니다: 해당 줄에 다른 유효한 브레이크 포인트가 없을 때만 줄바꿈이 가능합니다. 텍스트가 줄바꿈되면, 줄바꿈 제한은 auto와 동일하게 적용됩니다.
- avoid-line
- avoid와 동일하나, 줄바꿈에만 적용됩니다.
- avoid-flex
- avoid와 동일하나, 플렉스 줄바꿈에만 적용됩니다.
- line
- 박스가 인라인 레벨 박스라면, 박스 앞/뒤에 강제 줄바꿈을 적용합니다.
- flex
- 박스가 플렉스 항목이고 다중 줄 플렉스 컨테이너 내에 있을 때, 박스 앞/뒤에 강제 플렉스 줄바꿈을 적용합니다.
인라인 레벨 박스에서의 강제 줄바꿈은 부모 인라인 박스로 상위 전파되며, 블록 레벨 박스에서의 강제 줄바꿈이 같은 분절 컨텍스트 내의 부모 블록 박스로 전파되는 방식과 동일합니다. [CSS3-BREAK]
5.4. 줄바꿈 방식 선택: text-wrap-style 속성
| 이름: | text-wrap-style |
|---|---|
| 값: | auto | balance | stable | pretty |
| 초기값: | auto |
| 적용 대상: | 블록 컨테이너로서 인라인 포맷팅 컨텍스트를 생성하는 것 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
줄바꿈이 허용된 경우 (text-wrap-mode 참조), 이 속성은 줄을 감싸는 여러 방법 중 하나를 선택하며, 속도, 품질, 레이아웃 스타일 또는 안정성 간의 트레이드오프를 제공합니다. 어디에 소프트 줄바꿈 기회가 존재하는지는 바뀌지 않지만, UA가 어떤 기회를 선택할지 결정하는 방식을 바꿉니다. 가능한 값:
- auto
- 어떤 소프트 줄바꿈 기회에서 줄을 나눌지에 대한 정확한 알고리즘은 UA에서 정의합니다. 알고리즘은 브레이크 결정 시 여러 줄을 고려할 수도 있습니다. UA는 속도를 레이아웃 품질보다 우선할 수도 있습니다. UA는 balance처럼 모든 줄(마지막 줄 포함)을 균등하게 맞추려고 해서는 안 됩니다. 이 값은 UA가 선호하거나 가장 웹 호환성이 높은 줄바꿈 알고리즘을 선택합니다.
- balance
-
줄바꿈은 각 줄박스의 남은(빈) 공간이 더 잘 균등해지도록(자동보다 더 균형 있게) 선택됩니다.
5줄 이하의 경우에는 반드시 text-wrap을 auto로 설정했을 때와 동일한 줄 수를 유지해야 하며,
그 밖의 경우도 줄 수를 바꾸지 않아야 합니다.
참고: 줄에 어떤 콘텐츠가 함께 나타나는지에 따라 줄박스의 높이가 달라질 수 있습니다.
남은 공간은 플로트와 인라인 콘텐츠를 배치한 후, 텍스트 균등 분배로 인한 조정 전의 공간을 의미합니다. 줄박스들은 각 줄박스의 남은 공간의 평균 인라인 사이즈의 표준편차가 줄 전체(강제 줄바꿈이 있는 줄 포함)에서 줄어들 때 균형 잡힌 것으로 간주합니다.
강제 줄바꿈(forced line break)으로 분리된 줄 그룹은 개별적으로 처리됩니다. line-clamp가 적용된 요소는 먼저 클램핑 효과를 적용한 뒤, 남은 줄을 균형 조정합니다.
정확한 알고리즘은 UA에서 정의합니다.
10줄을 초과하면 UA는 이 값을 auto로 처리할 수 있습니다.
- stable
- 줄바꿈 결정 시 이후 줄의 콘텐츠를 고려하지 않아야 하므로, 텍스트를 편집할 때 커서 앞의 내용이 안정적으로 유지됩니다; 그 외에는 auto와 동일합니다.
- pretty
- UA는 더 좋은 레이아웃을 위해 속도보다 품질을 우선해야 하며, 줄바꿈 결정 시 여러 줄을 고려하는 것이 기대됩니다. 그 외에는 auto와 동일합니다.
참고: auto 값은 일반적으로 웹 브라우저의 빠른 레거시 줄바꿈에 매핑되며, 지금까지는 first-fit/greedy 알고리즘을 써서 최적이 아닌 결과가 자주 나왔습니다. UA는 이 기본값으로 더 나은 줄바꿈 알고리즘을 실험할 수 있지만, 최적 결과는 시간이 더 오래 걸리므로, 더 좋은 결과를 위해 pretty 값을 선택할 수 있습니다. pretty 값은 본문 텍스트에 적합하며, 마지막 줄이 평균보다 조금 짧은 것이 기대됩니다; balance 값은 제목과 캡션에 적합하며, 줄 길이가 거의 동일한 것이 선호됩니다; stable은 편집 가능하거나 토글될 가능성이 있는 섹션에 적합합니다.
- 텍스트 들여쓰기만큼은 길어야 함
- X 글자 이상
- 퍼센트 기반
값 공간에 대한 제안은 match-indent | <length> | <percentage> (예시로 Xch를 들어 해당 사용 사례를 명확히 함)입니다. 또는 <integer>로 실제 글자 수를 셀 수도 있습니다.
이 옵션이 위 줄 균형 속성과 어떻게 상호작용하는지는 불명확합니다; 이전 제안 중 하나는 같은 속성에서 100%가 완전 균형을 의미하도록 했습니다.
단어 기반 제한도 요청되었으나, 이는 단어 길이에 따라 달라지므로 글자 기반이 더 낫습니다.
5.5. 통합 줄바꿈 제어: text-wrap 단축 속성
| 이름: | text-wrap |
|---|---|
| 값: | <'text-wrap-mode'> || <'text-wrap-style'> |
| 초기값: | wrap |
| 적용 대상: | 각 개별 속성 참조 |
| 상속 여부: | 각 개별 속성 참조 |
| 백분율: | 각 개별 속성 참조 |
| 계산된 값: | 각 개별 속성 참조 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 각 개별 속성 참조 |
이 속성은 text-wrap-mode와 text-wrap-style의 단축 속성입니다. 생략된 개별 속성은 초기값으로 설정됩니다.
5.6. 줄바꿈 세부사항
줄바꿈을 결정할 때:
- 줄바꿈 처리와 양방향 텍스트의 상호작용은 CSS Writing Modes 4 § 2.4 양방향 재정렬 알고리즘 적용 및 유니코드 양방향 알고리즘(특히 UAX9§3.4 Reordering Resolved Levels)에서 정의됩니다. [CSS-WRITING-MODES-4] [UAX9]
- 명확히 다르게 정의된 경우를 제외하고
(예: line-break: anywhere 또는 overflow-wrap: anywhere)
줄바꿈 동작은
CM,SG,WJ,ZW,GL,ZWJ유니코드 줄바꿈 클래스에 대해 정의된 동작을 반드시 따라야 합니다. [UAX14] - 줄바꿈 기호가 있는 문자 외의 문장부호에서 줄바꿈을 허용하는 UA는, 해당 문자 체계에서 단어 구분자가 사용된다면 브레이크 포인트 우선순위를 조정해야 합니다. (예: 슬래시 뒤에서의 줄바꿈이 스페이스 뒤보다 낮은 우선순위면 “check /etc”는 "/"와 "e" 사이에서 줄바꿈되지 않음.) 이런 어색한 줄바꿈을 피한다면, 단어 구분자 외의 적절한 문장부호에서도 줄바꿈을 허용하는 것이 권장됩니다. 이는 특히 좁은 영역에서 더 고른 마진을 만들 수 있습니다. UA는 포함 블록의 너비, 텍스트의 언어, line-break 값, 기타 요소들을 고려해 우선순위를 정할 수 있습니다: CSS는 소프트 줄바꿈 기회의 우선순위를 정의하지 않습니다. 단어 구분자의 우선순위는 word-break: break-all이 지정된 경우 기대되지 않으며, (이 값은 명시적으로 단어 구분자 기반이 아닌 줄바꿈을 요청함) line-break: anywhere에서는 금지됩니다.
- 플로우 밖 요소와 인라인 요소 경계는 플로우 내에 강제 줄바꿈이나 소프트 줄바꿈 기회를 만들지 않습니다.
- 웹 호환성을 위해 치환 요소 또는 기타 원자 인라인 앞뒤에는 항상 소프트 줄바꿈 기회가 존재합니다. 인접 문자가 원래 줄바꿈을 억제하는 문자여도 마찬가지이며, U+00A0 줄바꿈 없는 스페이스도 포함됩니다. 단, U+00A0 줄바꿈 없는 스페이스를 제외하면, 원자 인라인과 인접한 GL, WJ, ZWJ 줄바꿈 클래스 문자 사이에는 소프트 줄바꿈 기회가 없어야 합니다. [UAX14]
- 줄바꿈 시 사라지는 문자(예: U+0020 스페이스)가 생성하는 소프트 줄바꿈 기회는 해당 문자를 직접 포함하는 박스의 속성이 줄바꿈을 제어합니다. 두 문자 또는 원자 인라인 사이 경계에서 정의된 소프트 줄바꿈 기회는 가장 가까운 공통 조상 요소의 white-space 속성이 줄바꿈을 제어합니다; 어떤 요소의 line-break, word-break, overflow-wrap 속성이 해당 경계에서 소프트 줄바꿈 기회를 어떻게 결정하는지는 이 레벨에서는 정의되지 않습니다.
- 박스의 첫 문자 앞 또는 마지막 문자 뒤의 소프트 줄바꿈 기회는 박스 내에서가 아니라 박스의 마진 엣지 바로 앞 또는 뒤에서 줄이 나뉩니다.
- Ruby 내/주변의 줄바꿈은 CSS Ruby Annotation Layout 1 § 3.4 줄을 가로지르는 분리에서 정의됩니다. [CSS-RUBY-1]
- 아랍어 등 조형이 필요한 문자에서 자동 줄바꿈이 단어 내부 소프트 줄바꿈 기회에서 발생하는 경우 (예: word-break: break-all, line-break: anywhere, overflow-wrap: break-word, overflow-wrap: anywhere, 또는 하이픈 처리 시) 해당 문자들은 단어가 온전할 때처럼 조형(결합 형태 선택)이 되어야 합니다.
6. 줄바꿈 및 단어 경계
대부분의 문자 체계에서는, 하이픈 처리가 없을 때 소프트 줄바꿈 기회가 단어 경계에서만 발생합니다. 많은 문자 체계는 스페이스나 문장부호를 이용해 명시적으로 단어를 구분하며, 소프트 줄바꿈 기회는 이런 문자로 식별됩니다.
태국어, 라오어, 크메르어 등 일부 문자 체계는 단어를 구분하기 위해 스페이스나 문장부호를 사용하지 않습니다. 이 문자들에서는 제로 폭 스페이스(U+200B)를 명시적 단어 경계로 사용할 수 있지만, 실제로는 흔하지 않습니다. 따라서 이런 텍스트에서 소프트 줄바꿈 기회를 올바르게 식별하려면 어휘 자원이 필요합니다.
또 다른 일부 문자 체계에서는 소프트 줄바꿈 기회가 단어 경계가 아닌 철자 음절 경계에 기반합니다. 이들 체계 중 자와어, 발리어 등 브라흐미 계열 문자는 줄바꿈 기회를 찾으려면 텍스트 분석이 필요합니다. SA 줄바꿈 클래스 문자를 사용하는 언어와 달리, 이 분석은 콘텐츠 언어에 의존하지 않으며, (언어별) 단어 경계 탐지나 어휘 자원을 요구하지 않습니다.
중국어(및 일본어, 이이족어, 때때로 한국어 등) 등에서는, 각 음절이 하나의 조판 글자 단위에 대응하는 경향이 있으며, 따라서 줄바꿈 관례상 특정 문자 조합 사이를 제외하고는 어디서든 줄이 나뉠 수 있습니다. 또한, 이런 제한의 엄격도는 조판 스타일에 따라 달라집니다.
CSS는 소프트 줄바꿈 기회가 정확히 어디에 발생하는지 완전히 정의하지는 않지만, 일반적인 변형을 구분할 수 있도록 몇 가지 제어를 제공합니다:
- line-break 속성은 줄바꿈 제한의 “엄격도”를 여러 수준으로 선택할 수 있게 합니다.
- word-break 속성은 어떤 종류의 글자를 결합해 끊을 수 없는 “단어”로 만들지 제어하며, CJK 문자가 일반 텍스트처럼 동작하거나 그 반대로 동작하게 하거나, 동남아시아 언어에서 단어 감지를 제어하거나, 단어를 구로 묶을 수 있게 합니다…
- hyphens 속성은 하이픈 처리되는 문자에서 자동 하이픈을 허용할지 제어합니다.
- overflow-wrap 속성은 끊을 수 없는 문자열이 오버플로우될 경우 어디든 줄을 나눌 수 있게 UA에 허용합니다.
참고: Unicode Standard Annex #14: Unicode Line Breaking Algorithm은 유니코드의 모든 문자 체계에 대한 줄바꿈의 기본 동작을 정의하며, 이는 추가 맞춤 설정될 수 있습니다. [UAX14] 줄바꿈 관례에 대한 추가 정보는 일본어의 경우 일본어 조판 요구사항 [JLREQ] 및 일본어 문서의 조판 방법 [JIS4051], 중국어의 경우 중국어 조판 요구사항 [CLREQ] 및 문장부호 일반 규칙 [ZHMARK]를 참고하세요. 국제화 작업 그룹의 언어 활성화 색인에는 더 많은 언어에 대한 정보가 있습니다. [TYPOGRAPHY] 추가로 적합한 참고문헌 안내가 있다면 언제든 환영합니다.
6.1. 글자 단위 줄바꿈 규칙: word-break 속성
| 이름: | word-break |
|---|---|
| 값: | normal | break-all | keep-all | manual | auto-phrase | break-word |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 “단어” 사이 및 내부에서 소프트 줄바꿈 기회를 지정합니다. 즉, 텍스트 줄을 “일반적으로” 어디서 나눌 수 있는지 결정합니다. 글자 사이의 줄바꿈에 초점을 맞추며, 소프트 줄바꿈 기회가 공백 또는 기타 공간 구분자에 의해 생성되는지(단, auto-phrase가 일부 억제할 수 있음), 또는 문장부호 주변에서 생성되는지에 대해서는 정의하지 않습니다. (문장부호와 소형 가나에 영향을 주는 제어는 line-break 속성을 참고하세요.)
특히 word-break는 인접한 조판 글자 단위 사이에
소프트 줄바꿈 기회가
일반적으로 존재하는지 제어합니다.
NU, AL, AI,
또는 ID 유니코드 줄바꿈 클래스에 속하는 글자가 아닌
조판 문자
단위도,
이 목적에 한해 조판 글자 단위로 취급합니다. [UAX14]

또 다른 예로, 한국어에는 두 가지 줄바꿈 방식이 있습니다: 모든 한글 음절 사이에서 줄바꿈하는 방식(word-break: normal) 또는 영어처럼 주로 공백에서만 줄바꿈하는 방식(word-break: keep-all).
각 줄의 마지막에 한글이 올 때 줄 나눔 기 준을 “글자” 또는 “어절” 단위로 한다.
각 줄의 마지막에 한글이 올 때 줄 나눔 기준을 “글자” 또는 “어절” 단위로 한다.
에티오피아어도 마찬가지로 두 가지 줄바꿈 방식이 있으며, 단어 구분자에서만 줄바꿈(word-break: normal) 또는 단어 내부 글자 사이에서도 줄바꿈 허용(word-break: break-all)이 있습니다.
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡ በማዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ ወይትጌበሩ፡አሐዱ፡ምስለ፡አሀዱ፡ በመንፈሰ፡እኍና።
ተወልዱ፡ኵሉ፡ሰብእ፡ግዑዛን፡ወዕሩያን፡በማ ዕረግ፡ወብሕግ።ቦሙ፡ኅሊና፡ወዐቅል፡ወይትጌ በሩ፡አሐዱ፡ምስለ፡አሀዱ፡በመንፈሰ፡እኍና።
각 값의 의미는 다음과 같습니다:
- normal
-
단어는 각 문자 체계의 관례에 따라 줄바꿈되며,
자세한 설명은 위 참조.
한국어의 경우 두 가지 동작이 널리 사용되는데,
모든 연속된 한글/한자 사이에서 줄바꿈을 허용합니다.
에티오피아어의 경우도 두 가지 동작이 있는데,
단어 내부 줄바꿈은 허용되지 않습니다.
일부 문자 체계는 관례적으로 기대되는 소프트 줄바꿈 기회를 얻으려면 별도의 처리가 필요합니다. 자세한 내용은 § 6.1.1 분석적 단어 줄바꿈을 참조하세요.
- break-all
-
“단어” 내부에서 줄바꿈이 허용됩니다:
구체적으로,
soft wrap
opportunities 및 normal에서 허용되는 모든 줄바꿈 외에도,
조판 글자
단위(및 조판 문자 단위 중
NU(숫자),AL(알파벳),SA(동남아시아) 줄바꿈 클래스 [UAX14]) 는 줄바꿈 목적으로ID(한자)로 취급됩니다. 하이픈 처리는 적용되지 않습니다.참고: 이 값은 소프트 줄바꿈 기회가 문장부호 문자 주변에 존재하는지에는 영향을 주지 않습니다. 어디서든 줄을 나눌 수 있게 하려면 line-break: anywhere를 참고하세요.
참고: 이 옵션은 에티오피아어의 또 다른 일반 동작을 활성화합니다. 또한 텍스트가 주로 CJK 문자로 이루어져 있고 짧은 비-CJK 구문만 포함될 때, 각 줄의 텍스트 분포가 더 고르게 되도록 자주 사용됩니다.
- keep-all
-
“단어” 내부에서 줄바꿈이 금지됩니다:
조판 글자
단위 및 조판 문자 단위 중
NU,AL,AI,ID유니코드 줄바꿈 클래스 [UAX14]에 속하는 문자 사이의 암시적 소프트 줄바꿈 기회가 억제됩니다. 즉, 해당 문자 쌍 사이에서는(아래 line-break 설정이 anywhere가 아닌 한) 줄바꿈이 금지됩니다. § 6.1.1.1 어휘 단어 줄바꿈에 따라 줄바꿈 기회가 있을 때는 예외입니다. 그렇지 않으면 이 옵션은 normal과 동일합니다. 이 스타일에서는 CJK 문자 시퀀스가 줄바꿈되지 않습니다.참고: 이것이 한국어의 또 다른 일반 동작이며 (한국어는 단어 사이에 스페이스를 사용), 스페이스로 분리되는 다른 언어와 혼합된 텍스트에서도 유용합니다.
- manual
-
normal과 동일하게 동작하지만,
§ 6.1.1.1 어휘 단어 줄바꿈은 적용하지 않아야 합니다.
즉, class SA를 가진 조판 문자 단위는 [UAX14]
class AL로 취급합니다
(즉, line-break가 anywhere가 아니라면,
해당 문자 쌍 사이에 소프트 줄바꿈 기회가 없습니다).
참고: 이 값은 발리어와 같은 언어에서 단어 내부 음절 기반 소프트 줄바꿈 기회에 영향을 주지 않습니다. (이런 문자 체계에 대한 논의는 § 6.1.1.2 철자 줄바꿈을 참고하세요.)
또는, 이 값이 keep-all이 아닌 normal을 기반으로 할 수도 있습니다. 또 다른 변형은 이 동작을 keep-all과 병합하는 것입니다.
참고: 일부 동남아시아 언어는 UA에서 잘못 감지되는 경우가 많습니다. word-break: normal일 때, UA가 언어별 논리를 부적절하게 적용하여 줄바꿈 기회를 잘못 찾아내고, 부적절한 위치에 줄바꿈을 만들 수 있습니다.예를 들어, 태국어 외에도 태국 문자로 작성되는 많은 언어가 있는데, 이들을 태국어처럼 줄바꿈하면 부적절하거나 혼란스러운 결과를 낳을 수 있습니다.
이런 상황에서, 이 값은 작성자가 UA에 내장된 단어 경계 감지를 끌 수 있게 하여 직접 줄바꿈 기회를 마크업으로 표시해 합리적인 결과를 얻을 수 있게 합니다.
이 값을 사용하는 작성자는wbr또는 U+200B를 활용해 동남아시아 언어의 단어 경계를 직접 표시해야 하며, 그렇지 않으면 소프트 줄바꿈 기회가 없어 텍스트가 오버플로우될 수 있습니다. - auto-phrase
-
normal과 동일하게 동작하지만,
UA에게 언어별 콘텐츠 분석을 수행하여 자연스러운 구(여러 단어) 단위로 묶이도록 우선하여 줄바꿈하도록 지시합니다.
요소의 콘텐츠 언어를 알 수 없거나, 해당 언어에 대해 구 경계 감지를 지원하지 않는 경우, 이 값은 normal과 동일하게 동작해야 합니다. 그렇지 않으면 UA는 구 경계 감지를 수행하고 각 구 내부에서의 소프트 줄바꿈 기회를 억제해야 합니다.
콘텐츠 언어 및 구 경계 감지 지원 여부와 관계없이, 하이픈 기회는 hyphens: none이 지정된 것처럼 억제됩니다.
참고: 한 언어용 단어 경계 감지 시스템이 해당 언어의 모든 방언에 적합한지는 주관적일 수 있으며, 이 명세는 UA의 재량에 맡깁니다. 특정 방언의 모든 미묘함을 처리하지 못하더라도, 대부분의 경우 단어 경계를 올바르게 인식하면 지원한다고 간주할 수 있습니다. 하지만 UA가 단어 경계 대부분을 감지하지 못하거나 오차율이 높으면 해당 언어에 대해 지원한다고 주장하는 것은 작성자와 사용자 모두에게 불이익이 됩니다.예를 들어, UA가 광둥어용 단어경계 감지 시스템을 갖고 있는데 중국어 전체에는 적합하지 않다면 auto-phrase는 lang=yue, lang=zh-yue, lang=zh-HK에는 적용되어야 하지만, lang=zh나 lang=zh-Hant에는 적용되지 않아야 합니다.반면, UA가 중국어 전반에 적합한 일반 단어경계 감지 시스템을 지원한다면 auto-phrase는 넓은 lang=zh 범주뿐 아니라 lang=zh-yue, lang=zh-Hant-HK, lang=zh-Hans-SG, lang=zh-hak 등에도 적용될 수 있습니다.
특정 범주 글자와 동일하게 줄바꿈되는 기호도 해당 글자와 동일하게 처리됩니다.
UA는 이 속성의 어떤 값에도 다음 소프트 줄바꿈 기회를 억제해서는 안 됩니다:
-
wbrHTML 요소 또는 U+200B 제로 폭 스페이스로 생성된 경우 -
line-break 속성에 의해 요구되는 경우
참고: 오버플로우 상황에서만 가능한 추가 줄바꿈 기회를 제어하려면 overflow-wrap을 참조하세요.
word-break의 효과는 내재 크기 계산에도 반영됩니다.
这是一些汉字 and some Latin و کمی خط عربی และตัวอย่างการเขียนภาษาไทย በጽሑፍ፡ማራዘሙን፡አንዳንድ፡
줄바꿈 위치는 다음과 같이 결정됩니다(‘·’로 표시):
- word-break: normal
-
这·是·一·些·汉·字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
- word-break: break-all
-
这·是·一·些·汉·字·a·n·d·s·o·m·e·L·a·t·i·n·و·ﮐ·ﻤ·ﻰ·ﺧ·ﻁ·ﻋ·ﺮ·ﺑ·ﻰ·แ·ล·ะ·ตั·ว·อ·ย่·า·ง·ก·า·ร·เ·ขี·ย·น·ภ·า·ษ·า·ไ·ท·ย·በ·ጽ·ሑ·ፍ፡·ማ·ራ·ዘ·ሙ·ን፡·አ·ን·ዳ·ን·ድ፡
- word-break: keep-all
-
这是一些汉字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย·በጽሑፍ፡·ማራዘሙን፡·አንዳንድ፡
아랍어처럼 조형이 필요한 문자를 break-all로 단어 내부에서 줄바꿈할 때, 해당 문자는 단어가 끊기지 않은 것처럼 조형되어야 합니다.
레거시 콘텐츠 호환성을 위해, word-break 속성은 더 이상 사용되지 않는 break-word 키워드도 지원합니다. 지정 시 word-break: normal 및 overflow-wrap: anywhere와 동일한 효과를 가지며, overflow-wrap 속성의 실제 값과 관계없이 동작합니다.
6.1.1. 분석적 단어 줄바꿈
6.1.1.1. 어휘 단어 줄바꿈
동남아시아 언어에서 기대되는 normal 동작을 제공하려면, 조판 문자 단위 중 줄바꿈 클래스 SA가 [UAX14]에 속할 경우, 클래스 AL로 간주하여 처리해야 합니다. 그러나, 사용자 에이전트는 이러한 문자 시퀀스의 내용을 추가로 분석하여 단어 경계 검출을 수행하고, 각 경계를 소프트 줄바꿈 기회로 처리해야 합니다.
여러 언어가 class SA 문자를 사용하는 문자 체계로 작성될 수 있으므로, 콘텐츠 언어가 알려진 경우, UA는 이 정보를 활용해 분석을 최적화해야 합니다.
6.1.1.2. 철자 줄바꿈
발리어 등 철자 음절 기반 줄바꿈을 사용하는 문자 체계의 경우, UA는 내용을 분석해 올바른 위치에 소프트 줄바꿈 기회를 삽입할 지점을 찾아야 합니다.
참고: 작성 시점에, 유니코드는 이 분석 방법을 정의하지 않았으며, 해당 문자 체계의 모든 문자를 class AL로 취급합니다. 하지만 해결 제안이 제출된 상태입니다. 아직 확정은 아니지만, 참고하면 도움이 될 수 있습니다. [L2-22-080R]
6.1.1.3. 대체 줄바꿈
예상치 못한 오버플로우를 방지하기 위해, UA가 줄바꿈에 필요한 어휘 또는 철자 분석을 수행할 수 없다면(예: class SA 문자를 사용하는 언어의 사전이 없는 경우) 해당 문자 체계에서 조판 글자 단위 쌍 사이에 소프트 줄바꿈 기회가 있다고 가정해야 합니다.
참고: 이 조항은 UA가 특정 텍스트 시퀀스에서 단어 경계를 못 찾았을 때 바로 적용되는 게 아니라, 해당 시퀀스가 실제로 끊을 수 없는 단어일 수도 있기 때문입니다. 예를 들어, UA가 크메르 문자(U+1780~U+17FF) 시퀀스에서 크메르어의 단어 경계를 결정할 방법을 모를 때 적용됩니다.
6.1.2. 구 기반 줄바꿈에 대한 사용자 선호 표현
UA는 사용자 선호에 따라 auto-phrase에서 서술된 언어별 콘텐츠 분석을 활성화할 수 있습니다. 이 동작을 하는 UA는 반드시 선언된 값으로 word-break를 auto-phrase로 사용자 origin에서 설정해야 합니다.
참고: 이렇게 하면 작성자가 getComputedStyle()
호출로
해당 기능 활성화 여부를 감지하거나,
필요시 작성자 origin에서 이를 오버라이드할 수 있습니다.
6.2. 줄바꿈 엄격도: line-break 속성
| 이름: | line-break |
|---|---|
| 값: | auto | loose | normal | strict | anywhere |
| 초기값: | auto |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 요소 내에서 적용되는 줄바꿈 규칙의 엄격도를 지정합니다: 특히 줄바꿈이 문장부호 및 기호와 어떻게 상호작용하는지에 대한 부분에 영향이 큽니다. 각 값의 의미는 다음과 같습니다:
- auto
- UA가 사용할 줄바꿈 제한 집합을 결정하며, 줄의 길이에 따라 제한을 가변적으로 적용할 수 있습니다; 예: 짧은 줄에는 더 덜 엄격한 줄바꿈 규칙을 사용할 수 있음.
- loose
- 가장 덜 엄격한 줄바꿈 규칙 집합을 사용해 텍스트를 나눕니다. 주로 신문 등 짧은 줄에서 사용됩니다.
- normal
- 가장 일반적인 줄바꿈 규칙 집합을 사용해 텍스트를 나눕니다.
- strict
- 가장 엄격한 줄바꿈 규칙 집합을 사용해 텍스트를 나눕니다.
- anywhere
-
모든 조판 문자 단위 주변,
즉 문장부호 문자나 보존된 공백 주변,
또는 단어 내부 어디든 소프트 줄바꿈 기회가 생깁니다.
줄바꿈 금지 규정을 무시하며,
GL, WJ, ZWJ 줄바꿈 클래스 문자로 인해 금지되는 줄바꿈도 무시합니다.
word-break 속성으로 금지된 줄바꿈도 무시합니다. [UAX14] 여러 줄바꿈 기회는 우선순위를 두지 않습니다.
하이픈 처리는 적용되지 않습니다.
참고: 이 값은 터미널 등에서 흔히 보이는 줄바꿈 규칙을 활성화합니다.
참고: 이 값은 조판 문자 단위 사이에서만 소프트 줄바꿈 기회를 생성하며, 그 내부에는 생성하지 않습니다. 따라서
CM및SG유니코드 줄바꿈 클래스는 반드시 준수해야 합니다. [UAX14]참고: anywhere는 보존된 공백이 줄 끝에 있을 때 줄바꿈을 허용하는데, white-space가 break-spaces일 때만 적용됩니다. 나머지 경우에는:실제 보존된 공백에 영향을 미칠 때, white-space: break-spaces와 함께라면, 시퀀스의 첫 번째 스페이스 앞에서 줄바꿈을 허용합니다. 이는 break-spaces만으로는 불가능합니다.
CSS는 텍스트 줄바꿈 규칙의 엄격도에 대해 네 가지 수준을 구분합니다. loose, normal, strict 각각에 적용되는 정확한 규칙 집합은 UA에 따라 달라지며, 언어 관례를 따라야 합니다. 다만, 본 명세에서는 다음을 요구합니다:
-
아래 줄바꿈은 strict 줄바꿈에서 금지되고,
normal 및 loose에서 허용됩니다:
- 일본어 소형 가나 또는 가타카나-히라가나 장음부호 앞에서의 줄바꿈,
즉 유니코드 줄바꿈 클래스
CJ문자.[UAX14]
- 일본어 소형 가나 또는 가타카나-히라가나 장음부호 앞에서의 줄바꿈,
즉 유니코드 줄바꿈 클래스
-
아래 줄바꿈은 normal 및 loose 줄바꿈에서,
문자 체계가
중국어 또는 일본어일
때만 허용되고,
그 외에는 금지됩니다:
- 특정 CJK 하이픈류 문자 앞에서 줄바꿈:
〜 U+301C, ゠ U+30A0
- 특정 CJK 하이픈류 문자 앞에서 줄바꿈:
-
아래 줄바꿈은 loose 줄바꿈에서만 허용됩니다.
앞 문자가 유니코드 줄바꿈 클래스
ID[UAX14]에 속할 경우(또는 word-break: break-all에 의해ID로 취급되는 경우도 포함), 그 외에는 금지됩니다:- 하이픈 앞에서 줄바꿈:
‐ U+2010, – U+2013
- 하이픈 앞에서 줄바꿈:
-
아래 줄바꿈은 normal 및 strict에서 금지되고,
loose에서 허용됩니다:
- 반복 기호 앞에서 줄바꿈:
々 U+3005, 〻 U+303B, ゝ U+309D, ゞ U+309E, ヽ U+30FD, ヾ U+30FE - 불가분 문자 사이에서 줄바꿈
(예: ‥ U+2025, … U+2026)
즉 유니코드 줄바꿈 클래스
IN문자.[UAX14]
- 반복 기호 앞에서 줄바꿈:
- 아래 줄바꿈은 loose에서만 허용되며, 문자 체계가 중국어 또는 일본어일 때만 허용되고, 그 외에는 금지됩니다:
참고: 위 요구사항은 CJK 텍스트에서만 차이를 만듭니다. 위 규칙만 적용하고 추가 규칙이 없다면, line-break는 CJK 코드 포인트에만 영향을 주며, 문자 체계가 중국어나 일본어로 태그된 경우에만 적용됩니다. 이후 버전에서는 다른 문자 체계 및 언어의 요구가 밝혀지면, 추가적인 규칙이 추가될 수 있습니다.
-
U+0021(느낌표,
!)와 글자(유니코드 일반 범주L) 사이에는 줄바꿈 기회를 만들지 않음. 이렇게 하면 "!important" 문자열이 분리되지 않습니다. -
U+002F(슬래시,
/)와 글자(유니코드 일반 범주L) 사이에는 줄바꿈 기회를 만들지 않음. 이렇게 하면 "23/Jan/2024" 날짜가 분리되지 않습니다. -
U+007C(수직선,
|)와 글자(유니코드 일반 범주L) 사이에는 줄바꿈 기회를 만들지 않음. -
U+002D(하이픈 마이너스 `-`)와 숫자(유니코드 일반 범주
Nd) 사이에, 하이픈 앞 코드포인트가 글자나 숫자가 아니라면 줄바꿈 기회를 만들지 않음 (유니코드 일반 범주L또는Nd). 이렇게 하면 "-13"과 같은 숫자 앞에서는 분리되지 않으면서, "ABCD-1234"나 "1234-5678"처럼 긴 URL 등에서는 하이픈 뒤에서 줄바꿈이 허용됩니다.
참고: CSSWG는 향후 판에서 고급 출판 요구를 위해 줄바꿈에 대한 더 세밀한 제어가 필요할 수 있음을 인지하고 있습니다.
6.3. 하이픈 처리: 단어 내부 형태소 단위 줄바꿈
6.3.1. 하이픈 제어: hyphens 속성
하이픈 처리는 일반적으로 허용되지 않는 위치에서 단어를 분리하여 문단 레이아웃을 개선하는 제어된 작업입니다. 보통 음절 또는 형태소 경계에서 단어를 분리하며, 분리된 위치를 시각적으로 표시하는 경우가 많습니다(대부분 하이픈(U+2010)을 삽입). 경우에 따라 하이픈 처리 시 단어 철자가 바뀌기도 합니다. 하이픈 처리는 어디까지나 렌더링 효과일 뿐이며, 기본 문서 내용이나 텍스트 선택·검색에는 영향을 주지 않아야 합니다.
| 언어 | 분리 없음 | 분리 전 | 분리 후 |
|---|---|---|---|
| 영어 | Unbroken | Un‐ | broken |
| 네덜란드어 | cafeetje | café‐ | tje |
| 헝가리어 | Összeg | Ösz‐ | szeg |
| 중국어(만다린) | tú’àn | tú‐ | àn |
| àizēng‐fēnmíng | àizēng‐ | ‐fēnmíng | |
| 위구르어 | ![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-unbroken.svg)
| ![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen ]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined-before.svg)
| ![[ isolated DAL + isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined-after.svg)
|
| 크리어 | ![[ᑲᓯᑕᓂᐘᓂᓂᐠ]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-4/images/cree.svg)
| ![[ᑲᓯᑕᓂ᐀]
(CANADIAN SYLLABICS KA +
CANADIAN SYLLABICS SI +
CANADIAN SYLLABICS TA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS HYPHEN)](https://www.w3.org/TR/css-text-4/images/cree-before.svg)
| ![[ᐘᓂᓂᐠ]
(CANADIAN SYLLABICS WEST-CREE WA +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS NI +
CANADIAN SYLLABICS FINAL GRAVE)](https://www.w3.org/TR/css-text-4/images/cree-after.svg)
|
하이픈 처리는 줄이 유효한 하이픈 처리 지점에서 끊길 때 발생합니다. 이는 단어 내부에서 하이픈 처리가 허용된 위치에 존재하는 소프트 줄바꿈 기회의 한 종류입니다. CSS에서는 하이픈 처리 지점을 hyphens 속성으로 제어합니다. CSS Text Level 3는 정확한 하이픈 처리 규칙을 정의하지 않지만, UA는 브레이크 포인트 선택을 최적화하고, 각 언어에 맞는 하이픈 처리 지점을 선택하는 것이 권장됩니다.
참고: U+002D 하이픈-마이너스 문자나 U+2010 하이픈 문자가 생성하는 소프트 줄바꿈 기회는 하이픈 처리 지점이 아닙니다. 줄바꿈할 때 분리 표시가 생성되지 않기 때문입니다: 이런 문자는 줄이 그 위치에서 감싸지든 아니든 항상 표시됩니다.
하이픈 처리 지점은 min-content 내재 크기 계산에 포함됩니다.
참고: 이로 인해 테이블은 내용이 컨테이너 블록을 넘치지 않고 하이픈 처리를 할 수 있으며, 이는 독일어처럼 단어가 긴 언어에서 특히 중요합니다.
| 이름: | hyphens |
|---|---|
| 값: | none | manual | auto |
| 초기값: | manual |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 단어 내부에서 하이픈 처리로 소프트 줄바꿈 기회를 더 많이 만들 수 있는지 제어합니다. 각 값의 의미는 다음과 같습니다:
- none
-
단어는 하이픈 처리되지 않습니다.
단어 내부에 하이픈
처리 지점이 명시적으로 정의되어 있어도 마찬가지입니다.
참고: 이는 항상 보이는 문자(U+002D 하이픈-마이너스, U+2010 하이픈 등)로 생성된 소프트 줄바꿈 기회는 억제하지 않습니다.
- manual
-
단어 내부에 명시적으로 하이픈 처리 지점을 제시하는 문자가 있을 때만 하이픈 처리가 됩니다.
UA는 해당 언어에 맞는 하이픈 문자를 반드시 사용해야 하며,
자동 하이픈 처리와 동일한 위치에서 필요한 철자 변경도 적용해야 합니다.
유니코드에서 U+00AD는 조건부 "소프트 하이픈"이고 U+2010은 무조건 하이픈입니다. Unicode Standard Annex #14는 유니코드 줄바꿈에서 소프트 하이픈의 역할을 설명합니다. [UAX14] HTML에서는 ­가 소프트 하이픈 문자를 나타내며, 줄바꿈 지점을 제안합니다.
ex
­ ample - auto
- 단어는 언어에 맞는 하이픈 리소스에 의해 자동으로 결정된 하이픈 처리 지점에서뿐 아니라, 조건부 하이픈으로 명시된 위치에서도 나뉠 수 있습니다. 단어에 조건부 하이픈이 있을 경우, 다른 자동 하이픈 처리 지점은 무시되어야 하며, 반드시 조건부 하이픈 위치에서만 줄이 나뉩니다. 단, 조건부 하이픈 위치에서 분리해도 단어 일부가 한 줄에 들어갈 수 없을 경우, 추가 자동 하이픈 처리 지점도 사용할 수 있습니다.
올바른 자동 하이픈 처리를 위해서는 텍스트의 언어에 맞는 하이픈 리소스가 필요합니다. 따라서 UA는 콘텐츠 언어가 알려져 있고, 해당 언어에 맞는 하이픈 리소스를 갖춘 텍스트에만 자동 하이픈 처리를 적용해야 합니다.
UA는 언어별 휴리스틱을 사용해 특정 단어를 자동 하이픈 처리에서 제외할 수 있습니다. 예를 들어, UA는 대소문자 및 문장부호 패턴을 참고해 고유명사에서는 하이픈 처리를 피하려 할 수 있습니다. 이런 휴리스틱은 본 명세에서 정의하지 않습니다. (휴리스틱은 언어마다 달라야 하며, 예를 들어 영어와 독일어는 대소문자 관례가 매우 다름을 참고하세요.)
hyphens 속성에서 "단어"의 정의는 UA에 따라 다릅니다. 다만, 인라인 요소 경계 및 플로우 밖 요소는 단어 경계 결정 시 무시해야 합니다.
조건부 하이픈 문자(예: U+00AD 소프트 하이픈)로 생성된 하이픈 처리 지점에서 하이픈 처리로 보이는 글리프는 해당 문자로 표현되며, 그 문자에 적용된 스타일로 렌더링됩니다.
아랍어처럼 조형이 필요한 문자를 하이픈 처리로 단어 내부에서 줄바꿈할 때, 해당 문자는 단어가 끊기지 않은 것처럼 조형되어야 합니다.
![[isolated DAL + isolated ALEF + initial MEEM +
medial YEH + hyphen + line-break + final DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-joined.svg) 처럼 보여야 하며,
처럼 보여야 하며,
![[isolated DAL + isolated ALEF + initial MEEM +
final YEH + hyphen + line-break + isolated DAL +
isolated ALEF MAKSURA]](https://www.w3.org/TR/css-text-4/images/uyghur-hyphenate-unjoined.svg) 처럼 보이면 안 됩니다.
처럼 보이면 안 됩니다.
6.3.2. 하이픈 문자: hyphenate-character 속성
| 이름: | hyphenate-character |
|---|---|
| 값: | auto | <string> |
| 초기값: | auto |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 하이픈 처리된 단어의 각 부분 사이에 표시되는 문자열을 지정합니다. 값의 의미는 다음과 같습니다:
- auto
- UA가 콘텐츠 언어의 조판 관례에 따라 적절한 문자열을 찾도록 지정합니다. 필요한 경우 하이픈 사전과 같은 리소스에서 가져올 수 있습니다.
- <string>
-
하이픈 처리 시 분리 위치에 표시될 문자열을 지정합니다.
(이 문자열의 위치는 영향을 받지 않으며,
UA는 콘텐츠 언어의 조판 관례에
따라 문자열을 삽입해야 하며,
기본적으로 하이픈 분리 바로 앞에 삽입됩니다.)
UA는 사용된 값을 일정한 조판 문자 단위 개수로 잘라낼 수도 있습니다;
하지만 조판 문자 단위 일부만 잘라내서는 안 됩니다.
참고: 빈 문자열 ""을 지정하는 것도 유효하며, UA가 하이픈 처리 지점에서 보이는 하이픈 문자 없이 줄바꿈을 하게 됩니다.
[lang]:lang(ojs) { hyphenate-character: "᐀" /* 캐나다 음절 하이픈(U+1400) */ }
참고: 자동 하이픈 처리로 생성된 하이픈과 소프트 하이픈에 의해 생성된 하이픈 모두 hyphenate-character에 따라 렌더링됩니다.
6.3.3. 하이픈 처리 영역 한계: hyphenate-limit-zone 속성
| 이름: | hyphenate-limit-zone |
|---|---|
| 값: | <length-percentage> |
| 초기값: | 0 |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 줄박스 길이 기준 |
| 계산된 값: | 계산된 <length-percentage> 값 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 계산된 값 타입별 |
hyphenate-limit-zone 이름이 적합한가요? 의견/제안?
이 속성은 줄박스 내(정렬 전)에 남겨질 수 있는 최대 미채움 영역(공간)을 지정하며, 이 영역보다 더 남으면 하이픈 처리로 다음 줄 일부를 현재 줄로 끌어올립니다.
6.3.4. 하이픈 처리 시 문자 수 한계: hyphenate-limit-chars 속성
| 이름: | hyphenate-limit-chars |
|---|---|
| 값: | [ auto | <integer> ]{1,3} |
| 초기값: | auto |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 세 개의 값, 각각 auto 키워드 또는 정수 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 계산된 값 타입별 |
이 속성은 하이픈 처리된 단어의 최소 문자 수를 지정합니다. 해당 단어가 전체/하이픈 앞/하이픈 뒤 최소 문자 수 조건을 만족하지 않으면 하이픈 처리가 금지됩니다. 유니코드 일반 범주 Mn(비간격 조합 기호) 및 단어 내부 문장부호(유니코드 일반 범주 P*)는 최소 문자 수에 포함되지 않습니다.
값을 세 개 지정하면 첫 번째 값은 단어 전체 최소 문자 수, 두 번째는 하이픈 처리 전 최소 문자 수, 세 번째는 하이픈 처리 후 최소 문자 수입니다. 세 번째 값이 없으면 두 번째 값과 같습니다. 두 번째 값이 없으면 auto입니다. auto 값은 UA가 현재 레이아웃에 맞게 값을 선택함을 의미합니다.
참고: UA가 더 나은 값을 계산할 수 없는 경우, auto는 하이픈 앞·뒤는 2, 전체 단어는 5로 권장됩니다.
p { hyphenate-limit-chars: auto 3; }
6.3.5. 하이픈 처리 줄 수 한계: hyphenate-limit-lines 및 hyphenate-limit-last 속성
| 이름: | hyphenate-limit-lines |
|---|---|
| 값: | no-limit | <integer> |
| 초기값: | no-limit |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 또는 정수 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 계산된 값 타입별 |
이 속성은 요소에서 연속적으로 하이픈 처리된 줄의 최대 개수를 나타냅니다. no-limit 값은 제한이 없음을 의미합니다.
경우에 따라 UA가 지정된 값을 지킬 수 없는 상황이 있을 수 있습니다. (overflow-wrap 참조) 이런 비상 줄바꿈으로 인한 하이픈 처리 지점이 인접 하이픈 처리 위치에 영향을 주는지 여부는 정의되어 있지 않습니다.
| 이름: | hyphenate-limit-last |
|---|---|
| 값: | none | always | column | page | spread |
| 초기값: | none |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 요소, 컬럼, 페이지, 스프레드의 끝에서 하이픈 처리 동작을 지정합니다. 스프레드는 독자가 동시에 볼 수 있는 두 페이지 집합입니다. 값의 의미는 다음과 같습니다:
- none
- 제한 없음.
- always
- 요소의 마지막 완전 줄, 또는 요소 내부 컬럼/페이지/스프레드 분리 바로 전의 마지막 줄에서는 하이픈 처리하지 않아야 합니다.
- column
- 요소 내부 컬럼/페이지/스프레드 분리 바로 전의 마지막 줄에서는 하이픈 처리하지 않아야 합니다.
- page
- 요소 내부 페이지/스프레드 분리 바로 전의 마지막 줄에서는 하이픈 처리하지 않아야 합니다.
- spread
- 요소 내부 스프레드 분리 바로 전의 마지막 줄에서는 하이픈 처리하지 않아야 합니다.
아래처럼 hyphenate-limit-last: none 설정 시 문단이 형식화될 수 있습니다:
This is just a simple example to show Antarc- tica.
'hyphenate-limit-last: always'일 경우 다음과 같이 됩니다:
This is just a simple example to show Antarctica.
6.4. 오버플로우 줄바꿈: overflow-wrap/word-wrap 속성
| 이름: | overflow-wrap, word-wrap |
|---|---|
| 값: | normal | break-word | anywhere |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 UA가 줄 내에서 원래 허용되지 않는 위치에서 줄을 나눌 수 있는지(오버플로우 방지), 즉 줄박스를 넘길 정도로 긴 끊을 수 없는 문자열이 있을 때 줄바꿈을 허용할 수 있는지를 지정합니다. white-space가 줄바꿈을 허용할 때만 효과가 있습니다. 가능한 값:
- normal
-
줄은 허용된 브레이크 포인트에서만 나뉩니다.
단,
word-break: keep-all로 인해 생긴 제한은
해당 줄에 허용되는 다른 브레이크 포인트가 없으면 word-break:
normal처럼 완화될 수 있습니다.
또한 word-break: auto-phrase로 인한 제한도 줄에 허용 가능한 브레이크 포인트가 없으면 완화됩니다:
- 특정 구 내부에서 소프트 줄바꿈 기회 억제 시, 해당 구가 빈 줄에 배치해도 오버플로우가 난다면, UA는 해당 구 내부에서 normal과 동일한 소프트 줄바꿈 기회로 대체해야 합니다.
- 그래도 오버플로우가 발생하면, 해당 줄에서는 하이픈 처리 지점 억제도 포기해야 합니다.
- 중간 단계로, UA는 여러 단계의 구를 감지해, 더 짧은 구(필요시 단어 단위까지)를 선택할 수 있습니다.
소프트 줄바꿈 기회는 word-break: keep-all 및 word-break: auto-phrase로 인한 제한을 완화해 얻은 경우 min-content 내재 크기 계산에는 포함되지 않습니다.
- anywhere
-
허용되는 브레이크 포인트가 없을 경우,
원래 끊을 수 없는 문자 시퀀스도 임의 위치에서 줄바꿈할 수
있습니다.
조형 문자는 단어가 나뉘지 않은 것처럼 조형되고,
그래프 클러스터는 반드시 하나의 단위로 유지됩니다.
브레이크 위치에 하이픈 문자는 삽입되지 않습니다.
소프트 줄바꿈
기회는
anywhere로 생성된 경우 min-content 내재
크기 계산에 포함됩니다.
word-break: auto-phrase의 경우, 추가 소프트 줄바꿈 기회는 word-break: auto-phrase로 인한 제한 완화(overflow-wrap: normal 참조)로도 오버플로우가 막히지 않을 때만 생성됩니다.
- break-word
- anywhere와 동일하지만, break-word로 생성된 소프트 줄바꿈 기회는 min-content 내재 크기 계산에는 포함되지 않습니다.
overflow-wrap에
none 값을 추가해 keep-all' 및 auto-phrase'' 제한 완화(overflow-wrap: normal 허용)를
명시적으로 선택 해제할 필요가 있을까요?
레거시 호환을 위해, UA는 word-wrap을 레거시 이름 별칭으로 처리해야 하며, overflow-wrap과 동일하게 동작해야 합니다.
7. 정렬 및 자간
정렬 및 자간은 인라인 콘텐츠가 줄박스 내에서 어떻게 분포될지 제어합니다.
7.1. 텍스트 정렬: text-align 단축 속성
| 이름: | text-align |
|---|---|
| 값: | start | end | left | right | center | <string> | justify | match-parent | justify-all |
| 초기값: | start |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 각 개별 속성 참조 |
| 계산된 값: | 각 개별 속성 참조 |
| 애니메이션 타입: | 불연속 |
| 정규 순서: | 해당 없음 |
이 단축 속성은 text-align-all 및 text-align-last 속성을 설정하며, 블록의 인라인 레벨 콘텐츠가 인라인 축을 따라 어떻게 정렬될지(줄박스를 완전히 채우지 않을 경우) 기술합니다. justify-all 또는 match-parent가 아닌 값은 text-align-all에 할당되고, text-align-last는 auto로 초기화됩니다.
각 값의 의미는 다음과 같습니다:
- start
- 인라인 레벨 콘텐츠가 줄박스의 start 엣지에 맞춰 정렬됩니다.
- end
- 인라인 레벨 콘텐츠가 줄박스의 end 엣지에 맞춰 정렬됩니다.
- left
- 인라인 레벨 콘텐츠가 줄박스의 line-left 엣지에 맞춰 정렬됩니다. (수직 쓰기 모드에서는, writing-mode에 따라 물리적 위 또는 아래가 될 수 있습니다.) [CSS-WRITING-MODES-4]
- right
- 인라인 레벨 콘텐츠가 줄박스의 line-right 엣지에 맞춰 정렬됩니다. (수직 쓰기 모드에서는, writing-mode에 따라 물리적 위 또는 아래가 될 수 있습니다.) [CSS-WRITING-MODES-4]
- center
- 인라인 레벨 콘텐츠가 줄박스 내에서 가운데 정렬됩니다.
- <string>
- 문자열은 반드시 단일 문자여야 하며; 그렇지 않으면 선언은 무효이며 무시되어야 합니다. 테이블 셀에 적용할 경우, 셀의 내용이 해당 문자 기준으로 정렬됨을 지정합니다(정렬 문자). 자세한 내용 및 키워드와의 조합 방식은 아래 참조.
- justify
- 텍스트는 text-justify 속성에 지정된 방식으로 줄박스를 정확히 채우도록 자간을 조정해 정렬됩니다. text-align-last에서 별도로 지정하지 않은 한, 강제 줄바꿈 전 또는 블록의 마지막 줄은 start로 정렬됩니다.
- justify-all
- text-align-all과 text-align-last를 모두 justify로 설정하여 마지막 줄까지 강제 자간 정렬합니다.
- match-parent
-
이 값은 inherit(부모의 계산값을 상속)과 동일하게 동작하나,
부모의 start 또는 end 상속값은
부모의 direction 값에 따라 해석되어 계산값이 left 또는 right가 됩니다.
루트 요소에 지정하면 start로 계산됩니다.
text-align 단축 속성에 지정하면, text-align-all과 text-align-last를 모두 match-parent로 설정합니다.
텍스트 블록은 줄박스들의 스택입니다. 이 속성은 각 줄박스 내 인라인 레벨 박스들이 줄박스 시작/끝 방향에 대해 어떻게 정렬될지 지정합니다. 정렬은 뷰포트나 포함 블록 기준이 아닙니다.
justify의 경우, UA는 인라인 박스를 텍스트 조정을 통해 늘이거나 줄일 수 있습니다. (text-justify 참조.) 요소의 공백이 병합 가능하지 않으면, UA는 자간 조정을 반드시 하지 않아도 되며, 대신 텍스트에 자간 조정 기회가 없는 것으로 처리할 수 있습니다. UA가 텍스트를 조정하기로 했다면, 탭 스톱이 공백 처리 규칙에 따라 계속 정렬되는지도 보장해야 합니다.
(자간 조정 후를 포함하여) 줄박스의 인라인 콘텐츠가 박스에 너무 길어 들어가지 않으면, 콘텐츠는 start로 정렬되며, 들어가지 못한 부분은 줄박스의 end 엣지에서 오버플로우됩니다.
§ 9.3 양방향성 및 줄박스에서 줄박스의 start 및 end 엣지 결정 방법을 확인할 수 있습니다.
7.2. 테이블 열에서의 문자 기반 정렬
컬럼 내 여러 셀에 정렬 문자가 지정된 경우, 해당 컬럼의 각 셀의 정렬 문자가 하나의 컬럼 평행축에 맞춰 중앙에 정렬되고, 컬럼 내 나머지 텍스트는 이에 맞춰 이동됩니다. (각 셀의 문자열이 반드시 같을 필요는 없지만, 보통은 같습니다.)
여기서 "정렬 문자의 중심"을 맞춘다는 의미인가요? 실제로 그런지 명확하지 않으니, 각 셀의 정렬 문자가 서로 다른 폰트일 때 어떤 처리가 되는지 (혹은 다른 동작인지) 명세가 필요합니다. (특히, 볼드와 일반 텍스트처럼 굵기만 살짝 다른 게 가장 중요한 사례일 듯합니다.) [피드백] [2016-02-02 10:00 AM 대면 회의록]
아래 스타일 시트:
TD { text-align: "." center }
다음 HTML 테이블의 달러 금액 컬럼에 적용하면:
<TABLE> <COL width="40"> <TR> <TH>Long distance calls <TR> <TD> $1.30 <TR> <TD> $2.50 <TR> <TD> $10.80 <TR> <TD> $111.01 <TR> <TD> $85. <TR> <TD> N/A <TR> <TD> $.05 <TR> <TD> $.06 </TABLE>
소수점 기준으로 정렬됩니다. 표는 아래처럼 렌더링될 수 있습니다:
+---------------------+ | Long distance calls | +---------------------+ | $1.30 | | $2.50 | | $10.80 | | $111.01 | | $85. | | N/A | | $.05 | | $.06 | +---------------------+
<string> 값과 함께 키워드 값을 지정할 수 있습니다; 지정하지 않으면 기본값은 right입니다. 이 값은 아래 상황에서 사용됩니다:
- 문자 기반 정렬이 테이블 셀이 아닌 박스에 적용될 때
- 텍스트가 여러 줄로 감싸질 때(강제되지 않은 줄바꿈 위치)
- 문자 정렬 셀이 여러 컬럼을 병합하는 경우. 이 경우 키워드 정렬 값에 따라 어느 컬럼 축에 맞출지 결정: left는 가장 왼쪽 컬럼, right와 center는 가장 오른쪽 컬럼, start는 가장 시작 컬럼, end는 가장 끝 컬럼.
- 컬럼이 충분히 넓어 문자 정렬만으로 셀의 위치가 결정되지 않을 때. 이 경우 컬럼 내 첫 번째 정렬 문자 지정 셀의 키워드 정렬 값을 기준으로 문자 정렬 셀의 위치를 최대한 키워드 정렬에 맞게 조정(컬럼 너비는 변경하지 않음). center의 경우, UA는 정렬된 콘텐츠의 양쪽 극단을 사용해 중앙 정렬하거나, 정렬축 자체를 중앙에 맞추거나(가능한 한), 기타 다른 방식(예: 셀 콘텐츠의 축 양쪽 범위의 가중 평균)을 쓸 수 있습니다.
참고: 문자 기반 정렬은 기본적으로 오른쪽 정렬인데, 거의 모든 숫자 체계가 좌→우이기 때문에 문자 기반 정렬의 주요 용도가 숫자 정렬이기 때문입니다.
정렬 문자가 텍스트에 여러 번 등장하면, 첫 번째 인스턴스가 정렬 기준이 됩니다. 셀에 정렬 문자가 전혀 없다면, 그 셀은 정렬 문자가 내용 끝에 삽입된 것처럼 정렬됩니다.
정렬 문자 검색 시 어떤 텍스트를 대상으로 해야 하는지 명세가 필요합니다. 셀의 포함 블록에 있는 flow 내 텍스트만인가요? 아니면 셀에서 형성된 블록 포맷팅 컨텍스트 내의 모든 flow 내 자손도 포함인가요? 포함이라면 셀의 text-align 속성과 일치해야만 포함인가요? (정렬 문자만 일치하면 되는지, 전체 속성이 일치해야 하는지?)
정렬 문자가 셀 내용 끝에 삽입된 것처럼 정렬할 때, 문자 중심 정렬과 결합하면 컬럼에서 정렬 문자가 없는 줄이 단독으로 있을 때 (혹은 컬럼이 max-content 너비가 아닐 때 정렬 문자가 있는 줄이 일부만 있을 때) 줄의 끝 방향에 빈 공간이 생길 수 있습니다. 이는 바람직하지 않을 수도 있습니다.
정렬 문자를 셀 내용 끝에 삽입할 때 어떤 폰트를 사용하나요? (특히, 정렬 문자가 자손 블록 내에 있을 때 블록 폰트인지, 테이블 셀 폰트인지? 또는 인라인 내 강제 줄바꿈 뒤에 삽입할 때 인라인 폰트인지, 블록/셀 폰트인지?)
문자 기반 정렬은 테이블 셀 너비 계산 전에 발생하므로, 자동 너비 계산이 정렬에 필요한 충분한 공간을 남길 수 있습니다. 컬럼 병합 셀이 정렬에 너비 계산 전 참여하는지 후 참여하는지 명확하지 않습니다. 셀 내용의 너비 제한으로 인해 전체 컬럼에서 완전한 정렬이 불가능하면, 그 결과 정렬은 정의되지 않습니다.
문자 정렬이 테이블 컬럼 및 테이블 셀에 들어갈 수 있는 모든 콘텐츠의 min-content/max-content 내재 너비에 어떻게 영향을 주는지 공식 정의가 필요합니다. max-content 내재 너비는 세 개의 숫자로 쪼개야 합니다(정렬 문자의 중심이 맞춰진다고 가정할 때): 정렬 문자가 없는 너비, 정렬 문자 중심의 인라인 시작쪽 너비, 인라인 끝쪽 너비. 이는 강제 줄바꿈 사이의 각 텍스트 세그먼트 대상으로 동작합니다. min-content 너비는 강제 줄바꿈 사이의 선택적 줄바꿈이 있는 세그먼트의 경우 정렬 문자 없는 너비에만 기여해야 합니다. 다만, 모든 min-content 너비가 이렇게 동작해야 하는지, 또는 강제 줄바꿈 사이에 선택적 줄바꿈이 없는 세그먼트(정렬 문자 실제 포함하는 경우만?) 가 시작/끝쪽 min-content 너비에 기여해야 하는지 명확하지 않습니다; 이는 테이블의 min-content 크기가 가장 좁은 합리적 크기냐, 더 많은 경우에 정렬 문자를 존중할지 간의 트레이드오프입니다. 또 다른 옵션은 선택적 줄바꿈 허용 여부로 어느 동작을 쓸지 결정하는 것입니다.
컬럼 병합 셀의 <string> 값 text-align의 내재 너비 기여 공식 정의가 필요합니다. 이는 비병합 셀의 내재 너비 기여 정의를 확장한 복잡하지만 명확한 작업입니다; 기여는 정렬 기준 컬럼의 분할 내재 너비와, 나머지 병합 컬럼의 정렬 문자 없는 내재 너비에 반영됩니다.
7.3. 기본 텍스트 정렬: text-align-all 속성
| 이름: | text-align-all |
|---|---|
| 값: | start | end | left | right | center | <string> | justify | match-parent |
| 초기값: | start |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드(단, match-parent는 위 정의에 따라 계산) |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 text-align 단축 속성의 개별 속성(longhand)으로, 블록 컨테이너 내 모든 인라인 콘텐츠의 각 줄 인라인 정렬을 지정합니다. 단, auto가 아닌 text-align-last 값으로 오버라이드된 마지막 줄은 제외합니다. 값 설명은 text-align 참고.
작성자는 이 속성 대신 text-align 단축 속성을 사용할 것을 권장합니다.
7.4. 마지막 줄 정렬: text-align-last 속성
| 이름: | text-align-last |
|---|---|
| 값: | auto | start | end | left | right | center | justify | match-parent |
| 초기값: | auto |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드(단, match-parent는 위 정의에 따라 계산) |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 블록의 마지막 줄 또는 강제 줄바꿈 바로 앞 줄의 정렬 방식을 지정합니다.
auto가 지정되면, 해당 줄의 콘텐츠는 text-align-all 기준으로 정렬되지만, text-align-all이 justify일 때는 start로 정렬됩니다. 그 외 값은 text-align 설명에 따릅니다.
7.5. 자간 정렬 방식: text-justify 속성
| 이름: | text-justify |
|---|---|
| 값: | [ auto | none | inter-word | inter-character | ruby ] || no-compress |
| 초기값: | auto |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드(단, distribute 레거시 값 제외) |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 불연속 |
이 속성은 줄의 정렬이 justify일 때(text-align 참조) 사용하는 자간 정렬 방식을 선택합니다. 이 속성은 텍스트에 적용되며, 블록 컨테이너에서 그 인라인 콘텐츠를 감싸는 루트 인라인 박스에 상속됩니다. 다음과 같은 값이 있습니다:
- auto
-
UA가 품질과 성능의 균형에 따라 자간 알고리즘을 결정합니다.
자간 규칙은 문자
체계와 언어마다
다르므로,
UA는 가능하면 텍스트에 맞는 자간 알고리즘을 사용해야 합니다.
예를 들어, UA는 기본적으로 모든 문자 체계에 적용 가능한 보편적 절충 자간 방식을 사용할 수 있습니다—예를 들어 단어 구분자와 CJK 조판 글자 단위 사이를 주로 늘리고, 동남아 조판 글자 단위 사이도 보조적으로 늘립니다. 문단의 콘텐츠 언어를 알 수 있을 때는 각 언어에 맞는 자간 알고리즘(예: 일본어는 일본어 조판 요구사항 [JLREQ], 아랍어는 서법적 신장, 독일어는 inter-word 등)을 선택할 수 있습니다.

아랍어 서법 자간 정렬 예시 (Tasmeem 제작). 영어처럼, 아랍어도 단어 사이 간격을 조정해 자간 정렬할 수 있지만, 대부분은 글자 자체를 서법적으로 늘리거나 압축해서 자간 정렬합니다. 이 예시에서는, 윗줄은 늘어난(kashida) 형태와 스와시 형태로 늘리고, 아랫줄은 ت와 م 사이 문자를 합자 조합으로 압축해 줄 길이를 맞춥니다. 전통 서법 기술을 활용하면 흐름과 색상을 유지하면서 매우 높은 품질의 자간 정렬을 할 수 있습니다. 단, 이런 효과는 문자별로 매우 특화된 방식입니다. 
text-justify: auto가 적용된 혼합 문자 텍스트: 여기서는 보편적 절충 방식으로 스페이스뿐 아니라 CJK 및 동남아시아 문자 사이도 늘립니다. 즉, 단어 구분자나 CJK 문자가 있는 줄은 inter-word + inter-ideograph, 그 외에는 inter-cluster로 동작합니다. - none
-
자간 정렬을 사용하지 않음:
텍스트 내부에 자간 조정 기회가 없습니다.
text-justify: none가 적용된 혼합 문자 텍스트 참고: 이 값은 가독성 또는 접근성을 위해 사용자 스타일시트에서 사용하도록 의도되었습니다.
- inter-word
-
자간 정렬은 단어 구분자에서만 간격을
조정합니다
(실제로는 word-spacing을 조정).
이 방식은 스페이스로 단어를 구분하는 영어, 한국어 등에 일반적입니다.

text-justify: inter-word가 적용된 혼합 문자 텍스트 - inter-character
-
자간 정렬은 인접한 조판 문자 단위 쌍 사이 간격을 조정합니다(실제로는 letter-spacing을 조정).
이 값은 일본어 등 동아시아 시스템에서 사용되는 경우가 있습니다.
text-justify: inter-character가 적용된 혼합 문자 텍스트 레거시 호환을 위해, UA는 distribute 키워드도 지원해야 하며, 이는 반드시 inter-character로 계산되어 완전히 동일한 의미와 동작을 가져야 합니다. UA는 이를 레거시 값 별칭으로 처리할 수 있습니다.
- ruby
-
자간 정렬은 auto와 동일하게 동작하지만 다음은 제외:
참고: 이 값은 루비 주석에 사용할 때 합리적인 기본 정렬을 제공합니다. [CSS-RUBY-1] 참고.
- no-compress
-
text-spacing-trim 또는 text-autospace로 제어되는 간격은 압축하지 않아야 합니다.
(이 값이 지정되지 않으면,
자간 정렬 과정에서 해당 간격을 줄일 수 있으며,
단 줄 시작/끝에 위치할 때는 줄이지 않습니다.)
참고: 압축 규칙의 예시는 일본어 [JLREQ] 3.8줄 조정에서 확인할 수 있습니다.
이 키워드는 원래 text-spacing의 일부였으나, 현재 이 위치에 있으므로 이름을 더 구체적으로 바꿔야 할 수도 있습니다. 예를 들어 U+0020 스페이스도 압축할 수 없음을 암시합니다. [Issue #7079]
최적 자간 정렬은 언어에 따라 달라지므로, 작성자는 최상의 결과를 위해 반드시 콘텐츠 언어 태그를 올바르게 달아야 합니다.
참고: 본 CSS 레벨의 지침은 완전한 자간 알고리즘을 설명하는 것이 아니라, 완전한 알고리즘이 갖춰야 할 최소 요구사항만 제시합니다. 요구사항을 제한함으로써 UA가 품질, 속도, 복잡성의 균형에 맞는 자간 알고리즘을 선택할 수 있도록 자율성을 줍니다.
7.5.1. 텍스트 펼침 및 압축
텍스트를 자간 정렬할 때, UA는 줄 내용 끝과 줄박스 엣지 사이 남은 공간을 줄 내용 전체에 분배해 줄박스를 정확히 채웁니다. UA는 음수 공간도 분배할 수 있으며, 이 경우 평소보다 더 많은 콘텐츠를 한 줄에 넣게 됩니다.
자간 조정 기회란, 자간 알고리즘이 텍스트 내 간격을 조정할 수 있는 지점을 뜻합니다. 자간 조정 기회는 단일 조판 문자 단위(예: 단어 구분자)로 제공될 수도 있고, 두 조판 문자 단위의 인접으로 제공될 수도 있습니다. 소프트 줄바꿈 기회 제어와 마찬가지로, 조판 문자 단위가 자간 조정 기회를 제공하는지 여부는 부모의 text-justify 값으로 제어됩니다; 마찬가지로, 두 연속 조판 문자 단위 사이에 자간 조정 기회가 존재하는지도 가장 가까운 공통 조상 요소의 text-justify 값으로 결정됩니다.
자간 정렬로 분배되는 공간은 letter-spacing 또는 word-spacing으로 정의된 간격에 추가로 적용됩니다. 이런 추가 공간이 단어 구분자 자간 조정 기회에 분배될 경우, word-spacing과 동일한 규칙을 따릅니다. 마찬가지로, 두 조판 문자 단위 사이 자간 조정 기회에 분배될 경우, letter-spacing과 동일한 규칙을 적용해야 합니다.
자간 알고리즘은 자간 조정 기회를 여러 우선순위 단계로 나눌 수 있습니다. 같은 단계에 속한 자간 조정 기회는 어떤 조판 문자 단위에서 생겼든 동일 우선순위로 늘이거나 줄입니다. 예를 들어, 한자 사이와 라틴 문자 사이 자간 조정 기회가 같은 단계라면 (inter-character 자간 스타일처럼) 출발 문자 단위가 달라도 동일하게 처리합니다. 이 레벨에서는 폰트 크기, letter-spacing, 글리프 형태, 줄 내 위치 등 추가 요인이 자간 조정 기회에 공간 분배에 영향을 주는지 정의하지 않습니다.
UA는 어떤 방식이든 텍스트 자간 정렬을 위해 선택적 합자 활성화/분리, 대체 글리프, 글리프 압축 등 폰트 기능을 활용할 수 있습니다. 이 동작은 이 CSS 레벨에서 제어하지 않습니다. 단, UA는 필수 합자를 분리하거나 복잡 문자 조형에 필요한 기능을 비활성화해서는 안 됩니다.
줄 내에 자간 조정 기회가 있고, 텍스트 정렬에서 해당 줄이 완전 자간 정렬(justify)로 지정되면, 반드시 자간 정렬해야 합니다.
7.5.2. 기호 및 문장부호 처리
자간 조정 기회를 결정할 때, 유니코드 기호(S*) 및 문장부호(P*) 클래스의 조판 문자 단위는 일반적으로 동일 문자 체계의 조판 글자 단위와 같이 취급됩니다 (또는 해당 문자의 script 속성이 Common이라면, 우세 문자 체계의 조판 글자 단위로 취급됨).
그러나 조판 전통에 따라 기호 및 문장부호 자간 정렬에는 추가 규칙이 있을 수 있습니다. 따라서 UA는 특정 문자를 다시 할당하거나 기호 및 문장부호가 포함된 자간 조정 기회에 대해 추가 우선순위 단계를 도입할 수 있습니다.
7.5.3. 늘릴 수 없는 텍스트
줄박스의 전체 너비로 인라인 콘텐츠를 늘릴 수 없을 경우, text-align-last 속성에 지정된 대로 정렬되어야 합니다. (text-align-last가 justify면 center로 정렬되어야 합니다.)
7.5.4. 필기체 문자체계
자간 정렬은 아랍어처럼 필기체 문자체계의 조판 글자 단위 사이에 간격을 추가하면 안 됩니다. UA가 가능하다면, 해당 조판 글자 단위 시퀀스 내 자간 조정 기회에 분배된 공간을 해당 시퀀스에 맞는 필기체 신장 형태로 변환해도 됩니다. 그렇지 않으면, 필기체 문자체계 내 조판 글자 단위 쌍 사이에는(연결되든 아니든) 자간 조정 기회가 없다고 간주해야 합니다.


일부 폰트 디자인에서는 자간 정렬을 위해 tatweel 문자를 사용할 수 있습니다. tatweel 기반 자간 정렬을 하는 UA는 해당 문자 사용 규칙을 올바르게 처리해야 합니다. tatweel 문자 올바른 삽입은 사용된 글자 조합, 단어 내 위치, 줄 내 단어 위치 등 맥락에 따라 달라짐을 주의하세요.
7.5.5. auto 자간 정렬의 최소 요건
auto 자간 정렬에 대해, 본 명세는 자간 조정 기회가 무엇인지, 어떻게 우선순위가 정해지는지, 여러 단계의 자간 조정 기회가 언제·어떻게 상호작용하는지 정의하지 않습니다. 다만, 다음을 요구합니다:
- 콘텐츠 언어의 조판 전통이나 인접 기호·문장부호에 의해 금지되지 않는 한, 아래 항목은 각각 자간 조정 기회가 되어야 합니다:
- 모든 블록 문자체계의 글자는 동일하게 취급되고, 모든 클러스터 문자체계의 글자도 동일하게 취급됩니다. 예를 들어, 한자 다음에 한자가 올 때와 한자 다음에 한글이 올 때의 자간 조정 기회는 구분하지 않습니다.
텍스트 자간 정렬에 대한 추가 정보는 “현행 표준: Full Justification 접근법”에 있으며, 문자체계 및 언어별로 색인화되어 있습니다. 해당 문서는 W3C 국제화 워킹 그룹이 관리합니다. [JUSTIFY]
7.6. 컨테이너 내 텍스트 블록 정렬: text-group-align 속성
| 이름: | text-group-align |
|---|---|
| 값: | none | start | end | left | right | center |
| 초기값: | none |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 아니오 |
| 백분율: | N/A |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 텍스트 정렬을 유지하면서 줄박스들을 그룹으로 맞춥니다.
그룹 정렬은 남은 공간이 가장 짧은 줄박스를 찾아 그만큼 한쪽 또는 양쪽에 패딩을 추가해 줄박스 전체 그룹의 공간을 맞추는 방식입니다; 그 후 텍스트 정렬을 해당 줄박스의 남은 공간 내에서 적용합니다. 동일 블록 포맷팅 컨텍스트 내 모든 자손 in-flow 줄박스를 그룹 정렬 대상에 포함하며, 독립 포맷팅 컨텍스트를 형성하는 자손의 내용은 건너뜁니다.
이 속성의 변형이 상속되어 각 블록 컨테이너별로 개별 적용되어, 해당 블록의 직접 자식 줄박스만 영향을 주게 할 수도 있습니다. 이는 실용성은 떨어지지만 구현은 쉽습니다.
동일 블록 컨테이너에서 발생한 float도 같은 크기만큼 이동시키면 레이아웃이 더 깔끔해집니다. 특히 CJK 레이아웃에서 더 가치가 있을 수 있습니다. 실제 동작 방식, 상위 요소에서 침입한 float과의 상호작용 등은 독자에게 남깁니다.
값의 의미는 다음과 같습니다:
- none
- 텍스트 정렬은 평소대로 동작하며 그룹 정렬은 적용되지 않습니다.
- start
- 인라인 콘텐츠를 그룹 정렬로 인라인 시작 측에 맞추며, 각 줄박스의 인라인 끝 측에 패딩을 추가합니다.
- end
- 인라인 콘텐츠를 그룹 정렬로 인라인 끝 측에 맞추며, 각 줄박스의 인라인 시작 측에 패딩을 추가합니다.
- left
- 인라인 콘텐츠를 그룹 정렬로 line-left 측에 맞추며, 각 줄박스의 line-right 측에 패딩을 추가합니다.
- right
- 인라인 콘텐츠를 그룹 정렬로 line-right 측에 맞추며, 각 줄박스의 line-left 측에 패딩을 추가합니다.
- center
- 인라인 콘텐츠를 그룹 정렬로 중앙에 맞추며, 각 줄박스 양쪽에 패딩을 반씩 추가합니다.
8. 공백 제어
CSS는 word-spacing, letter-spacing, line-padding 속성을 통해 일반 텍스트 간격을 제어할 수 있습니다. 각각 단어 구분자 주변, 조판 문자 단위 사이, 또는 줄 시작/끝에 추가 공간을 지정합니다. 또한 text-spacing-trim 속성을 통해 CJK 문장부호의 전각/반각을 맥락에 따라 제어할 수 있고, text-autospace 속성을 통해 문자 체계 변화나 문장부호 주변에 자동으로 추가 공간을 삽입할 수 있습니다.
8.1. 단어 간격: word-spacing 속성
| 이름: | word-spacing |
|---|---|
| 값: | normal | <length-percentage> |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 계산된 font-size 기준, 즉 1em |
| 계산된 값: | 절대 길이 및/또는 백분율 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 계산값 타입별 |
이 속성은 “단어” 사이에 추가 간격을 지정합니다. 값 해석은 아래와 같습니다:
- normal
- 추가 간격을 적용하지 않습니다. 계산값은 0입니다.
- <length-percentage>
-
폰트에서 정의한 고유 단어 간격에 추가로 간격을 지정합니다.
참고: 백분율은 그대로 상속되며, 현재 요소의 계산된 font-size 기준으로 해석됩니다 (즉, 적용되는 텍스트 크기에 상대적인 크기를 나타냄). em 단위는 상속된 요소의 계산된 font-size 기준으로 절대 길이로 해석되는 것과 다릅니다.
추가 간격은 단어 구분자에 적용되며, 공백 처리 규칙 적용 후 남은 텍스트가 대상입니다. 조판 전통에 따라 달라지지 않는 한, 해당 문자 양쪽에 반씩 적용해야 합니다. 값은 음수일 수 있으나, 구현별 한계가 있을 수 있습니다.
단어 구분자 문자는 조판 문자 단위 중 주된 목적과 일반적 용도가 단어 구분인 문자입니다. 유니코드에서는 (전체 목록은 아니나) 스페이스(U+0020), 줄바꿈 없는 스페이스(U+00A0), 에티오피아 단어 공백(U+1361), 에게 단어 구분자(U+10100, U+10101), 우가릿 단어 구분자(U+1039F), 페니키아 단어 구분자(U+1091F) 등이 포함됩니다. [UNICODE]
참고: 일반 문장부호나 고정폭 스페이스(U+3000, U+2000~U+200A 등)는 단어 구분자 문자가 아닙니다. 실제로 단어 사이에 자주 나타나더라도, 주된 목적이 단어 구분이 아니기 때문입니다.
만약 단어 구분자 문자가 없거나, 단어 구분 문자에 진행폭이 0(예: U+200B 제로폭 스페이스)일 경우, UA는 단어 사이에 추가 간격을 만들면 안 됩니다.
8.2. 장평: letter-spacing 속성
| 이름: | letter-spacing |
|---|---|
| 값: | normal | <length-percentage> |
| 초기값: | normal |
| 적용 대상: | 인라인 박스 및 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 계산된 font-size 기준, 즉 1em |
| 계산된 값: | 절대 길이 및/또는 백분율 |
| 정규 순서: | 해당 없음 |
| 애니메이션 타입: | 계산값 타입별 |
이 속성은 인접 조판 문자 단위 사이의 추가 간격(일반적으로 장평)을 지정합니다. letter-spacing은 양방향 재정렬 이후에 적용되며, 커닝 및 word-spacing에 추가로 적용됩니다. [CSS-WRITING-MODES-4] [CSS-FONTS-3] 자간 규칙에 따라 UA는 조판 문자 단위 사이의 간격을 자간 정렬을 위해 추가로 늘리거나 줄일 수 있습니다.
각 값의 의미는 다음과 같습니다:
- normal
- 추가 간격을 적용하지 않습니다. 계산값은 0입니다.
- <length-percentage>
-
조판
문자 단위 사이에 추가 간격을 지정합니다.
값은 음수일 수 있지만, 구현별 한계가 있을 수 있습니다.
참고: 백분율은 그대로 상속되며, 현재 요소의 계산된 font-size 기준으로 해석됩니다 (즉, 적용되는 텍스트 크기에 상대적인 크기를 나타냄). em 단위는 상속된 요소의 계산된 font-size 기준으로 절대 길이로 해석되는 것과 다릅니다.
레거시 이유로,
계산된 letter-spacing이 0이면
resolved value (getComputedStyle()
반환값)은 normal이 됩니다.
letter-spacing에서는, 연속 원자 인라인(예: 이미지, 인라인 블록)은 하나의 조판 문자 단위로 취급합니다.
letter-spacing은 줄 시작에서는 적용하지 않아야 하며, 줄 끝에서 적용 여부는 현행 표준에서 정의하지 않습니다.
p{ letter-spacing : 1 em ; }
< p > abc</ p >
a b c
a b c
따라서 UA는 [RFC6919] 줄 끝에 letter-spacing을 추가하지 않는 것이 정말 좋아야 합니다:
a b c
두 조판 문자 단위 사이의 letter-spacing은 해당 두 조판 문자 단위를 포함하는 가장 안쪽 요소에 “귀속”됩니다: 인접 조판 문자 단위 사이의 총 letter-spacing(양방향 재정렬 이후)은 그 경계를 포함하는 가장 안쪽 요소에서 지정되고 렌더링됩니다. UA는 대신 요소 경계에서 letter-spacing을 해당 요소의 값을 사용해 한쪽 문자 단위에 귀속시킬 수도 있습니다.
참고: 이 보조 동작은 웹 호환성 때문에 허용됩니다.
p{ letter-spacing : 1 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
a b b c
따라서 letter-spacing 값은 해당 요소 내에 완전히 포함된 문자 사이에만 영향을 주어야 합니다:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > bb</ span > c</ p >
a b b c
따라서 letter-spacing를 한 글자만 포함하는 요소에 적용해도 렌더링 결과에는 영향이 없습니다:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
< p > a< span > b</ span > c</ p >
a b c
letter-spacing은 RTL 재정렬 후 삽입되므로, 아래 내부 span에 적용한 letter-spacing도 결과에 영향이 없습니다. 재정렬 후 "c"가 "א" 옆에 오지 않기 때문입니다:
p{ letter-spacing : 1 em ; } span{ letter-spacing : 2 em ; }
<!-- abc 다음에 히브리어 알레프(א), 베트(ב), 기멜(ג) --> <!-- 재정렬 후 이들이 역순으로 표시됨 --> < p > ab< span > cא</ span > בג</ p >
a b c א ב ג
letter-spacing은 눈에 보이지 않는 제로폭 포맷팅 문자(유니코드 Cf 범주 등)를 무시합니다. 이런 문자가 문서에 존재하지 않는 것처럼 간격을 추가해야 합니다.
두 문자 사이의 유효 간격(letter-spacing, 자간 정렬 등)이 0이 아니면, UA는 필수적이지 않은(기본 글리프 조형에 필요하지 않은) 선택적 합자를 적용하지 않아야 합니다. 단, font-feature-settings로 지정된 폰트 기능은 이 규칙보다 우선합니다. 자세한 내용은 CSS Fonts Module Level 3 § feature-precedence 참고.
참고: OpenType에서는 필수 합자가 rlig 기능에 연결되는 것이
기대됩니다.
나머지 합자는 모두 선택적입니다.
단, UA 또는 플랫폼 휴리스틱이 깨진 폰트 처리를 위해 추가 합자를 적용하는 경우도 있는데,
이 명세는 그런 예외 처리까지 정의하거나 덮어쓰지 않습니다.
8.2.1. 필기체 문자체계
UA가 가능하다면, 필기체 문자체계에 letter-spacing을 적용할 때, 전체 추가 간격을 해당 문자 시퀀스에 맞는 필기체 신장(또는 음수 tracking 값의 경우 압축) 형태로 변환해 시퀀스 전체가 동일하게 늘어나거나 줄어들도록 할 수도 있습니다. 그렇지 않고 UA가 필기체 문자체계 텍스트를 필기체 연결을 깨지 않고 늘릴 수 없다면, 해당 문자체계의 조판 글자 단위 쌍 사이에는 간격을 적용하면 안 되며 (letter-spacing에서 각 단어를 하나의 조판 글자 단위로 간주). 두 경우 모두 해당 문자 사이의 실제 간격은 0이 되지만, 전자는 텍스트가 늘어진 느낌을 유지합니다.
| — | 원본 텍스트 | |
| BAD | 각 글자 사이에 간격을 고르게 분배. 필기체 연결이 깨집니다! | |
|---|---|---|
| OK | ∑letter-spacing을 조판적으로 적합한 필기체 신장으로 분배. 결과 텍스트 길이는 위 evenly-spaced 예시와 동일합니다. | |
| OK | 아랍어 글자 사이 letter-spacing 억제. letter-spacing이 아랍어가 아닌 문자(예: 스페이스)에는 정상적으로 적용됩니다. | |
| BAD | 연결되지 않은 글자 사이에만 letter-spacing 적용. 조판 색상이 깨지고 단어 경계가 모호해집니다. |
참고: 텍스트의 올바른 필기체 신장/압축은 문자체계, 글꼴, 언어, 단어 내 위치, 줄 내 위치, 구현 복잡도, 폰트 기능, 서법 취향 등에 따라 달라질 수 있으며, 어떤 경우에는 불가능할 수도 있습니다. 단축 합자, 스와시 변형, 맥락형, U+0640 ـ ARABIC TATWEEL 등 신장 글리프, 기타 마이크로타이포그래피가 필요할 수 있습니다. 이런 효과에 대한 규칙 정의는 CSS의 범위 밖입니다. 작성자는 letter-spacing을 필기체 문자체계에 적용할 때 상호운용성 없는 결과를 받아들일 준비가 되어 있지 않으면 피해 주세요.
8.3. 줄 시작/끝 패딩: line-padding 속성
| 이름: | line-padding |
|---|---|
| 값: | <length> |
| 초기값: | 0 |
| 적용 대상: | 인라인 박스 |
| 상속 여부: | 예 |
| 백분율: | N/A |
| 계산된 값: | 절대 길이 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 계산값 타입별 |
letter-spacing이 조판 문자 단위 사이 간격을 조정하며 줄 시작/끝에는 적용되지 않는 반면, 이 속성은 줄 시작/끝에만 간격을 조정합니다. 추가 간격은 줄 시작/끝에 위치한 가장 안쪽 인라인 박스에만 적용되며, 해당 인라인 박스의 내용 엣지와 인접 인라인 레벨 콘텐츠 (텍스트 또는 원자 인라인) 사이에 삽입됩니다. 이 추가 공간은 자간 조정 기회가 아닙니다.
p { line-padding: 0.5em; line-height: 1; text-align: center }
span { background: black; color: white; }
em { background: green; color: white; }
<p><span>Here is <em>some text</em></span>
line-padding이 적용되면, 각 줄 양쪽에 0.5em 만큼 인라인 배경이 추가로 보이게 됩니다. 만약 “some”과 “text” 사이에서 줄이 나뉘면, 첫 줄의 왼쪽은 검정, 오른쪽은 초록, 두 번째 줄 양쪽은 초록으로 패딩이 들어갑니다.
Here is some
text
8.4. 자동 맥락적 간격: text-autospace 속성
| 이름: | text-autospace |
|---|---|
| 값: | normal | <autospace> | auto |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | N/A |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 같은 줄, 같은 인라인 포맷팅 컨텍스트 내 인접 문자 사이 간격을 문자 클래스 기반 규칙 집합으로 제어하며, 문자 체계 변화 및 문장부호 주변 간격을 자동으로 제어할 수 있습니다.
값 정의는 다음과 같습니다:
<autospace> = no-autospace |
[ ideograph-alpha || ideograph-numeric || punctuation ]
|| [ insert | replace ]
- normal
- ideograph-alpha ideograph-numeric와 동일 동작.
- no-autospace
- 자동 간격 삽입 안 함.
- insert
-
이미 어떤 종류의 스페이스(Unicode general category
Z)가 없을 때만 지정 간격을 자동 삽입. - replace
-
이미 스페이스(U+0020)가 있어도 지정 간격을 자동 삽입하며,
스페이스(U+0020)는 제거함.
다른 종류의 스페이스(Unicode general category
Z)는 insert와 같이 자동 간격을 억제함.참고: 이 값은 제대로 된 간격 대신 입력이 쉬운 U+0020을 사용한 경우 교정을 위해 사용함.
- ideograph-alpha
- 한자와 비한자 문자 시퀀스 사이에 추가 간격 생성. § 8.4.1 문자체계 간 간격 참조.
- ideograph-numeric
- 한자와 비한자 숫자 시퀀스 사이에 추가 간격 생성. § 8.4.1 문자체계 간 간격 참조.
- punctuation
-
언어별 조판 관례상 필요한 경우 문장부호 주변에 추가 비분리 간격 생성.
현행 표준에서는 요소의 콘텐츠 언어가 프랑스어일 때, 프랑스 조판 가이드라인에 따라 좁은 줄바꿈 없는 스페이스(U+202F) 및 줄바꿈 없는 스페이스(U+00A0)를 삽입. 그 외에는 효과 없음. 앞으로 다른 언어에 대한 자동 간격 동작이 추가될 수도 있음.
- auto
-
UA가 조판 품질이 높은 간격 값을 선택.
플랫폼별로 값이 다를 수 있음.
참고: 이 간격 값은 OS 플랫폼 관례와 일치할 수도, 아닐 수도 있음.
이 속성은 word-spacing 및 letter-spacing과 합산 적용됨. 즉, letter-spacing 값(있다면)이 text-autospace 생성 간격에 더해짐. word-spacing도 동일.
요소 경계에서는, 문자 사이 추가 간격은 해당 경계를 포함하는 가장 안쪽 요소에서 결정되고 렌더링됨.
8.4.1. 문자체계 간 간격
ideograph-alpha 및 ideograph-numeric 값은 특정 문자 클래스가 직접 인접할 때(즉, 중간에 0이 아닌 margin, border, padding 또는 다른 문자(예: 따옴표, 스페이스)가 없을 때) 경계에서 간격을 삽입합니다. 이 키워드로 삽입되는 간격 크기는 CJK 어드밴스 측정의 1/8, 즉 0.125ic입니다.
참고: 간격 관례는 다양하지만, 보통 1/4ic에서 1/8ic까지이며, 1/4ic는 금속활자 제한으로 과거에 흔했고, 현대 비례 조판에서는 1/6ic 이하가 더 흔함. 이 간격은 기본값(normal)으로 기본적으로 삽입되므로, CSS는 간섭을 최소화하기 위해 1/8ic를 사용함. 앞으로 이 모듈의 후속 레벨에서 간격 크기 제어가 추가될 수 있음.
8.5. CJK 문장부호 간격: text-spacing-trim 속성
| 이름: | text-spacing-trim |
|---|---|
| 값: | <spacing-trim> | auto |
| 초기값: | normal |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | N/A |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 같은 줄, 같은 인라인 포맷팅 컨텍스트 내에서 CJK 문장부호 문자 주변 간격을 문자 클래스 기반 규칙으로 제어하며, 위치와 인접 문자를 바탕으로 반각 또는 전각으로 설정할 수 있게 해줍니다.
값 정의는 다음과 같습니다:
<spacing-trim> = space-all | normal | space-first | trim-start | trim-both | trim-all
- space-all
- 모든 전각 문장부호 문자를 전각 글리프로(간격 있음) 설정합니다.
- normal
- 각 줄 시작의 전각 여는 문장부호는 전각 글리프(간격 있음)로, 각 줄 끝의 전각 닫는 문장부호는 반각 글리프(끝에 붙음)로 설정합니다. 단, 자간 정렬 전 들어갈 수 없는 경우는 전각 글리프로 설정합니다. 그리고 문장부호 글리프 간의 간격은 아래 설명처럼 병합합니다.
- trim-both
- 각 줄 시작의 전각 여는 문장부호와 줄 끝의 전각 닫는 문장부호를 반각 글리프(끝에 붙음)로 설정합니다. 그리고 문장부호 글리프 간의 간격은 아래 설명처럼 병합합니다.
- space-first
-
전각 여는 문장부호를 블록 컨테이너의 첫 줄 및 강제 줄바꿈 이후 각 줄에서 전각 글리프(간격
있음)로 설정합니다.
그 외는 normal과 동일합니다.
이 값은 호환성 요구를 위해 존재합니다.
이 값은 기존 중국어 및 일본어 콘텐츠의 서식 관리를 위해 존재합니다. trim-both가 조판적으로 더 적합했지만, 실제로는 첫 줄이 space-all처럼 설정되는 걸 기대하는 콘텐츠가 많기 때문입니다.
특히, 여러 UA에서 hanging-punctuation 지원이 부족하여, 기존 콘텐츠(특히 ePub)는 text-indent 대신 U+3000 한자 공백을 사용하고, 문단이 문장부호로 시작해 들여쓰기가 매달림되어야 할 경우에는 이를 생략하는 방식으로 매달림 효과를 만듭니다. trim-both를 첫 줄에 적용하면 이런 콘텐츠의 들여쓰기가 잘려 실제 첫 줄 구분을 가릴 수 있습니다.
이렇게 한자 공백을 들여쓰기용으로 사용하는 조판 관행은 HTML/CSS가 제공하는 콘텐츠와 스타일 분리와는 반대입니다. hanging-punctuation과 text-indent로 문단 서식을 제어하면 문서 소스의 의미를 온전히 보존하고, 스타일 시트 설계자는 콘텐츠 수정 없이 다양한 간격/들여쓰기 스타일을 자유롭게 바꿀 수 있습니다. 예시는 § 8.5.3 CSS의 일본어 문단 시작 관행에서 확인하세요.
또한 줄 끝에서의 동작은 normal 및 trim-start와 맞추었으며, trim-both와는 다릅니다. 즉, 자간 정렬 전에 들어갈 수 없을 때만 글리프를 잘라냅니다. 더 적은 경우에 조판 품질이 개선되지만, space-all의 레거시 동작과 더 가까워 호환성 문제가 적습니다.
- trim-start
- 각 줄 시작의 전각 여는 문장부호를 반각 글리프(끝에 붙음)로 설정. 그 외는 normal과 동일.
- trim-all
- 전각 여는 문장부호, 전각 닫는 문장부호, 전각 중점 문장부호를 모두 반각 글리프로 설정하며, 줄 내 위치나 인접 문자와 관계없이 적용합니다.
- auto
-
UA가 조판 품질이 높은 간격 값을 선택.
플랫폼별로 값이 다를 수 있음.
참고: 이 간격 값은 OS 플랫폼 관례와 일치할 수도, 아닐 수도 있음.
auto 값이 필요한가요? 첫 줄 시작에서 플랫폼별 동작을 선택하는 건 이상하며, 그 외에는 trim-both를 쓰는 게 더 적합할 듯합니다.
| 값 | 줄 시작 잘림 | 줄 끝 잘림 | 인접 쌍 잘림 | 전체 잘림 |
|---|---|---|---|---|
| space-all | 아님 | |||
| normal | 아님 | 자간 정렬 전에 들어갈 수 없을 때만 | 예 | 아님 |
| space-first | 첫 줄 제외 예 | |||
| trim-start | 예 | |||
| trim-both | 예 | |||
| trim-all | 예 | |||
| auto | UA/플랫폼 의존 | |||
8.5.1. 전각 문장부호 병합
일반적으로 전각 문자는 표준 한자(예: 水 U+6C34)와 동일한 어드밴스 폭을 가집니다. 하지만 많은 전각 문장부호 글리프는 전각 디자인 공간의 일부만 차지합니다. 따라서 이런 문장부호는 항상 전각으로 설정되지 않습니다. text-spacing-trim의 여러 값으로 저자는 이런 문자를 언제 반각(일반적으로 한자 폭의 절반)으로, 언제 전각으로 설정할지 제어할 수 있습니다.
텍스트를 지정대로 설정하려면 UA는 다음 중 하나를 수행해야 합니다.
- 글리프가 전각일 때 반각으로 설정해야 하면 빈 부분을 잘라내기(커닝) 또는
- 글리프가 반각일 때 전각으로 설정해야 하면 공간 추가
UA는 폰트가 기능을 구현할 경우,
OpenType halt 및 vhal 기능을 활용해
필요한 글리프 커닝을 할 수도 있습니다.
UA는 hwid 기능이나 기타 반각 형태 대체는 사용하면 안 됩니다;
반각 글리프로 바꾸면 글리프 형태 자체가 변할 수 있는데, 이 경우는 허용되지 않습니다.
일부 폰트는 전각 문장부호 문자를 비례 글리프로 만듭니다. 폰트가 전각/반각 글리프 형태 구분을 지원하지 않으면(예: 폰트 기능으로), 이런 비례 글리프는 지정 어드밴스 폭을 전각이자 반각으로 동시에 간주해야 하며, UA는 이런 글리프에 공간을 추가/제거하면 안 됩니다.
참고: 표준 한자 어드밴스 폭은
폰트 메트릭(예: OpenType ideo, idtp 베이스라인) 또는 水 U+6C34의 어드밴스 폭으로 결정할 수 있습니다.
(일부 폰트는 압축되어 정사각형이 아니므로 반대 쓰기 모드를 사용해야 함.)
OpenType 메트릭에 대한 추가 정보는 OpenType
스펙에서 확인하세요.
만약 水 U+6C34, 卜 U+535C, 一 U+4E00의 어드밴스 폭이 모두 다르면,
해당 폰트는 비례 한자를 사용하며,
전각 어드밴스 폭을 글리프 측정만으로 신뢰할 수 없습니다.
일부 폰트는 전각 문장부호 글리프의 빈 공간이 너무 작아 커닝이 불가능합니다. UA는 글리프 바운딩 박스, 글리프 메트릭, 폰트 기능 등을 참고해 커닝 시 글리프 잘림, 충돌, 과도한 커닝이 발생할 수 있다고 판단되면 커닝을 하지 않을 수 있습니다.
text-spacing-trim이 trim-all인 경우, UA는 해당 전각 글리프에 일반적으로 포함된 공간을 맥락과 관계없이 반드시 병합해야 합니다. 그 외에는 text-spacing-trim이 space-all이 아닌 한(또는 폰트가 비례 전각 문장부호 글리프인 경우), UA는 줄 내 인접하게 배치된 경우 아래처럼 해당 공간을 병합해야 합니다:
-
전각 여는 문장부호는 이전 문자가 다음 중 하나일 때 반각으로 설정:
-
한자 공백(U+3000)
-
동일하거나 더 큰 font-size의 전각 닫는 문장부호
-
유니코드 일반 범주
Ps문자
그 외에는 전각으로 설정.
-
전각 닫는 문장부호는 다음 문자가 다음 중 하나일 때 반각으로 설정:
-
한자 공백(U+3000)
-
더 큰 font-size의 전각 여는 문장부호
-
유니코드 일반 범주
Pe문자
그 외에는 전각으로 설정.
| 조합 | 샘플 쌍 | 표시 예시 |
|---|---|---|
| 여는—여는 | 〔+( | 〔( |
| 중점—여는 | ・+( | ・( |
| 닫는—여는 | 〕+( | 〕( |
| 한자공백—여는 | +( | ( |
| 닫는—닫는 | )+〕 | )〕 |
| 닫는—중점 | )+・ | )・ |
| 닫는—한자공백 | )+ | ) |
8.5.2. 텍스트 간격 문자 클래스
이 속성의 맥락에서 다음 정의가 적용됩니다:
클래스 및 유니코드 코드포인트는 검토 중이며, 최근 유니코드 추가 사항을 수용하기 위해 일부 변경이 필요합니다. [Issue #9503]
- 한자 문자
-
아래에 나열된 기본 문자를 가지는 모든 조판 문자 단위 [CSS-TEXT-3]를 포함합니다:
- U+3041~U+30FF 범위의 모든 문자, 단 유니코드 문장부호 [P*] 일반 범주에 속하는 것은 제외.
- CJK 획 (U+31C0~U+31EF).
- 가타카나 음운 확장(U+31F0~U+31FF).
- Han script property를 가진 모든 문자.
- 비한자 문자
-
유니코드 문자 [L*] 및 기호 [M*] 일반 범주에 속하는 모든 조판 문자 단위를 포함합니다.
다음 조건 중 하나에 해당하면 제외:
- 한자 문자로 정의된 경우
- [UAX11]에서 동아시아 전각(F)으로 분류된 경우
- text-orientation 속성 또는 text-combine-upright 속성을 사용해 세로 텍스트 플로우에서 직립하는 경우
- 비한자 숫자
-
유니코드 십진수 숫자 [Nd] 일반 범주에 속하는 모든 조판 문자 단위를 포함합니다.
다음 조건 중 하나에 해당하면 제외:
- [UAX11]에서 동아시아 전각(F)으로 분류된 경우
- text-orientation 속성 또는 text-combine-upright 속성을 사용해 세로 텍스트 플로우에서 직립하는 경우
- 전각 여는 문장부호
- CJK 기호 및 문장부호 블록(U+3000~U+303F)에 속하거나 [UAX11]에서 동아시아 전각(F)으로 분류된 모든 여는 문장부호(유니코드 범주
Ps)를 포함. 또한 LEFT SINGLE QUOTATION MARK(U+2018), LEFT DOUBLE QUOTATION MARK(U+201C)도 포함. 트리밍 시 왼쪽(가로 텍스트) 또는 위쪽(세로 텍스트) 절반을 커닝. - 전각 닫는 문장부호
- CJK 기호 및 문장부호 블록(U+3000~U+303F)에 속하거나 [UAX11]에서 동아시아 전각(F)으로 분류된 모든 닫는 문장부호(유니코드 범주
Pe)를 포함. 또한 RIGHT SINGLE QUOTATION MARK(U+2019), RIGHT DOUBLE QUOTATION MARK(U+201D)도 포함. 전각 콜론 문장부호 및/또는 전각 점 문장부호(아래 참고)도 포함될 수 있음. 트리밍 시 오른쪽(가로 텍스트) 또는 아래쪽(세로 텍스트) 절반을 커닝. - 전각 중점 문장부호
- MIDDLE DOT(U+00B7), HYPHENATION POINT(U+2027), KATAKANA MIDDLE DOT(U+30FB)를 포함. 전각 콜론 문장부호 및/또는 전각 점 문장부호(아래 참고)도 포함될 수 있음.
- 전각 콜론 문장부호
- FULLWIDTH COLON(U+FF1A), FULLWIDTH SEMICOLON(U+FF1B) 포함.
- 전각 점 문장부호
- IDEOGRAPHIC COMMA(U+3001), IDEOGRAPHIC FULL STOP(U+3002), FULLWIDTH COMMA(U+FF0C), FULLWIDTH FULL STOP(U+FF0E) 포함.
전각 콜론 문장부호와 전각 점 문장부호를 전각 닫는 문장부호 또는 전각 중점 문장부호로 간주할지는 글리프 박스 내에서 문장부호가 그려진 위치에 따라 다릅니다. 문장부호가 가운데에 그려지면 중점 문장부호로 간주해야 하고, 한쪽(가로 텍스트의 경우 왼쪽, 세로 텍스트의 경우 위쪽)에 그려지고 나머지 절반이 비어 있으면 닫는 문장부호로 간주해 트리밍해야 합니다.
UA는 전각 콜론 문장부호와 전각 점 문장부호를 전각 닫는 문장부호 또는 전각 중점 문장부호 카테고리 중 하나로 분류해야 합니다. UA는 언어 관례와 쓰기 모드(가로/세로), 폰트 정보 등을 참고해 이 분류를 결정할 수 있습니다. 또한 필요에 따라 각 카테고리에 추가 문자도 할당할 수 있습니다.
| 콜론 문장부호 | 점 문장부호 | |
|---|---|---|
| 중국어 간체(가로) | 닫는 문장부호 | 닫는 문장부호 |
| 중국어 간체(세로) | 닫는 문장부호 | 닫는 문장부호 |
| 중국어 번체 | 중점 문장부호 | 중점 문장부호 |
| 한국어 | 중점 문장부호 | 닫는 문장부호 |
| 일본어 | 중점 문장부호 | 닫는 문장부호 |
중국어 폰트의 경우, 실제로는 표준 관례가 잘 지켜지지 않는 경우가 많다는 점에 유의하세요.
8.5.3. CSS에서 일본어 문단 시작 관행
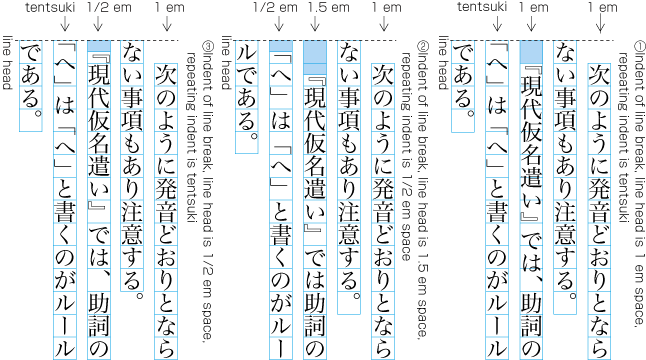
줄 시작에서 여는 괄호 배치 [JLREQ]
UA 스타일시트가 p { margin: 1em 0; }인 경우,
CSS로 일본어 조판 스타일을 아래 규칙으로 구현할 수 있습니다:
-
괄호를 들여쓰기와 줄 시작에 붙여 정렬(첫 번째 방식):
p { /* Flush alignment */ margin: 0; text-indent: 1em; text-spacing-trim: trim-both; } -
모든 줄에서 괄호에 전각 간격 유지(두 번째 방식):
p { /* Fullwidth alignment */ margin: 0; text-indent: 1em; text-spacing-trim: space-all; } -
괄호를 들여쓰기 내에 매달고 나머지 줄에는 붙여 정렬(세 번째 방식):
p { /* Hanging alignment */ margin: 0; text-indent: 1em; text-spacing-trim: trim-both; hanging-punctuation: first; }
8.6. 문자 클래스 간격 단축 속성: text-spacing 속성
| 이름: | text-spacing |
|---|---|
| 값: | none | auto | <spacing-trim> || <autospace> |
| 초기값: | 각 개별 속성 참조 |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | N/A |
| 계산된 값: | 지정된 키워드 |
| 애니메이션 타입: | 불연속 |
| 정규 순서: | 문법 기준 |
이 속성은 text-spacing-trim과 text-autospace를 한 번에 지정하는 단축 속성입니다. 값 정의는 다음과 같습니다:
- none
- 모든 text-spacing 기능을 끕니다: text-spacing-trim을 space-all로, text-autospace를 no-autospace로 설정.
- auto
- text-spacing-trim과 text-autospace를 모두 auto로 설정.
- <spacing-trim>
- text-spacing-trim을 지정한 값으로 설정. <autospace> 값을 지정하지 않으면, text-autospace는 초기값으로 설정.
- <autospace>
- text-autospace를 지정한 값으로 설정. <spacing-trim> 값을 지정하지 않으면, text-spacing-trim는 초기값으로 설정.
참고: normal이 text-spacing-trim과 text-autospace의 초기값이므로, text-spacing: normal은 둘 다 초기값으로 리셋합니다.
8.7. 요소 경계 너머 조형
다음 조건 중 하나라도 해당하는 경우, 텍스트 조형은 인라인 박스 경계에서 끊어져야 합니다 (경계가 두 조판 문자 단위 사이에 있을 때):
- margin/border/padding 중 하나라도 인라인 축에서 두 조판 문자 단위를 분리하는 값이 0이 아님.
- vertical-align이 baseline이 아님.
- 경계가 bidi isolation 경계임.
포맷팅 변화가 실질적으로 없거나, 글리프에 영향이 없는 변화만 있을 경우(텍스트 장식 적용 등), 텍스트 조형은 인라인 박스 경계에서 끊기면 안 됩니다.
그 외의 경우에도, 폰트 기술의 한계 내에서 합리적이고 가능한 경우라면, 텍스트 조형은 인라인 박스 경계에서 끊기지 않는 것이 좋습니다.
경계 너머 조형이 가능하지만 합리적이지 않은 예시는 폰트가 좌우 20글자 문맥에 따라 글리프를 선택하는 경우: 해당 문자열 앞뒤의 모든 텍스트를 여러 인라인 경계와 포맷팅 변경을 지나서 전달하는 건 복잡합니다. UA는 이런 경우를 처리할 수도 있지만, 필수는 아닙니다. 현대 문자 체계에서는 일반적이거나 근본적으로 필요한 경우가 아니기 때문입니다.
경계 너머 조형이 불가능한 예시는 "and"라는 단어 중간에 폰트 두께가 바뀌는 경우, 해당 폰트에서 "and" 세 글자를 모두 합자로 바꿔 ampersand 글리프("&")로 표시한다면 경계에서 합자를 만들 수 없습니다.
9. 엣지 효과
엣지 효과는 블록 내 줄들의 들여쓰기를 제어(text-indent) 하거나, 줄 시작/끝 엣지에서 콘텐츠의 측정 방식을 제어(hanging-punctuation)합니다.
9.1. 첫 줄 들여쓰기: text-indent 속성
| 이름: | text-indent |
|---|---|
| 값: | [ <length-percentage> ] && hanging? && each-line? |
| 초기값: | 0 |
| 적용 대상: | 블록 컨테이너 |
| 상속 여부: | 예 |
| 백분율: | 블록 컨테이너의 인라인 축 내부 크기 기준 |
| 계산된 값: | 계산된 <length-percentage> 값 + 지정 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 계산값 타입별 |
이 속성은 블록 내 인라인 콘텐츠 줄에 적용되는 들여쓰기를 지정합니다. 들여쓰기는 줄박스의 start 엣지에 적용되는 margin으로 처리됩니다.
each-line 및/또는 hanging 키워드로 별도 지정하지 않으면, 요소의 첫 형식화 줄만 영향을 받습니다. [CSS-PSEUDO-4] 예를 들어, 익명 블록 박스의 첫 줄은 부모 요소의 첫 자식인 경우에만 영향을 받습니다.
각 값의 의미는 다음과 같습니다:
- <length>
- 들여쓰기 크기를 절대 길이로 지정.
- <percentage>
-
들여쓰기 크기를
블록 컨테이너의 논리적 너비의 백분율로 지정.
백분율은 0으로 처리되어 내재 크기 기여 계산에는 포함되지 않지만, 실제 레이아웃에서는 정상적으로 해석됩니다.
참고: 이로 인해 요소가 오버플로우될 수 있습니다. 백분율 들여쓰기와 내재 크기 계산을 함께 쓰는 것은 권장되지 않습니다.
- each-line
- 들여쓰기가 각 블록 컨테이너의 첫 줄 및 강제 줄바꿈 이후 각 줄에 적용(소프트 줄바꿈 이후 줄은 제외).
- hanging
- 영향을 받는 줄을 반전시킴.
text-align이 start이고, text-indent가 left-to-right 텍스트에서 5em이고 float이 없다면, 첫 줄 텍스트는 블록에서 5em 들여쓰기 후 시작됩니다:
CSS1부터 블록 요소의 첫 줄을 'text-indent' 속성을 '5em'으로 주면 5em 들여쓰기가 가능합니다.
hanging 키워드를 추가하면, 첫 줄은 들여쓰기 없이 시작하고, 나머지 줄이 5em 들여쓰기 됩니다:
CSS3에서는 'hanging 5em'으로 설정하면 블록 요소의 나머지 줄을 5em 들여쓰기 할 수 있습니다.
예를 들어, 문단 중간에
수식이 들어가서 가운데 정렬된 경우,
x + y = z
수식 이후 첫 줄은 들여쓰기 없이 시작됩니다
(새 문단 시작처럼 보이지 않게 하기 위해).
하지만 시나 코드처럼 줄이 길어 줄바꿈되는 모든 줄을 들여쓰기하는 게 적절한 경우도 있습니다. 아래 예시에서 text-indent를 3em hanging each-line으로 설정하면, 시의 세 번째 줄이 블록의 오른쪽 경계에서 소프트 줄바꿈될 때 hanging 들여쓰기가 적용됩니다:
짧은 줄에는 줄바꿈이 필요 없지만 줄이 길어지면 들여쓰기가 필요할 때도 있습니다. 때론 소프트 줄바꿈이 페이지에 맞추는 데 도움이 됩니다.
참고: text-indent 속성은 상속되므로, 블록 요소에 지정하면 자식 인라인 블록 요소에도 영향을 줄 수 있습니다. 그래서 보통 text-indent: 0을 display: inline-block 요소에 따로 지정하는 것이 좋습니다.
9.2. 행잉 글리프
줄 시작 또는 끝 엣지에 있는 글리프가 행잉(hang)될 때, 줄 내용의 적합성, 정렬, 자간 정렬 측정 대상에서 제외됩니다. 줄의 정렬/자간 정렬 방식에 따라 마크가 줄박스 바깥에 배치될 수 있습니다. 행잉 글리프는 내재 크기(min-content 크기, max-content 크기) 및 관련 크기 계산에도 포함되지 않습니다. (이 측정과 커닝의 상호작용은 현재 UA 정의이며, CSSWG는 이에 대한 조언을 환영합니다.)
행잉 글리프는 여전히 부모 인라인 박스 내부에 포함되며, 여전히 텍스트 자간 정렬에는 참여합니다: 해당 문자 어드밴스는 줄에 들어갈 콘텐츠 양, 자간 정렬을 위한 확장·압축량, 줄박스 내 콘텐츠 위치 결정에는 포함되지 않을 뿐입니다. 실질적으로 행잉 글리프의 문자 어드밴스는 부모 인라인 박스의 해당 엣지에 추가 음수 마진으로 재해석됩니다; 줄 레이아웃은 그 외에는 평소대로 동작합니다. 넘치는 행잉 글리프는 일반적으로 잉크 오버플로우로 처리해 불필요한 스크롤바 생성을 방지해야 하지만, UA는 콘텐츠가 편집 가능하거나 사용자가 스크롤 오버플로우가 유용한 경우에 스크롤 오버플로우로 처리할 수 있습니다. [CSS-OVERFLOW-3]
일부 경우 줄 끝에 있는 글리프는 조건부 행잉될 수 있습니다: 자간 정렬 전 줄에 들어가지 않을 때만 행잉됩니다. 줄 내용의 적합성 측정에는 포함되지 않으며, 들어가지 않는 부분만 행잉으로 처리됩니다. 조건부 행잉 글리프는 min-content 크기 및 관련 크기 계산에는 포함되지 않지만, max-content 크기에는 포함됩니다.
행잉 가능한 글리프와 줄 엣지 사이에 0이 아닌 인라인 축 border 또는 padding이 있으면 해당 글리프는 행잉되지 않습니다. 예를 들어, 인라인 박스 끝에 padding이 있는 경우 그 끝의 점은 행잉되지 않습니다.
여러 인접 글리프가 함께 행잉될 수 있지만, 행잉 허용 개수에 대한 구체적 제한(예: 각 줄 엣지에 최대 1개 문장부호만 행잉 가능)이 있을 수 있습니다.
9.2.1. 행잉 문장부호: hanging-punctuation 속성
| 이름: | hanging-punctuation |
|---|---|
| 값: | none | [ first || [ force-end | allow-end ] || last ] |
| 초기값: | none |
| 적용 대상: | 텍스트 |
| 상속 여부: | 예 |
| 백분율: | 해당 없음 |
| 계산된 값: | 지정된 키워드 |
| 정규 순서: | 문법 기준 |
| 애니메이션 타입: | 불연속 |
이 속성은 문장부호가 있을 경우, 줄 시작 또는 끝에서 행잉되어 줄박스 바깥(혹은 들여쓰기 영역)에 배치될 수 있는지 결정합니다.
참고: 블록 컨테이너에 충분한 패딩이 없으면 hanging-punctuation이 오버플로우를 유발할 수 있습니다.
값의 의미는 다음과 같습니다:
- none
- 어떤 문장부호도 행잉되지 않습니다.
- first
- 요소의 첫 형식화 줄 시작에 괄호, 인용부호, 한자 공백이 있으면 행잉됩니다. 이때 유니코드 범주 Ps, Pf, Pi 및 ASCII 인용부호 U+0027 ' APOSTROPHE, U+0022 " QUOTATION MARK, 한자 공백 U+3000이 대상입니다.
- last
- 요소의 마지막 형식화 줄 끝에 괄호 또는 인용부호가 있으면 행잉됩니다. 이때 유니코드 범주 Pe, Pf, Pi 및 ASCII 인용부호 U+0027 ' APOSTROPHE, U+0022 " QUOTATION MARK이 대상입니다.
- force-end
- 줄 끝에 마침표 또는 쉼표가 있으면 행잉됩니다.
- allow-end
- 줄 끝에 마침표 또는 쉼표가 있으면 조건부 행잉됩니다.
각 줄 엣지에 최대 한 개 문장부호만 행잉될 수 있습니다.
마침표 및 쉼표는 행잉될 수 있는 문자로:
| U+002C | , | 쉼표(COMMA) |
| U+002E | . | 마침표(FULL STOP) |
| U+060C | ، | 아랍 쉼표(ARABIC COMMA) |
| U+06D4 | ۔ | 아랍 마침표(ARABIC FULL STOP) |
| U+3001 | 、 | 한자 쉼표(IDEOGRAPHIC COMMA) |
| U+3002 | 。 | 한자 마침표(IDEOGRAPHIC FULL STOP) |
| U+FF0C | , | 전각 쉼표(FULLWIDTH COMMA) |
| U+FF0E | . | 전각 마침표(FULLWIDTH FULL STOP) |
| U+FE50 | ﹐ | 소 쉼표(SMALL COMMA) |
| U+FE51 | ﹑ | 소 한자 쉼표(SMALL IDEOGRAPHIC COMMA) |
| U+FE52 | ﹒ | 소 마침표(SMALL FULL STOP) |
| U+FF61 | 。 | 반각 한자 마침표(HALFWIDTH IDEOGRAPHIC FULL STOP) |
| U+FF64 | 、 | 반각 한자 쉼표(HALFWIDTH IDEOGRAPHIC COMMA) |
UA는 필요에 따라 다른 문자도 포함할 수 있습니다.
참고: CSS 워킹 그룹은 UA가 추가 문자를 포함할 경우 워킹그룹에 알려주길 바랍니다.

p{ text-align : justify; hanging-punctuation : allow-end; }

p{ text-align : justify; hanging-punctuation : force-end; }
allow-end의 첫 줄 끝 문장부호는 행잉되지 않는데, 행잉 없이 들어가기 때문입니다. 반면 force-end를 사용하면 행잉이 강제됩니다. 자간 정렬은 행잉 문장부호를 뺀 줄을 측정하며, 줄이 늘어날 때 문장부호가 줄 바깥으로 밀려납니다.
9.3. 양방향성과 줄박스
줄박스의 start 및 end 측은 줄박스의 인라인 기준 방향에 따라 결정됩니다. 보통은 일치하지만, 줄박스의 인라인 기준 방향은 포함 블록이나 양방향 문단의 인라인 기준 방향과는 다릅니다. 줄박스의 인라인 기준 방향은 text-align-all, text-align-last, text-indent, hanging-punctuation 등 줄박스 엣지 기준 위치 및 정렬에 영향을 줍니다. 인라인 콘텐츠의 포맷이나 순서에는 영향이 없으며 (이는 유니코드 양방향 알고리즘과 CSS Writing Modes에 의해 제어됨 [UAX9] [CSS-WRITING-MODES-4]).
대부분의 경우, 줄박스의 인라인 기준 방향은 포함 블록의 계산된 direction 속성에 의해 결정됩니다. 하지만, 포함 블록이 unicode-bidi: plaintext일 경우 [CSS-WRITING-MODES-4]:
- 양방향 문단에 속하는 줄박스 (즉, 줄박스가 콘텐츠를 가지는 양방향 문단)가 강한 방향성을 가지면, 줄박스의 인라인 기준 방향은 그 방향성을 따릅니다.
- 줄박스가 비어 있거나 (즉, 원자 인라인이나 줄바꿈 문자 외 다른 문자를 포함하지 않음) 또는 강한 방향성이 없을 경우 (약한/중립 문자만 포함), 인라인 기준 방향은 직전 줄박스(있으면)에서 가져오고, 포함 블록의 첫 줄박스라면 포함 블록의 direction 속성에서 가져옵니다. (이로 인해 RTL 줄박스의 콘텐츠가 LTR 기준 방향을 가지게 될 수 있음)
<block>이 시작 정렬된 서식 있는 블록
(display: block; white-space: pre; text-align: start)이라면
한 줄씩 번갈아 오른쪽 정렬됩니다:
< block style = "unicode-bidi: plaintext" > français فارسی français فارسی français فارسی</ block >
< para style = "display: block; direction: rtl; unicode-bidi:plaintext" > “< quote style = "unicode-bidi:plaintext" > שלום!</ quote > ”, they said.</ para >
< textarea style = "direction: rtl; unicode-bidi:plaintext" > Hello!</ textarea >
unicode-bidi: plaintext 때문에, “Hello!”는 LTR로 조판됨 (즉, 느낌표가 오른쪽에 오고) 왼쪽 정렬됩니다. 포함 블록의 RTL direction은 무시됩니다. 그 뒤 빈 줄도 LTR이 되어, 해당 줄의 캐럿도 왼쪽 엣지에 나타나야 합니다. 단, 첫 빈 줄은 직전 줄이 없으므로 포함 블록의 RTL 방향을 가져와 오른쪽 정렬입니다.
부록 A: 텍스트 처리 작업 순서
이 부록은 규범적입니다.
아래 목록은 텍스트 작업 순서를 정의합니다. (결과 레이아웃만 같으면 구현이 반드시 이 순서를 따라야 하는 것은 아닙니다.)
- § 4.2 공백 트리밍: white-space-trim 속성
- 공백 처리 1단계(줄바꿈 전)
- § 2.2 단어 사이 확장: word-space-transform 속성 및 텍스트 변환
- 텍스트 결합 [CSS-WRITING-MODES-4]
- 텍스트 방향 [CSS-WRITING-MODES-4]
- 텍스트 줄바꿈 (줄마다 적용):
- 자간 정렬 (글리프 선택/텍스트 줄바꿈에 영향 줄 수 있음, 해당 단계로 다시 반복)
- 텍스트 정렬
- 텍스트 그룹 정렬
부록 B: 플레인텍스트로 변환
이 부록은 플레인텍스트 복사/붙여넣기 작업에 대해 규범적입니다.
CSS로 렌더링된 문서가 플레인텍스트로 변환될 때, 예상되는 동작은 다음과 같습니다:
- text-transform 속성은 효과가 없음.
- white-space-trim 및 § 4.3.1 1단계: 공백 병합 및 변환이 적용되고, 병합 가능한 공백 시퀀스가 블록의 시작이나 강제 줄바꿈 직후에 나오면 제거됨.
부록 C: 기본 UA 스타일시트
이 부록은 참고용이며, UA 개발자가 HTML의 기본 스타일시트를 구현하는 데 참고를 위해 제공됩니다. UA 개발자는 필요에 따라 자유롭게 무시하거나 수정할 수 있습니다.
/* option 요소 정렬 일치 */ option{ text-align : match-parent; } /* textarea 내 공백 병합 금지 */ textarea{ white-space-collapse : preserve !important; } /* 서식 있는 텍스트에서 문자 격자 보존 */ pre, code, kbd, samp, tt{ text-spacing : none; } /* 서식 있는 블록에 행잉 문장부호 상속 금지 */ pre{ hanging-punctuation : none; }
부록 D: 문자체계와 간격
이 부록은 규범적입니다.
조판 동작은 언어마다 다소 다르지만, 문자체계마다 매우 크게 다릅니다. 이 부록은 유니코드 6.0의 일부 일반 문자체계를 자간 정렬 및 간격 동작에 따라 분류합니다. 카테고리 설명은 기술적 정의가 아니며, 결정 기준은 자간 조정 기회의 우선순위입니다.
- 블록 문자체계
- CJK 및 확장된 Wide 문자
(동아시아 폭 [UAX11] 참고).
포함되는 유니코드 문자체계:
보포모포, 한자, 한글, 히라가나, 가타카나, 이.
East
Asian Width property가
Wide또는Fullwidth인 문자도 포함,Ambiguous문자는 문자체계가 중국어, 한국어, 일본어일 때만 포함. - 클러스터 문자체계
- 클러스터 문자체계는 개별 단위가 있고, 단어 경계에서만 끊기며, 가시적 단어 구분 기호는 사용하지 않습니다. 스페이스 신장 우선이지만, 자간 정렬을 위해 문자 사이 간격도 잘 받아들입니다. 해당 문자체계에는 다음 유니코드 문자체계 포함: 크메르, 라오, 미얀마, 뉴 타이 루에, 타이 레, 타이 탐, 타이 비엣, 태국어
- 필기체 문자체계
-
필기체 문자체계는 자간 정렬이나 letter-spacing 모두
글자 사이에 간격을 허용하지 않습니다.
포함되는 유니코드 문자체계:
아랍어,
하나피 로힝야,
만다이크,
몽골,
은코,
팍스파,
시리아어
참고: 베이스라인 연결이 있는 인도 문자체계(데바나가리, 구자라트어 등)는 필기체 문자체계가 아니며, 글자 사이에 간격을 허용합니다 (조판 문자 단위 사이). 인도 레이아웃 요구사항 [ILREQ] 참고.
UA는 유니코드 지원을 업데이트할 때 앞으로 유니코드에 새로 인코딩될 필기체 문자체계도 처리할 수 있도록 이 목록도 업데이트해야 하며, CSSWG에 명세 업데이트를 요청하는 것도 권장합니다.
부록 E: 문자 및 속성
이 부록은 규범적입니다.
유니코드는 CSS 조판에서 참조되는 네 가지 코드포인트 수준 속성을 정의합니다:
- 동아시아 폭 속성
- Unicode Standard Annex #11 [UAX11]에서 정의되며,
Unicode Character Database [UAX44]에서
East_Asian_Width속성으로 제공됩니다. - 일반 범주
- Unicode Standard Annex #44 [UAX44]에서 정의되며,
Unicode Character Database [UAX44]에서
General_Category속성으로 제공됩니다. - 스크립트 속성
- Unicode Standard Annex #24 [UAX24]에서 정의되며,
Unicode Character Database [UAX44]에서
Script속성으로 제공됨. (UA는 이 매핑에 ScriptExtensions.txt 지정도 반드시 포함해야 합니다.) - 세로 방향 속성
- Unicode Standard Annex #50 [UAX50]에서 정의되며, Unicode Character Database [UAX44]에서 Vertical_Orientation 속성으로 제공됨.
유니코드는 개별 코드포인트에 대한 속성을 정의하지만, 때로는 조판 문자 단위의 속성을 결정해야 할 때가 있습니다. 현행 표준에서, 조판 문자 단위의 속성은 첫 grapheme cluster의 기본 문자로 결정됩니다. 단, 두 가지 예외가 있습니다:
- Enclosing Mark
(
Me) 및 Common script로 형성된 grapheme cluster는 Other Symbols(So)이며 Common script로 간주됩니다. 이들은 U+FFFD 대체 문자와 동일한 Unicode 속성을 가진 것으로 처리합니다. - Space Separator
(
Zs) 를 기본으로 하는 grapheme cluster는 Modifier Symbols(Sk)로 간주됩니다. 이들은 기본 문자와 동일한 동아시아 폭 속성을 가지지만, 나머지 속성은 시퀀스의 첫 결합 문자에서 가져옵니다.
부록 F: 콘텐츠 문자체계 식별
이 부록은 규범적입니다.
대부분의 언어는 선호하는 문자체계를 가지지만,
일부는 복수 문자체계를 사용할 수 있고,
대부분은 하나 이상의 외국 문자체계로 전사될 수도 있습니다.
예를 들어, 대부분의 언어는 최소 하나의 라틴 전사체를 가지며,
라틴 문자체계로 쓸 수 있습니다.
전사된 텍스트는 보통 해당 문자체계의 조판 관례를 따릅니다:
예를 들어 일본어 ‘로마지’와 중국어 병음은 라틴 문자와 단어 공백을 사용하며,
라틴 줄바꿈 및 자간 정렬 관례를 따릅니다.
또 다른 예로, 역사적 한자 기반 한국어(ko-Hani)는 단어 공백을 사용하지 않으며,
현대 한국어보다 중국어와 유사하게 조판해야 합니다.
HTML 또는 문서 언어에서 BCP47 태그로 언어를 식별해 콘텐츠 언어를 선언할 때,
저자는 script 서브태그로 비정형 문자체계 사용을 명확히 할 수 있습니다. [BCP47] 예를 들어,
라틴 문자체계를 사용하는 언어를 표시하려면 -Latn script 서브태그를 추가할 수 있습니다.
예: 일본어 로마지의 경우 ja-Latn.
기타 서브태그는 ISO의 Code for the Representation of Names of Scripts 및 ISO15924 script tag registry에서 확인하세요. [ISO15924]
zh-Latn- 중국어 라틴 전사.
ko-Hani- 한자(중국어 한자)로 쓴 한국어.
tr-Arab- 아랍 문자로 쓴 터키어.
mn-Cyrl- 키릴 문자로 쓴 몽골어.
mn-Mong- 전통 몽골 문자로 쓴 몽골어.
단, BCP47 스크립트 서브태그는
한 문자체계와 강하게 연관된 언어에는 일반적으로 사용하지 않으며,
실제로는 권장하지 않습니다.
대신 특정 문자체계가 별도 지정되지 않은 경우 암묵적으로 그 문자체계를 사용한다고 간주합니다. [BCP47] IANA는 Suppress-Script 필드로
language subtag
registry에서 각 언어의 가장 흔한 문자체계 정보를 관리합니다.
참고: 언어 태그 관련 추가 조언은 국제화 워킹 그룹의 HTML/XML의 언어 태그 및 언어 태그 선택에서 확인할 수 있습니다.
문자체계가 명시적으로 표시되지 않은 경우, UA는 선언된 콘텐츠 언어의 가장 흔한 문자체계를 라인 브레이크·자간 정렬 등 언어 민감 조판 동작에 사용해야 합니다. 단, 저자가 다른 문자체계를 명시적으로 선언한 경우에는 해당 문자체계를 반드시 사용해야 합니다. UA가 특정 언어/문자체계 조합에 대한 언어별 지식이 없는 경우에는, 선언된 문자체계의 조판 관례(필요 시 다른 언어의 관례)를 사용해야 하며, 선언된 언어의 암시적 문자체계 조판 관례를 사용하면 안 됩니다.
언어와 가장 흔한 문자체계의 전체 대응은 이 문서 범위를 벗어납니다. 단, UA는 아래는 최소한 가정해야 합니다:
- 콘텐츠 언어가 중국어이고 문자체계가 지정되지 않았거나, 콘텐츠 언어가 있고 문자체계가 Hant, Hans, Hani, Hanb, Bopo ISO script 코드 중 하나로 지정된 경우, 문자체계는 중국어임.
- 콘텐츠 언어가 일본어이고 문자체계가 지정되지 않았거나, 콘텐츠 언어가 있고 문자체계가 Jpan, Hrkt, Hira, Kana ISO script 코드 중 하나로 지정된 경우, 문자체계는 일본어임.
- 콘텐츠 언어가 한국어이고 문자체계가 지정되지 않았거나, 콘텐츠 언어가 있고 문자체계가 Kore, Hang, Jamo ISO script 코드 중 하나로 지정된 경우, 문자체계는 한국어임.
-
문자체계는
알 수 없음으로 간주되는 경우는
콘텐츠 언어 자체가 알 수 없거나,
명시적으로 알 수 없는 문자체계를 표시한 경우뿐입니다.
참고: 문자체계 정보를 단순히 생략하고 콘텐츠 언어를 선언했다면 문자체계는 암묵적으로 지정된 것이지, 알 수 없는 것이 아닙니다.
부록 G: 소형 가나 매핑
이 부록은 규범적입니다.
| 소형 | 전각 |
|---|---|
| ぁ U+3041 | あ U+3042 |
| ぃ U+3043 | い U+3044 |
| ぅ U+3045 | う U+3046 |
| ぇ U+3047 | え U+3048 |
| ぉ U+3049 | お U+304A |
| ゕ U+3095 | か U+304B |
| ゖ U+3096 | け U+3051 |
| 𛄲 U+1B132 | こ U+3053 |
| っ U+3063 | つ U+3064 |
| ゃ U+3083 | や U+3084 |
| ゅ U+3085 | ゆ U+3086 |
| ょ U+3087 | よ U+3088 |
| ゎ U+308E | わ U+308F |
| 𛅐 U+1B150 | ゐ U+3090 |
| 𛅑 U+1B151 | ゑ U+3091 |
| 𛅒 U+1B152 | を U+3092 |
| ァ U+30A1 | ア U+30A2 |
| ィ U+30A3 | イ U+30A4 |
| ゥ U+30A5 | ウ U+30A6 |
| ェ U+30A7 | エ U+30A8 |
| ォ U+30A9 | オ U+30AA |
| ヵ U+30F5 | カ U+30AB |
| ㇰ U+31F0 | ク U+30AF |
| ヶ U+30F6 | ケ U+30B1 |
| 𛅕 U+1B155 | コ U+30B3 |
| ㇱ U+31F1 | シ U+30B7 |
| ㇲ U+31F2 | ス U+30B9 |
| ッ U+30C3 | ツ U+30C4 |
| ㇳ U+31F3 | ト U+30C8 |
| ㇴ U+31F4 | ヌ U+30CC |
| ㇵ U+31F5 | ハ U+30CF |
| ㇶ U+31F6 | ヒ U+30D2 |
| ㇷ U+31F7 | フ U+30D5 |
| ㇸ U+31F8 | ヘ U+30D8 |
| ㇹ U+31F9 | ホ U+30DB |
| ㇺ U+31FA | ム U+30E0 |
| ャ U+30E3 | ヤ U+30E4 |
| ュ U+30E5 | ユ U+30E6 |
| ョ U+30E7 | ヨ U+30E8 |
| ㇻ U+31FB | ラ U+30E9 |
| ㇼ U+31FC | リ U+30EA |
| ㇽ U+31FD | ル U+30EB |
| ㇾ U+31FE | レ U+30EC |
| ㇿ U+31FF | ロ U+30ED |
| ヮ U+30EE | ワ U+30EF |
| 𛅤 U+1B164 | ヰ U+30F0 |
| 𛅥 U+1B165 | ヱ U+30F1 |
| 𛅦 U+1B166 | ヲ U+30F2 |
| 𛅧 U+1B167 | ン U+30F3 |
| ァ U+FF67 | ア U+FF71 |
| ィ U+FF68 | イ U+FF72 |
| ゥ U+FF69 | ウ U+FF73 |
| ェ U+FF6A | エ U+FF74 |
| ォ U+FF6B | オ U+FF75 |
| ッ U+FF6F | ツ U+FF82 |
| ャ U+FF6C | ヤ U+FF94 |
| ュ U+FF6D | ユ U+FF95 |
| ョ U+FF6E | ヨ U+FF96 |
부록 H: 단어·구 검출
이 부록은 규범적입니다.
이 명세의 일부 작업은 자동 단어 경계 검출 또는 구 경계 검출에 의존합니다.
두 작업 모두 유사하며, UA가 텍스트 언어적 분석을 통해 언어별 의미 있는 문자 시퀀스를 식별합니다. 단, 단어와 구 각각 다른 텍스트 단위에 적용됩니다.
일반적으로는 쉽게 이해되지만, 단어와 구 개념 모두 여러 언어에서 정확한 정의가 어렵습니다. 하지만 이 맥락에서:
-
단어란 하나 이상의 문자 또는 음절로 구성될 수 있는 인지 가능한 의미 단위입니다.
참고: 이 개념 논의는 What is a word? 참고.
-
구란 하나 또는 복수의 단어가 개념적·문법적 단위로 함께 그룹화된 짧은 덩어리로,
절이나 문장의 구성 요소를 이룹니다.
참고: 여기서 말하는 phrase는 프랑스어 phrase(문장)와 다르니 혼동 주의. 일본어에서는 文節(문절) 개념에 대응합니다.
검출된 각 단어·구의 시작과 끝 위치를 단어 경계 또는 구 경계라고 합니다. 단어·구 경계 자체는 관찰할 수 없지만, word-space-transform 또는 word-break 등 속성에서 해당 위치에 가시적 효과가 나타날 수 있습니다.
단어·구 검출 및 경계 배치 알고리즘은 UA에 따라 다르며, 사전 기반 형태소 분석, 문장부호/구분 문자 인식, 형태소 분석, 머신러닝 등 다양한 요인을 고려할 수 있습니다.
단, 아래 제약은 반드시 지켜야 합니다:
- UA는 하나의 조판 문자 단위를 구성하는 문자 사이에 단어/구 경계를 배치하면 안 됩니다.
- UA는 줄바꿈 클래스 GL, WJ, ZWJ 문자가 인접한 곳에는 단어/구 경계를 배치하면 안 되며, 두 단어/구가 해당 문자로 분리된 경우 하나로 취급해야 합니다. [UAX14]
- 단어/구 바로 뒤에 아래 문자가 오면, UA는 반드시 해당 문자를 앞 단어/구의 일부로 간주해야 합니다:
-
문장부호는 구 자체가 아니며, 인접한 단어/구의 관련 측에 부착되어야 합니다. 예를 들어, 괄호·인용부호 등 닫는/여는 문장부호는 감싸는 구의 일부이고, 쉼표·세미콜론 등은 앞 구에 붙으며, U+00BF 역물음표는 다음 단어에 부착됩니다 등.
단, 스마일리·카오모지·펄 코드 등 비정형 문장부호 사용은 UA가 원칙을 벗어나 처리할 수도 있습니다.
-
인라인 박스 경계 및 flow 밖 요소는 단어/구 경계 판단 시 무시해야 합니다.
단,
단어 경계 또는 구 경계가
인라인 박스 경계와 같은 위치에 있으면,
단어 또는 구 경계는
해당 인라인 박스 경계에 참여하는 가장 바깥쪽 요소에 삽입해야 합니다.
아래 예시에서 빨간 “
|”는 UA가 단어 경계 검출 시 적합한 경계 위치를 의미합니다:กรุงเทพ|คือ|สวยงาม해당 문장에 인라인 마크업이 있는 경우, 아래가 올바른 경계 위치 예시입니다:
กรุงเทพ|คือ|< em > สวยงาม</ em > 아래는 잘못된 경계 위치 예시입니다:
กรุงเทพ|คือ< em > |สวยงาม</ em > 좀 더 복잡한 상황에서의 올바른 경계 위치:
กรุงเทพ|< b >< u > คือ</ u > |< em > สวยงาม</ em ></ b >
보안 고려사항
이 현행 표준은 새로운 보안 고려사항을 도입하지 않습니다.
개인정보 보호 고려사항
이 현행 표준은 사용자의 설치된 하이픈 및 줄바꿈 사전을 노출합니다.
감사의 글
이 현행 표준은 다음 분들의 도움 없이는 불가능했을 것입니다: Addison Phillips, Aharon Lanin, Alan Stearns, Ambrose Li, Arnold Schrijver, Arye Gittelman, Ayman Aldahleh, Ben Errez, Bert Bos, Chris Lilley, Chris Pratley, Chris Thrasher, Chris Wilson, Dave Hyatt, David Baron, Emilio Cobos Álvarez, Eric LeVine, Etan Wexler, Frank Tang, Håkon Wium Lie, IM Mincheol, Ian Hickson, James Clark, Javier Fernandez, John Daggett, Jonathan Kew, Ken Lunde, Laurie Anna Edlund, Marcin Sawicki, Martin Dürst, Martin Heijdra, Masafumi Yabe, Masayasu Ishikawa, Michael Jochimsen, Michel Suignard, Mike Bemford, Myles Maxfield, Nat McCully, Paul Nelson, Pierre-Anthony Lemieux, Rahul Sonnad, Randy Edmunds, Richard Ishida, Shinyu Murakami, Stephen Deach, Steve Zilles, Takao Suzuki, Tantek Çelik, Xidorn Quan, Yaniv Feinberg.
변경 사항
이 초안은 [CSS-TEXT-3]와 동기화되어 유지됩니다. CSS Text 3 §
변경 사항 참조.
Level 4에서의 변경 사항은 아래에 나열되어 있습니다.
2024년 2월 19일 Working Draft 이후 주요 변경 사항:
-
text-spacing-trim 값 trim-auto를 trim-both로 이름 변경. (Issue 10161)
-
text-wrap-style: balance 값에서 많은 줄이 있을 때 줄 바꿈을 변경하지 않는 요구를 완화함. (Issue 10186)
-
text-wrap-style: balance와 line-clamp의 상호작용 정의. (Issue 9310)
-
math-auto 값을 text-transform에 추가. (Issue 5386)
2023년 10월 20일 Working Draft 이후 주요 변경 사항:
-
강제 줄바꿈 이후 각 줄에 대해 text-spacing-trim: space-first 정의에서 삭제된 부분 복구. (Issue 9532)
-
normal을 text-spacing-trim의 초기값으로 지정. (Issue 9511)
-
space-first의 줄 끝 동작 변경. (Issue 9736)
-
space-first가 줄바꿈 이후에도 적용됨. (Issue 9532)
-
전각 문장부호 병합 세부사항 명확화. (Issue 9225)
-
pre 요소가 기본적으로 행잉 문장부호를 상속받지 않도록 UA 스타일 규칙 추가 제안. (Issue 9689)
2023년 3월 29일 Working Draft 이후 주요 변경 사항:
-
text-wrap 속성을 두 개의 신규 속성 text-wrap-mode와 text-wrap-style 단축형으로 재구성. text-wrap-mode가 text-wrap의 longhand가 됨. white-space 속성의 longhand임.
-
부록 G: 소형 가나 매핑을 Unicode 15.0에 맞게 업데이트. (Issue 8442)
-
word-break: auto-phrase, word-break: manual 기능을 재설계 (이전 독립
word-boundary-detection속성 시도에서), auto-phrase 값을 word-space-transform에 추가(이제word-boundary-detection에 의존하지 않음). 지원 관련 메커니즘도 업데이트. -
word-boundary-expansion을 word-space-transform로 이름 변경 -
trim-all을 text-spacing-trim에 추가. (Issue 8482)
-
NBSP를 제외한 커스터마이즈 불가능한 유니코드 줄바꿈 제어가 원자 인라인 규칙보다 우선하도록 지정. (Issue 8972)
2023년 3월 1일 Working Draft 이후 주요 변경 사항:
-
white-space를 여러 longhand로 분리 작업 완료:
-
break-spaces 값을 white-space-collapse에 추가하여 모든 단축형 값이 longhand로 표현 가능하게 함 (Issue 8256)
-
모든 longhand 키워드를 white-space 단축형에 통합
-
관련 설명 업데이트
-
-
text-space-collapse와 text-space-trim을 각각 white-space-collapse, white-space-trim으로 이름 변경. (Issue 8273)
2022년 12월 31일 Working Draft 이후 주요 변경 사항:
-
text-spacing 재설계:
-
space-first를 초기값으로 설정 (Issue 2462)
-
hanging-punctuation으로 선두 한자 공백 매달림(plaintext 소스 관행 보완용) 가능하게 함 (Issue 2462)
-
no-compress를 text-justify로 이동(간격보다 자간 정렬 제어에 적합). (Issue 7079)
-
text-spacing에서 문맥 문자에 Pe, Ps 범주 문자 포함. (Issue 6091)
-
text-space-collapse를 white-space-collapse로 이름 변경. (Issue 8273)
2022년 5월 5일 Working Draft 이후 주요 변경 사항:
- ruby 값을 text-justify에 추가. (Issue 771 Issue 779)
- text-spacing: normal이 trim-end 대신 allow-end을 사용하도록 변경. (Issue 7055)
- text-spacing: normal이 ideograph-alpha 및 ideograph-numeric에도 적용되도록 변경. UA 기본 스타일시트에서 이 값이 monospace 문맥에서는 제외되도록 업데이트, margin/border/padding이 0이 아니면 간격 삽입 억제, 삽입되는 간격은 0.125ic로 정의. (Issue 6950)
- text-align: match-parent가 start로 계산되도록 root element에서 정의. (Issue 6542)
- distribute 키워드를 레거시 값 별칭으로 처리하거나 inter-character로 바로 계산하도록 허용, 두 방법 모두 역호환에 문제 없음. (Issue 7322)
- trim-inner 값을 white-space-trim에서 discard-inner로 이름 변경하여 일관성 맞춤. (Issue 448)
2019 Working Draft 이후 주요 변경 사항:
- [CSS-TEXT-3] 전체 텍스트 통합.
- word-spacing과 letter-spacing에 백분율 추가(현재 font-size 기준 상대 크기). (Issue 2165)
- UA 규칙 제안:
textarea요소 내 스페이스 병합 금지. (Issue 6309)
Level 3 이후 추가사항
Level 4의 신규 기능:
-
word-break: auto-phrase, 줄바꿈 시 자동으로 구를 감지해 함께 유지
-
word-space-transform, 단어 구분자 변환
-
white-space 속성을 여러 longhand로 분리:
-
white-space-trim, 요소 경계의 불필요 공백 트리밍
-
text-wrap-mode, 줄바꿈 여부 제어
-
text-wrap-style 및 그 balance, stable, pretty 값 추가
-
wrap-before, wrap-after, wrap-inside 추가(페이지네이션용 break-* 속성과 유사)
-
hyphenate-character, 하이픈 문자 직접 제어
-
hyphenate-limit-zone, hyphenate-limit-chars, hyphenate-limit-lines, hyphenate-limit-last 등 하이픈 자동화 제어 기능 추가
-
<string> 값을 text-align에 추가(예: 소수점 정렬)
-
text-group-align 추가(여러 줄박스의 그룹 정렬, text-align 기준)
-
line-padding 추가(줄 시작/끝 인라인 박스 내 공간 삽입)
-
text-spacing 추가(문장부호 및 문자체계 전환 주변 자동 간격)